
1 計算機系統概述
1.1 計算機硬件
1.1.1 馮·諾伊曼機
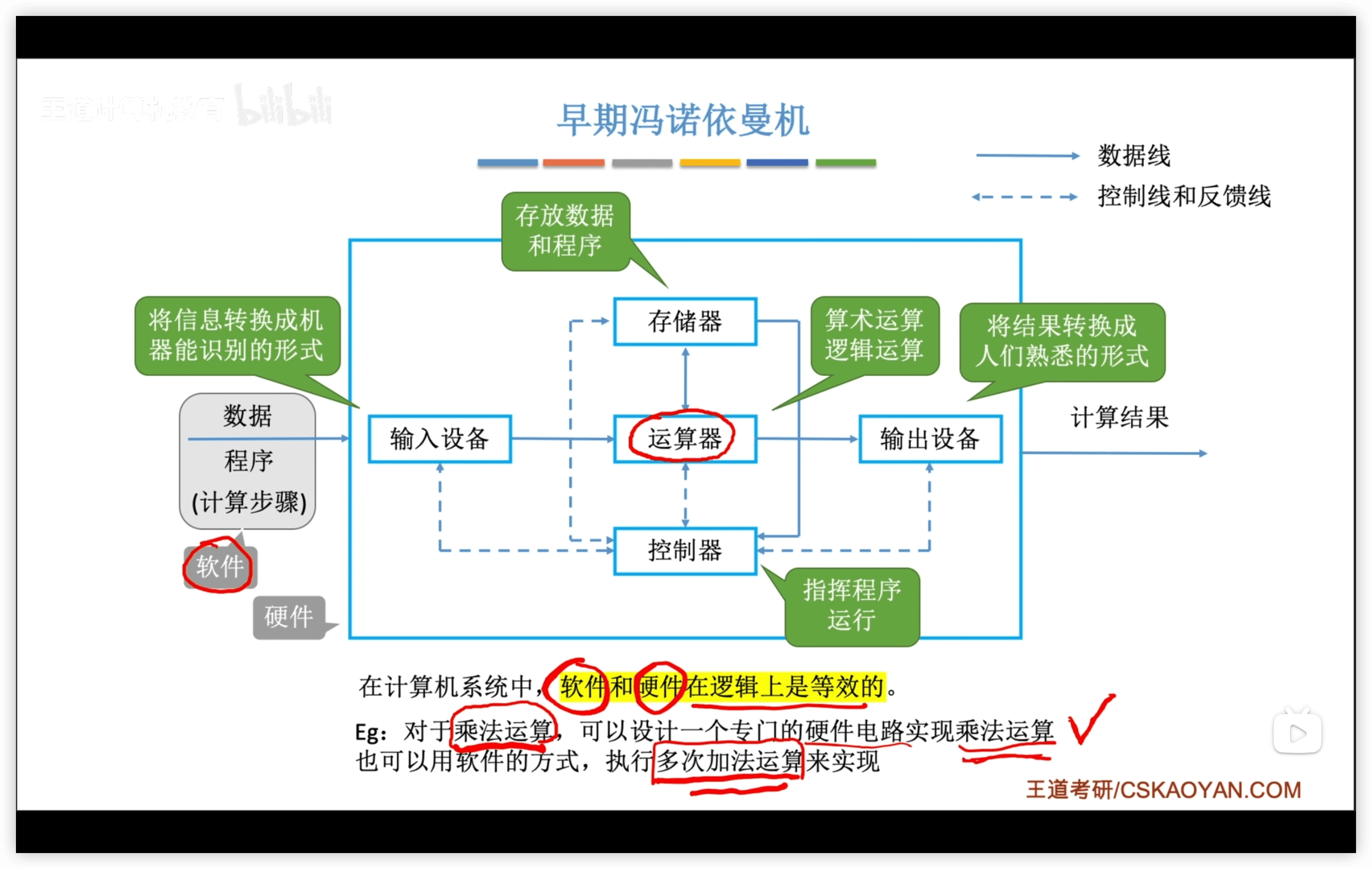
- 軟件和硬件在邏輯上是等效的
馮 · 諾依曼計算機的特點:
- 計算機由 5 大部件組成
- 指令和數據以同等地位存於存儲器,可按地址尋訪
- 指令和數據用二進制表示
- 指令由操作碼和地址碼組成
- 存儲程序:馮·諾伊曼提出的概念
- 以運算器為中心
- 輸入/輸出設備與存儲器之間的數據傳送通過運算器完成
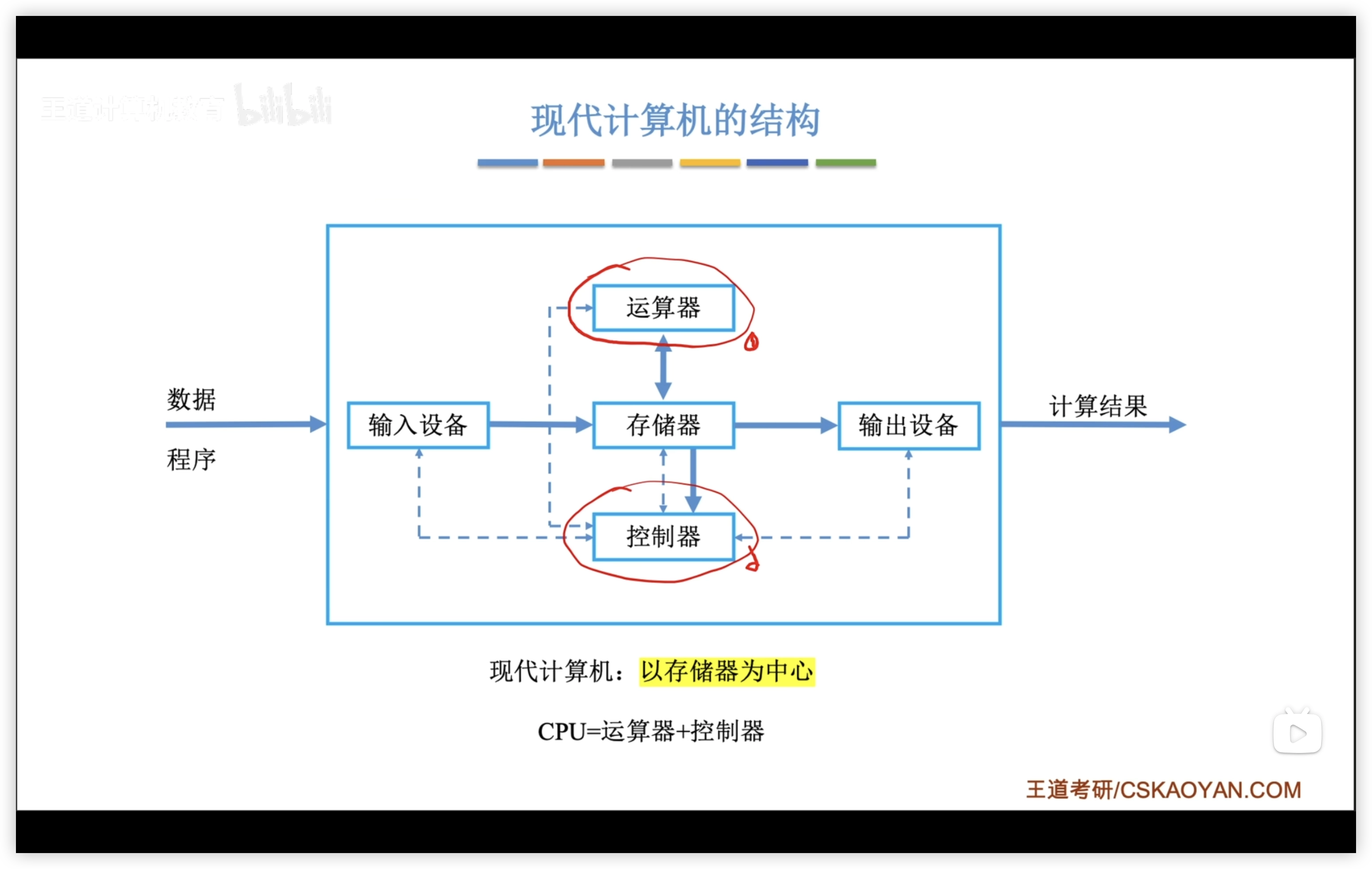
1.1.2 現代計算機
區別:以存儲器為中心
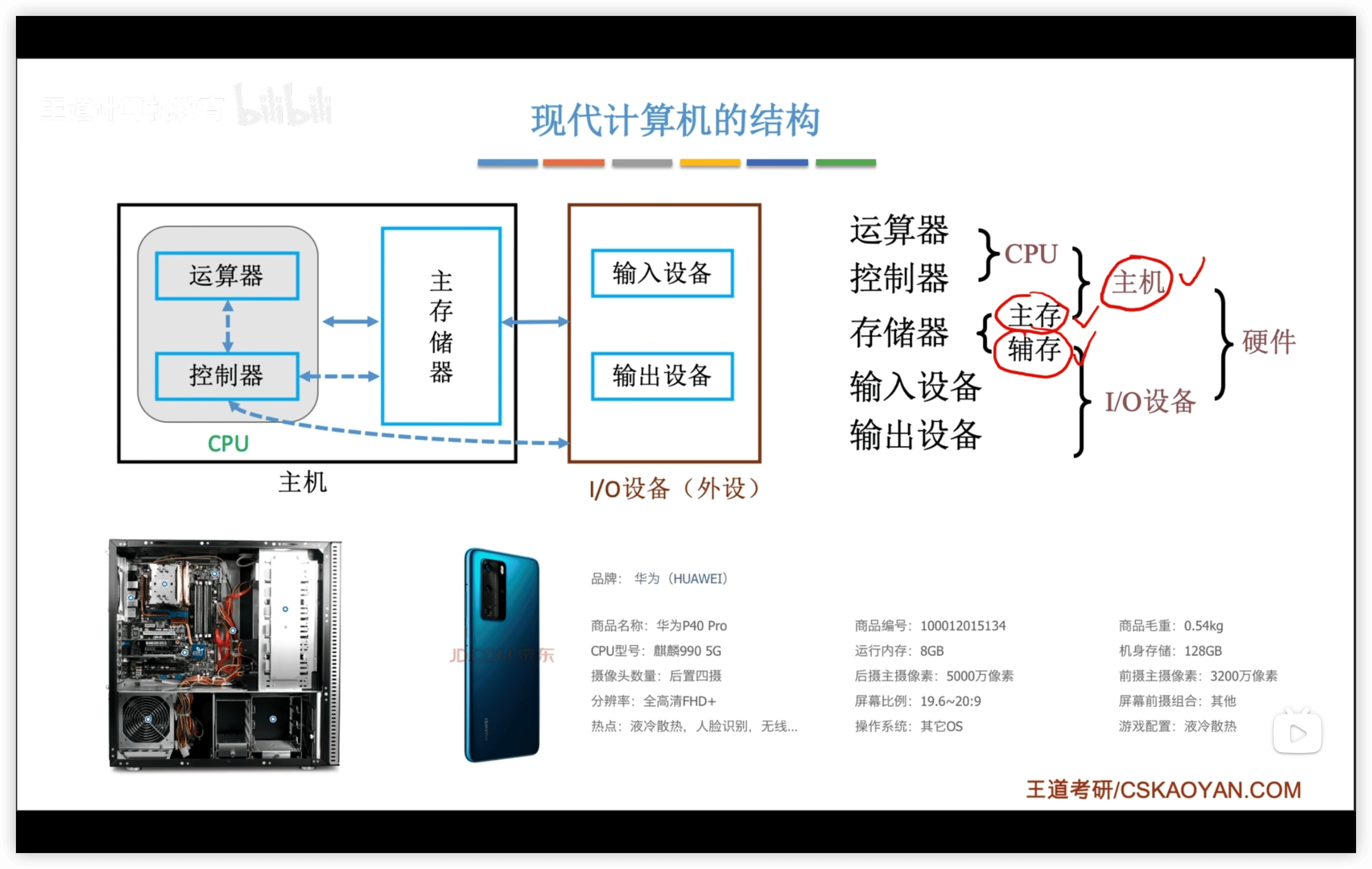
硬件:
- 主機
- CPU
- 運算器
- 控制器
- 存儲器
- 主存
- 輔存(屬於IO設備)
- CPU
- IO設備
- 輸入
- 輸出
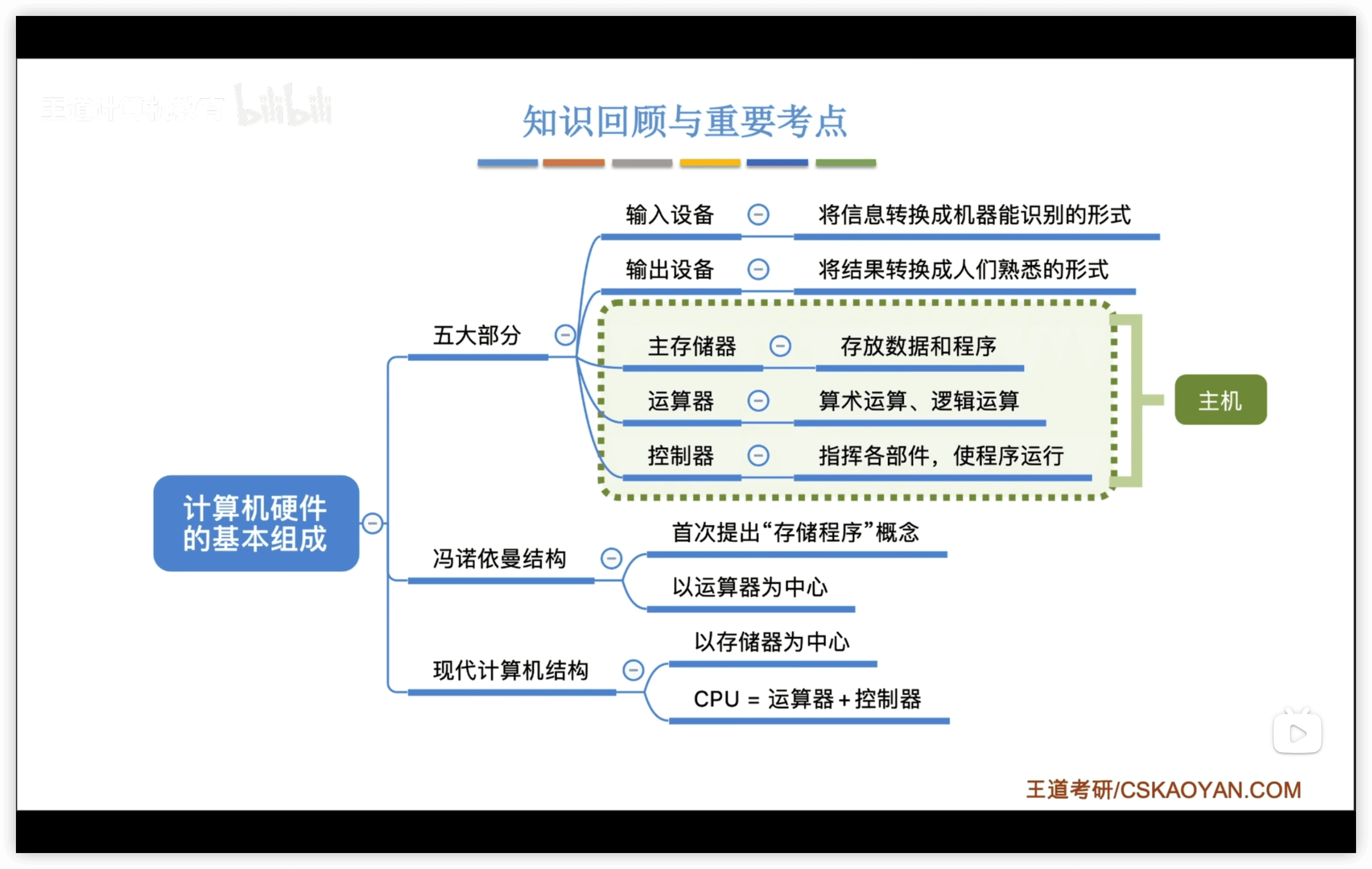
1.2 硬件工作原理
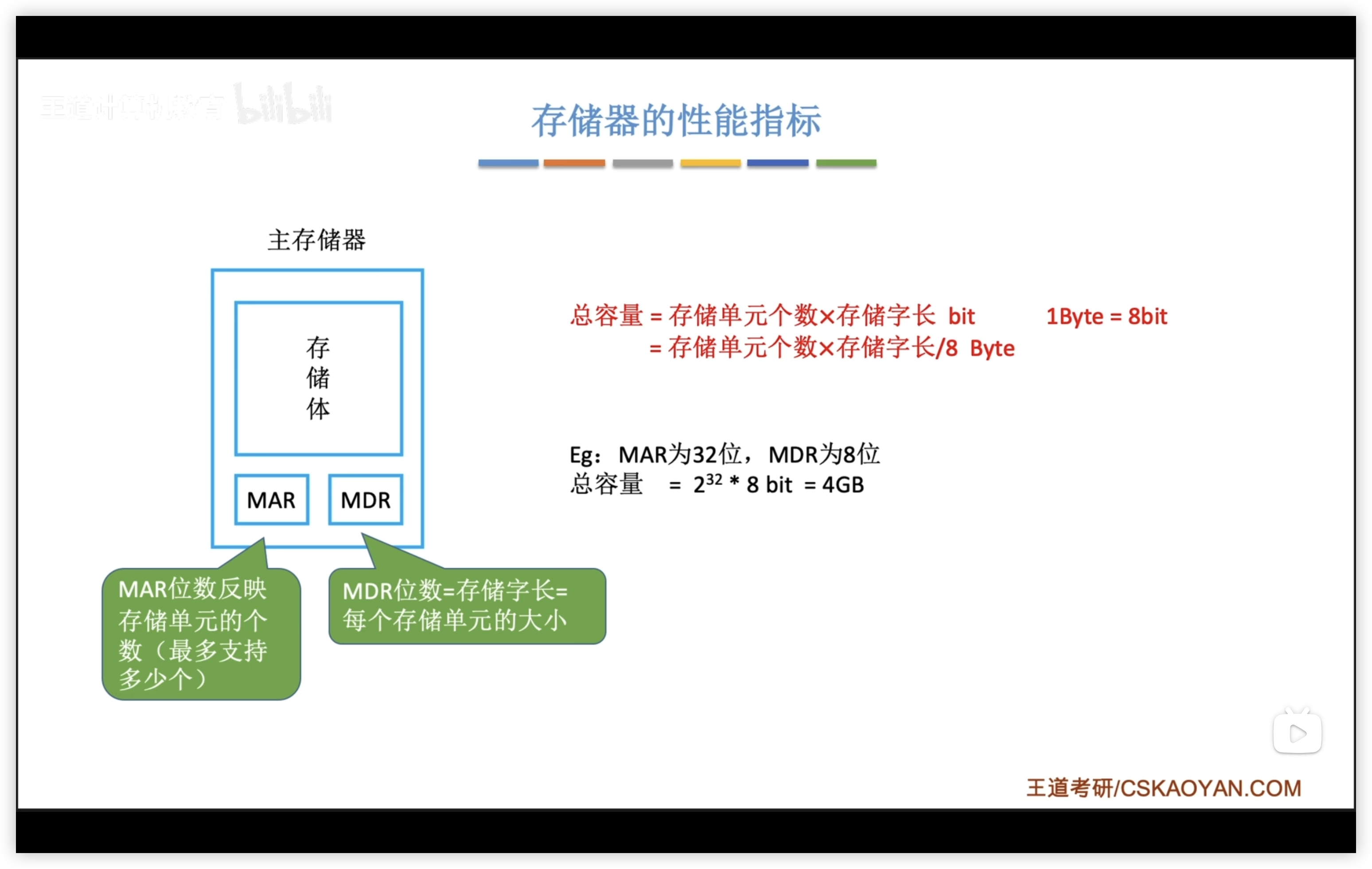
1.2.1 主存儲器
主存儲器:
- 存儲體
- 存儲器地址寄存器 MAR
- 存儲器數據寄存器 MDR
注意,現代計算機的MAR和MDR已集成在CPU中。
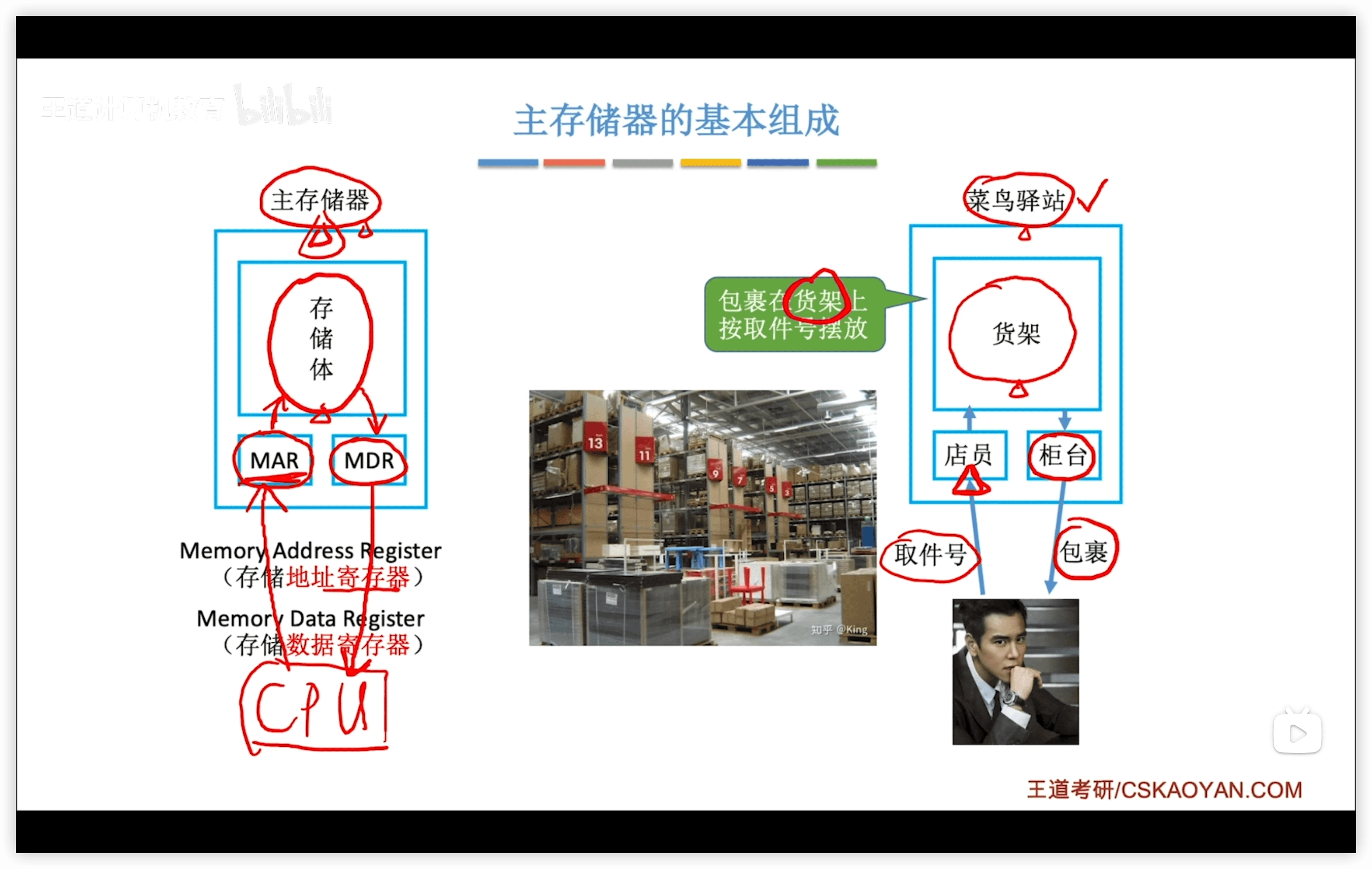
讀取寫入數據的過程類似存取包裹:
- MAR 存放地址:需要讀/取的數據的地址
- MDR 存放數據
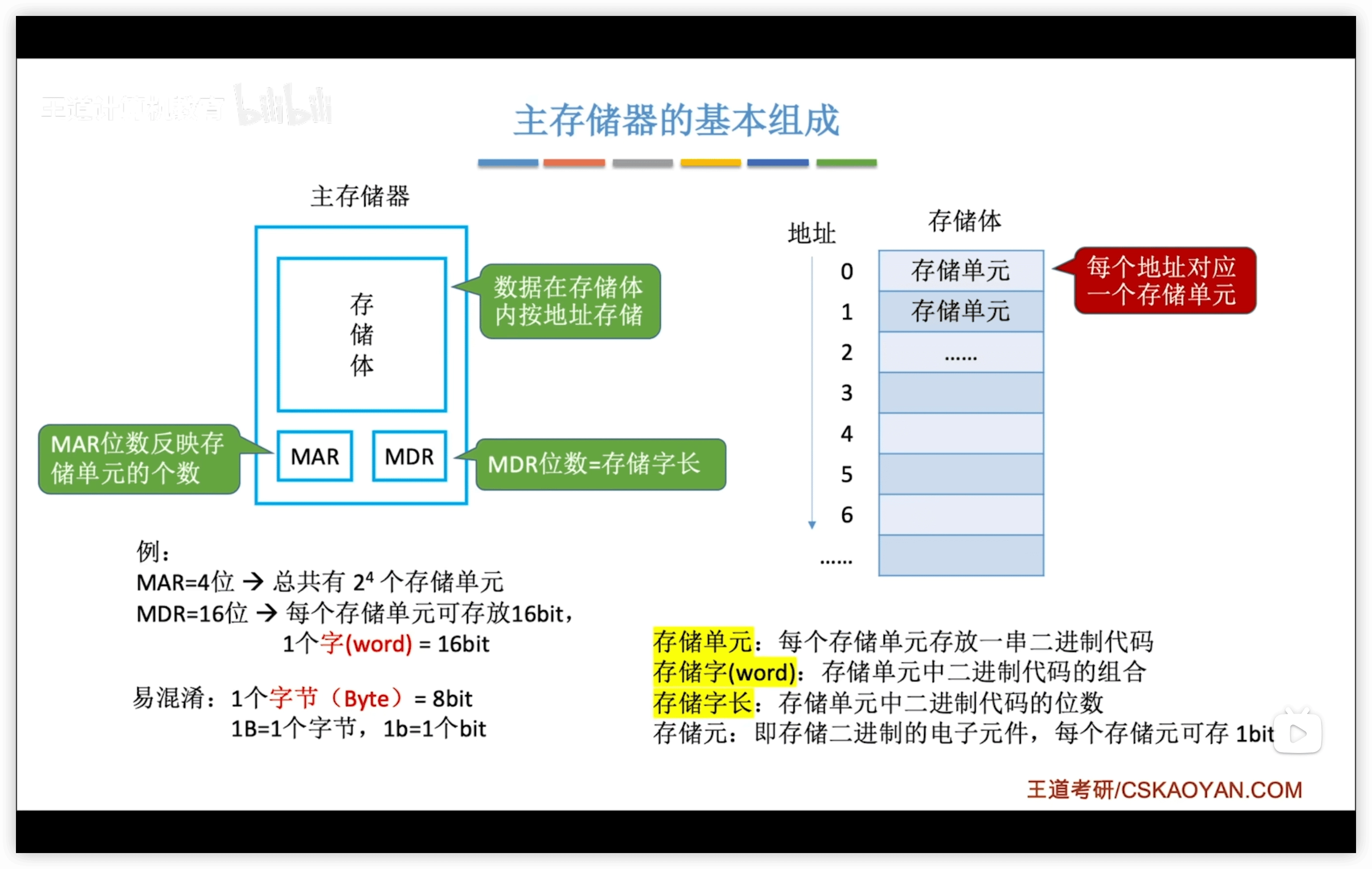
| MAR位數 | MDR位數 |
|---|---|
| 地址碼長度,可算存儲單元個數 | 存儲字長 |
| 4位 = 個存儲單元 | 16位 = 1個存儲單元存放16bit |
注意:
- 字長是可變的,字節是不變的 = 8bit
- MDR規定存儲字長,即規定了1個字=16bit
1.2.2 運算器
運算器由 ALU、移位器、狀態寄存器(PSW)、通用寄存器組 組成。
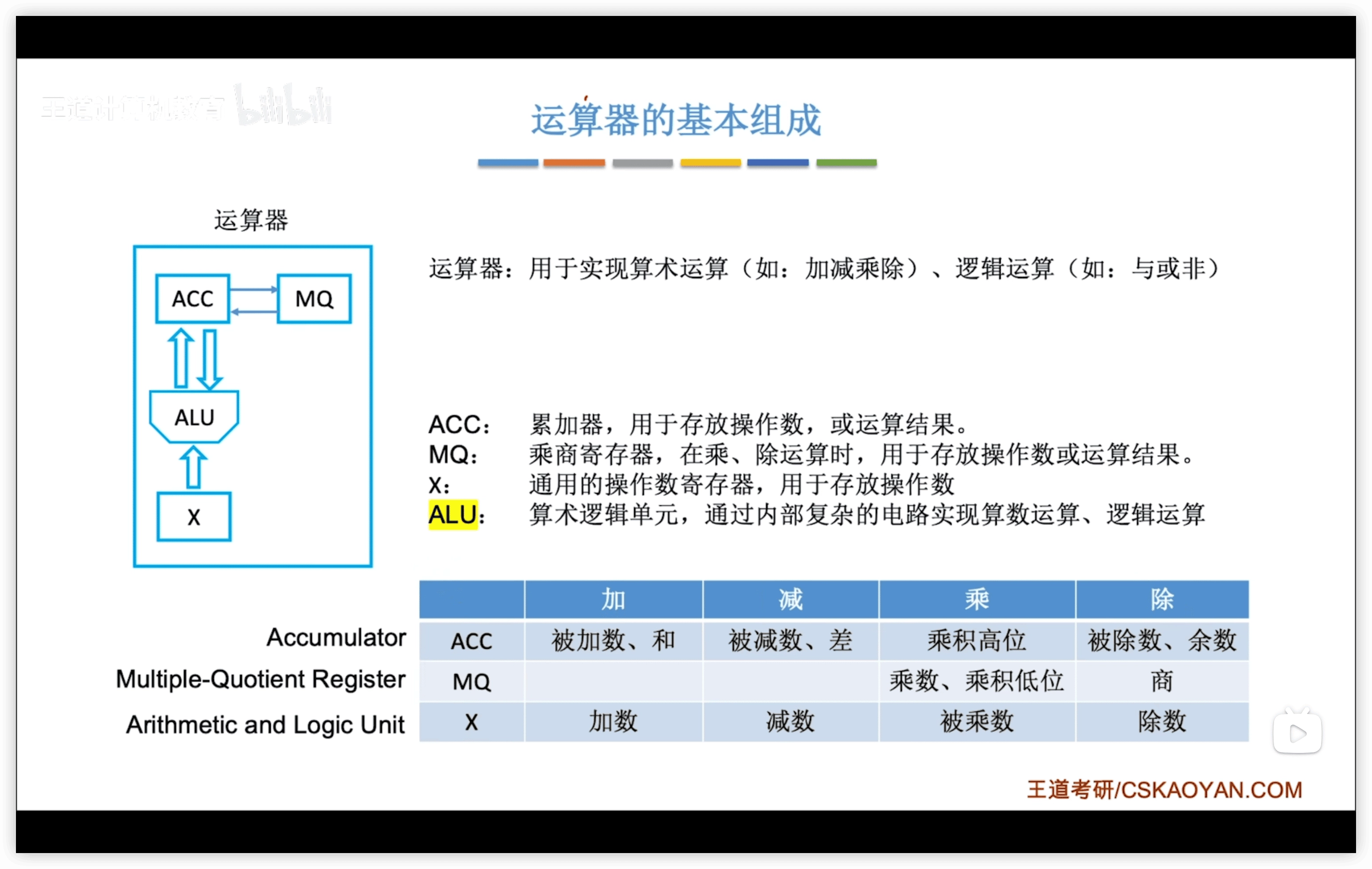
- ALU:算數邏輯單元
- 核心,其他三個只是寄存器
- ACC:累加寄存器
- MQ:乘商寄存器
- X:通用操作數寄存器
1.2.3 控制器
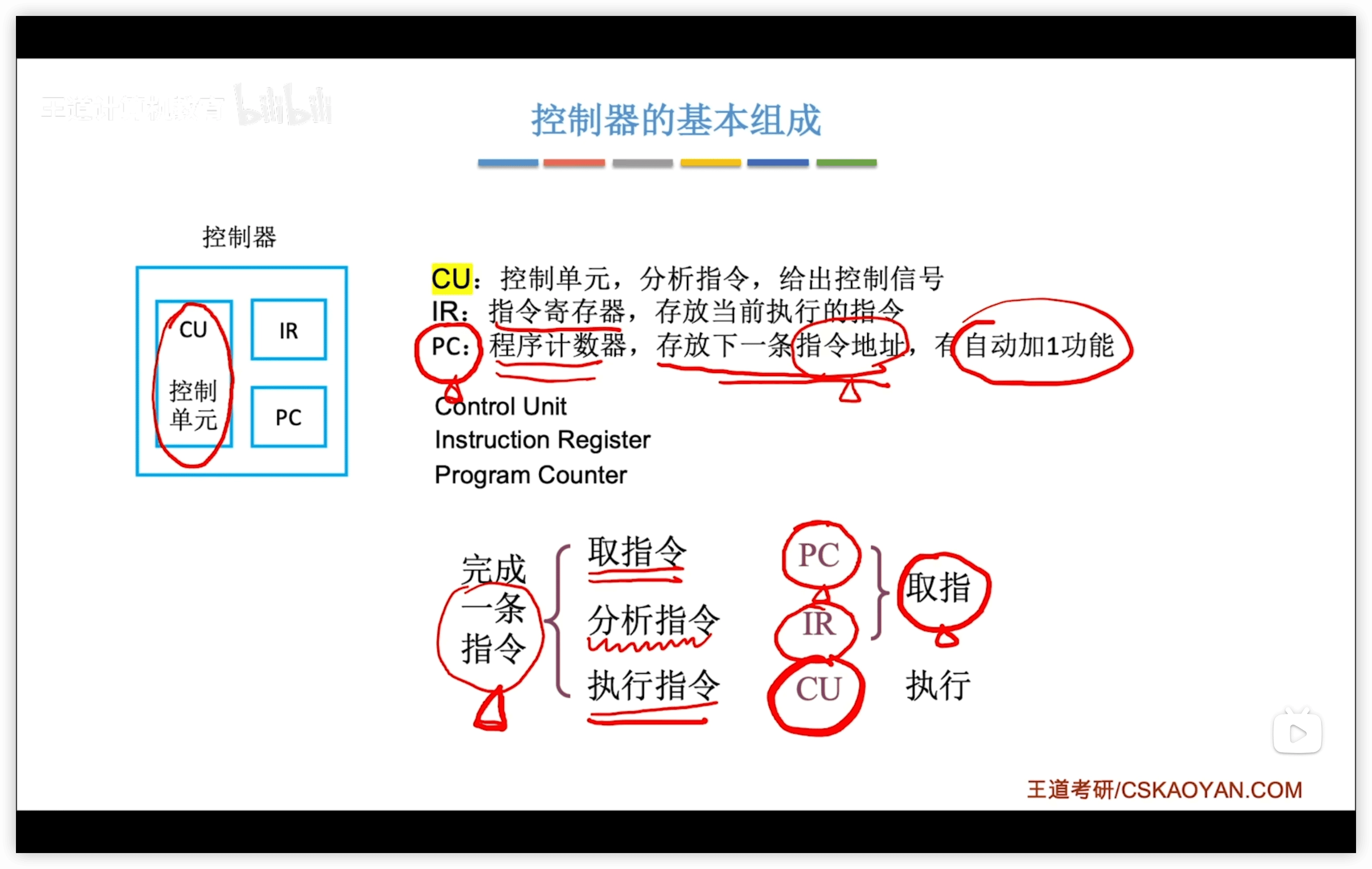
- CU:控制單元,核心,給出控制信號
1.2.4 硬件工作過程
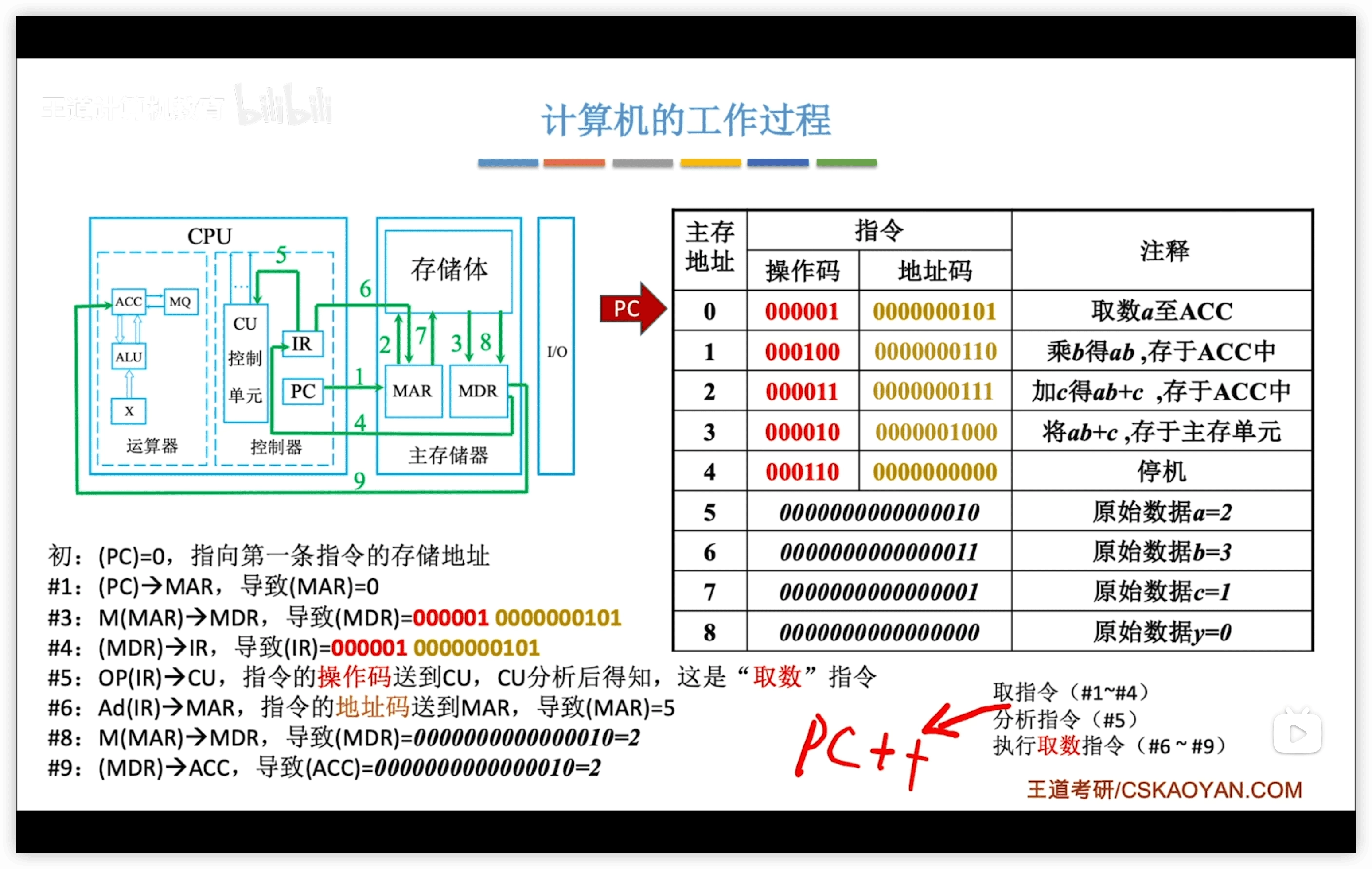
每一步過程都類似:
- 取指令:
- PC to MAR
- MDR to IR:取指令到IR
- 分析指令:
- IR.op to CU:指令的操作碼送到 CU,CU分析指令
- 執行指令
- IR.ad to MAR:指令的地址碼送到 MAR
- 後續操作看具體的指令
1.3 計算機軟件
1.3.1 兩類軟件
- 系統軟件 管理計算機系統的硬件資源,向上層應用程序提供服務。
- 應用軟件 按應用場景需要編製成的各種程序,直接為用戶提供服務。
1.3.2 三個級別的語言
- 高級語言
- 彙編語言:用助記符編寫,以便記憶
- 一條彙編指令幾乎總是對應一條機器指令
- 真題中說指令一般是指機器指令,但是機器指令和彙編指令從本質上說都指向了同一個“指令”的抽象概念,不應該割裂理解。
- 彙編指令只是機器指令的便於人類記憶的形式罷了
- 一條彙編指令幾乎總是對應一條機器指令
- 機器語言:計算機唯一可以直接執行的語言
- 彙編語言和機器語言都與計算機系統結構有關
三種程序:
- 編譯程序/器:將高級語言一次全部翻譯為彙編語言/直接翻譯為機器語言。
- 彙編程序/器:將彙編語言翻譯成機器語言。
- 解釋程序/器:高級語言翻譯為機器語言(翻譯一句執行一句)。
1.3.3 軟件和硬件的邏輯功能等價性
同一個功能,既可以用硬件實現,也可以用軟件實現。
1.3.4 指令集體系結構 (ISA)
- Instruction Set Architecture
一臺計算機可以支持哪些指令,以及每條指令的作用是什麼、每條指令的用法是什麼。
1.3.5 計算機系統的層次結構
計算機系統包含:軟件 + 硬件
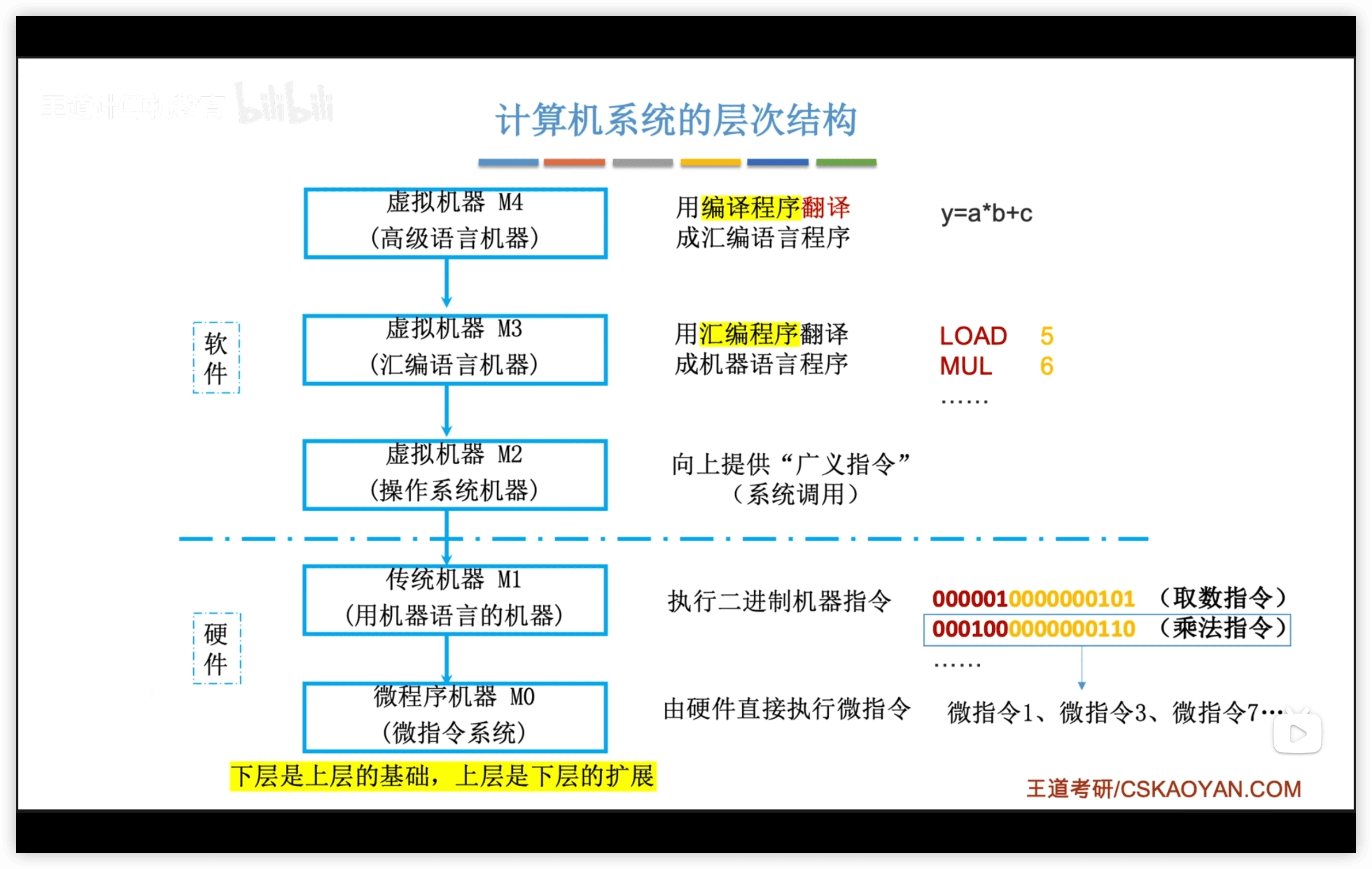
1.3.6 工作原理
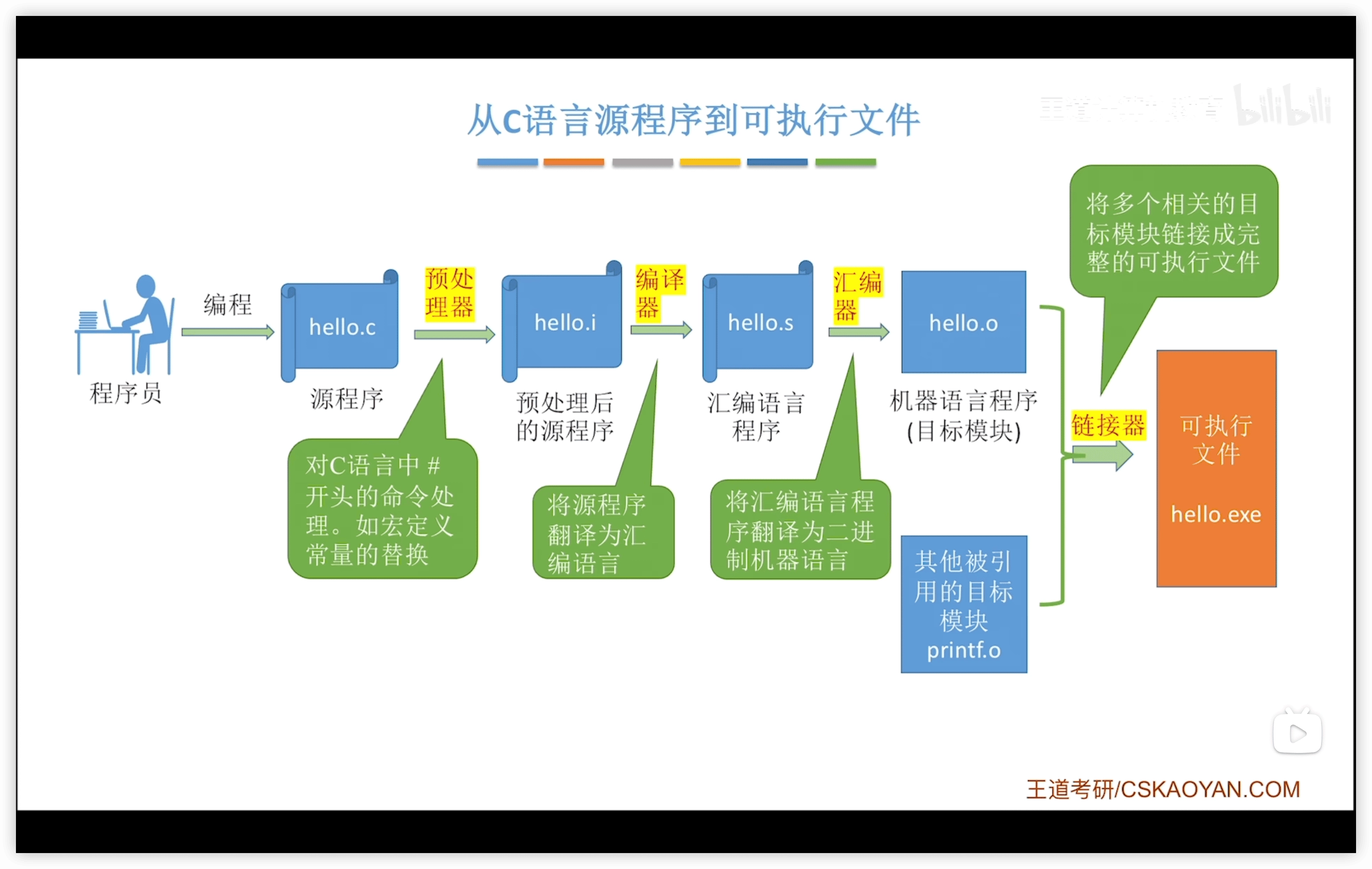
從 源程序 到 可執行文件 的流程:
- 編程:程序員編寫 C 語言源程序(如
hello.c)。 - 預處理:
- 工具:預處理器
- 輸入輸出:
hello.c→hello.i - 為什麼是
.i:因為預處理器最核心的功能之一就是處理#include指令,將所有依賴的頭文件內容整合到一個文件中
- 編譯:
- 工具:編譯器
- 輸入輸出:
hello.i→hello.s(彙編語言程序 )
- 彙編:
- 工具:彙編器
- 輸入輸出:
hello.s→hello.o(機器語言程序,即目標模塊 )
- 鏈接:
- 工具:鏈接器
- 輸入:
hello.o、其他被引用目標模塊(如print.o) - 輸出:
hello.exe(可執行文件) - 將多個相關目標模塊鏈接成完整可執行文件
1.4 性能指標
1.4.1 存儲器性能指標
字長概念辨析
- 機器字長:
- 簡稱字長
- 是 CPU 內部用於整數運算的數據通路的寬度
- 表示 CPU 一次可以處理的最大二進制位數
机器字长 = CPU 内部的通用寄存器位数机器字长 = CPU 内部的运算器位数
- 存儲字長:一個存儲單元中的二進制位數
- 指令字長:一個指令字包含的二進制位數
它們必須都是 1 字節的整數倍。
1.4.2 CPU性能指標
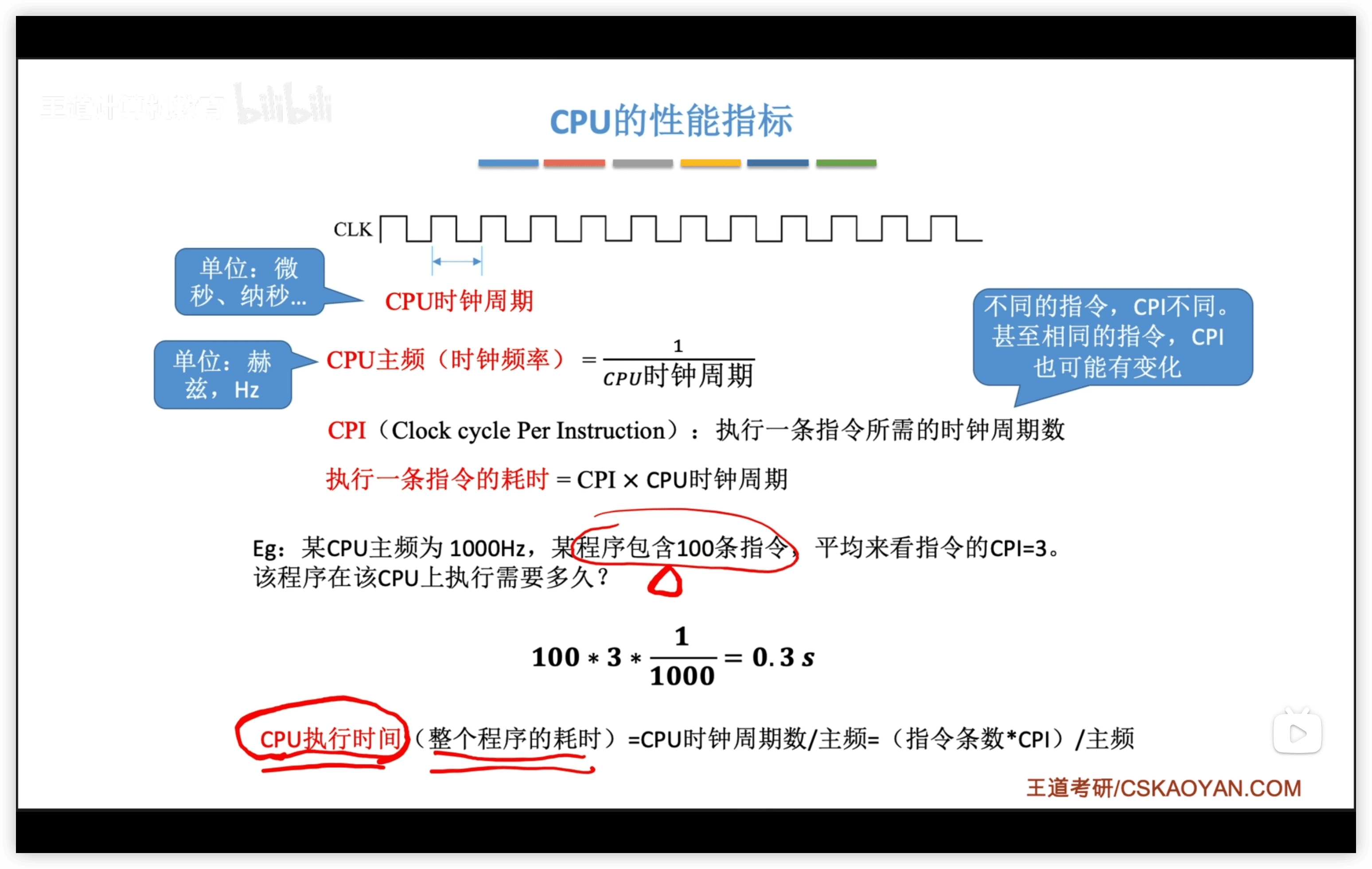
CPU時鐘週期
CPU主頻:
CPI (Clock cycle Per Instruction):執行一條指令所需的時鐘週期數。
IPS:每秒執行多少條指令1. MIPS:每秒執行多少百萬條指令
FLOPS:每秒執行多少次浮點運算
- KFLOPS(Kilo):千,對應
- MFLOPS(Million):百萬,對應
- GFLOPS(Giga):十億,對應
- TFLOPS(Tera):萬億,對應
- PFLOPS(Peta):千萬億,對應 ,考過這種題,😅
- EFLOPS(Exa):百京,對應
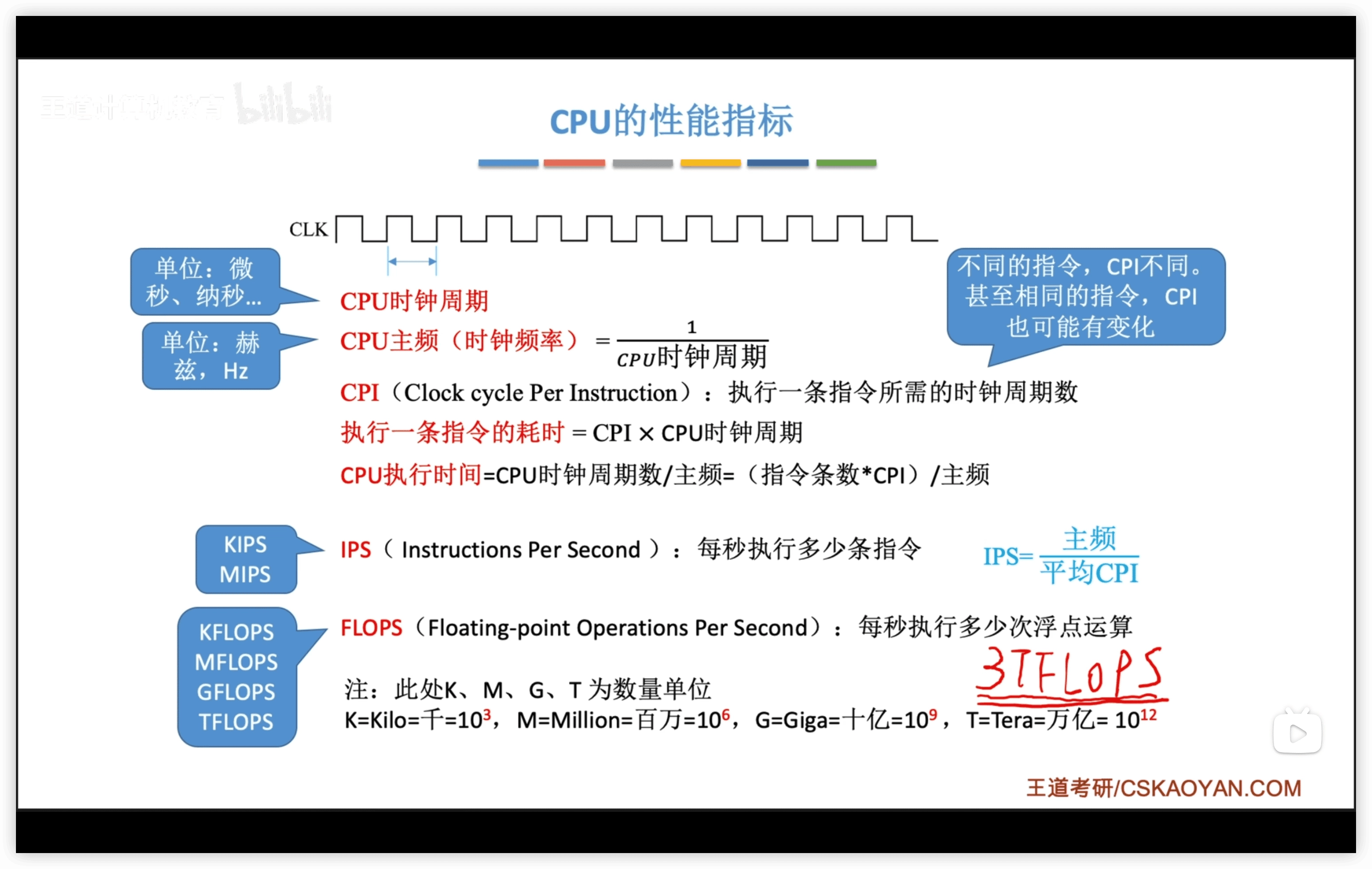
1.4.3 系統整體性能指標
- 數據通路帶寬:數據總線一次所能並行傳送的位數
- 吞吐量:系統在單位時間處理的請求數
- 響應時間:發送請求到做出響應的時間
動態測試:可以用基準程序來測量計算機處理速度
辨析

2 數據的表示和運算
2.1 數制與編碼
常識:
2.1.1 進位計數制
基數:每個數碼位所用到的不同符號的個數
- r進制的基數為r
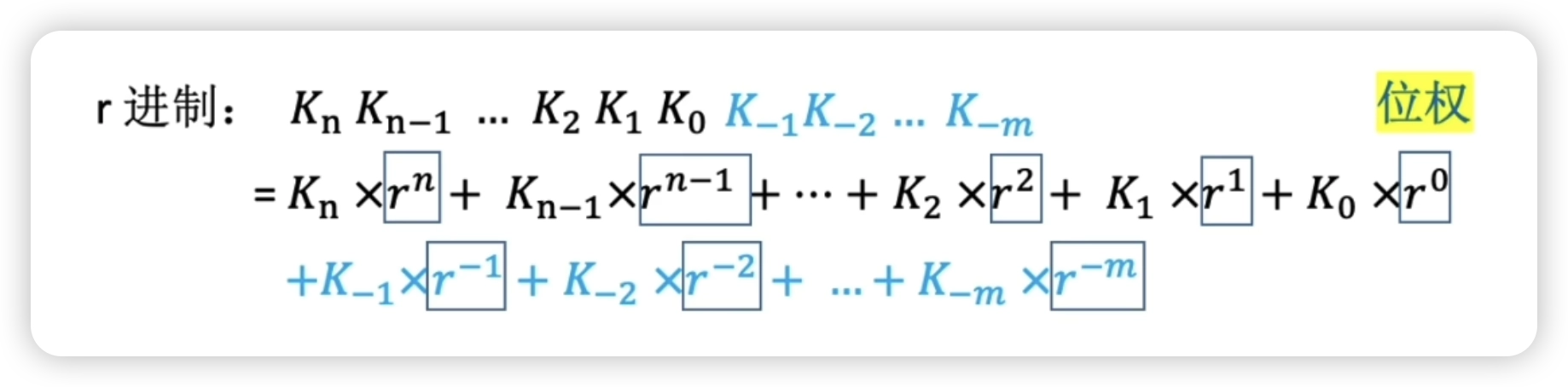
2.1.2 進制轉換
2.1.2.1 轉十進制
按位權

二八六轉換
符號對應

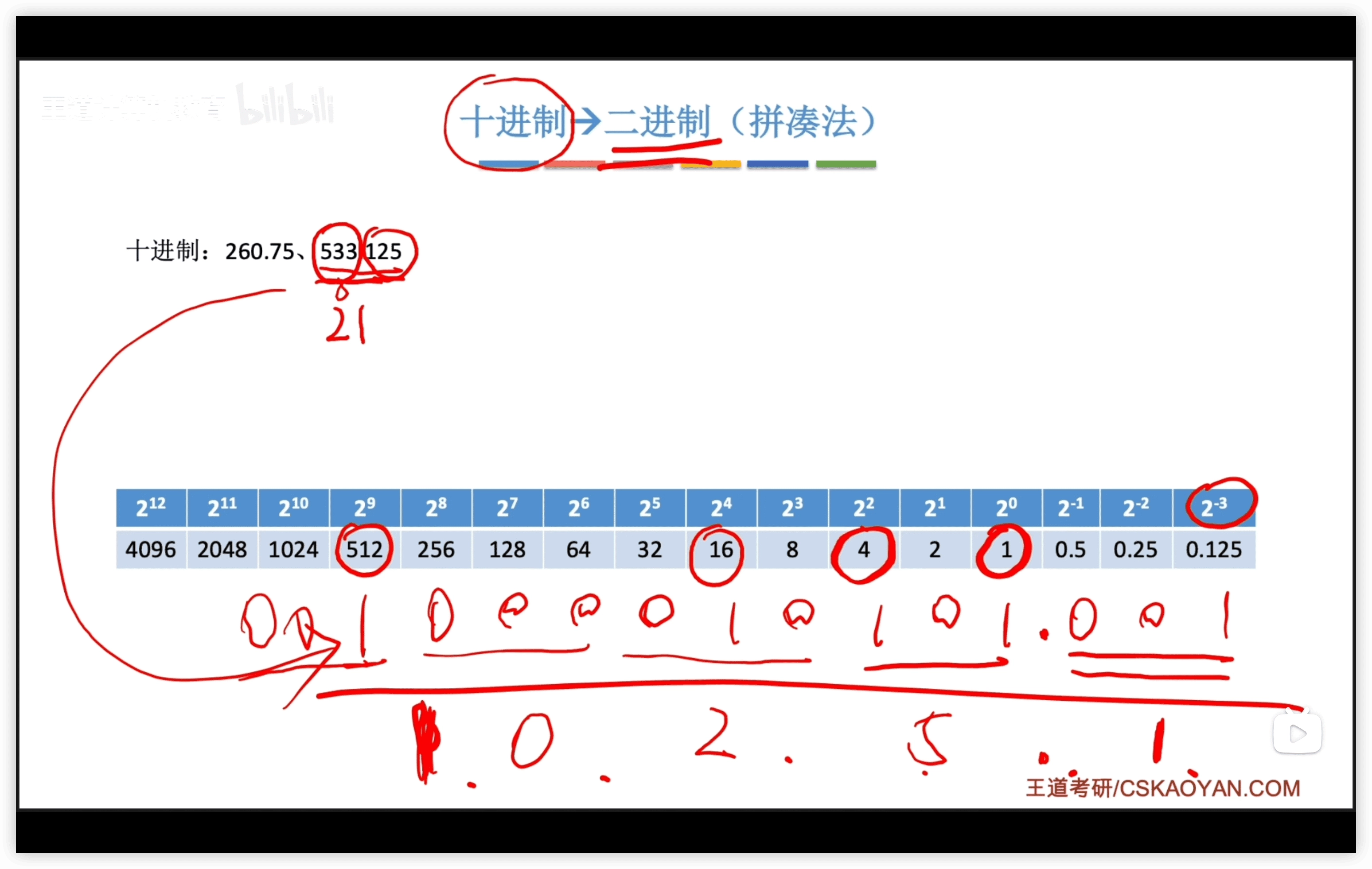
十進制轉換
整數部分:短除法

小數部分:乘r取整

拼湊法:
2.1.3 真值 機器數
| 真值 | 機器數 |
|---|---|
| +15 | 01111 |
| 符合人類習慣 | 數字實際存到機器的形式 |
注意,機器數的正負需要被數字化,多加一位0/1表示符號。
- 408中機器數到底是原碼還是補碼請看題幹
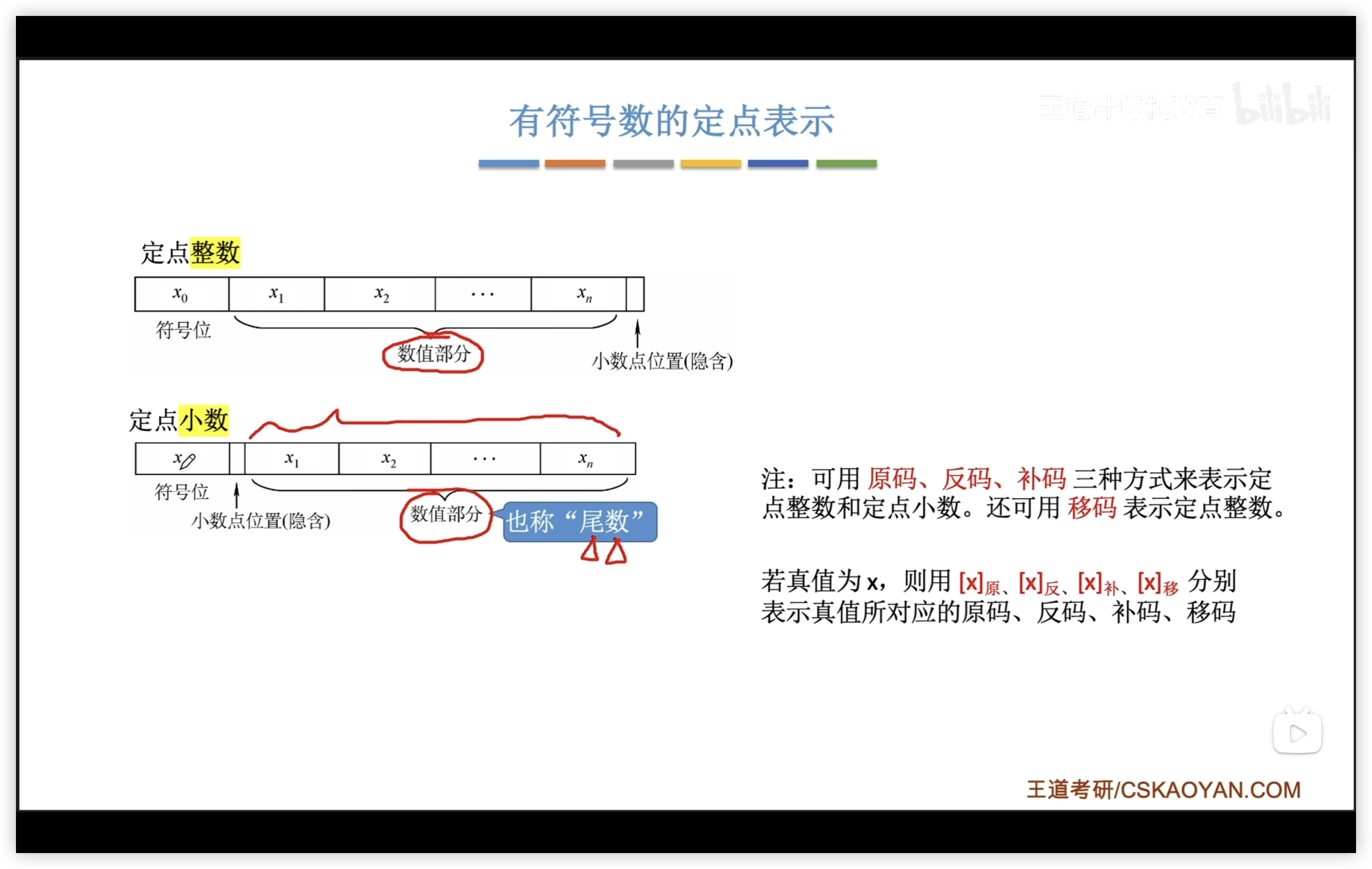
2.1.4 定點數
定點數:
- 無符號數:n位無符號數字的範圍是
- 有符號數
- 原碼
- 反碼
- 補碼
- 移碼
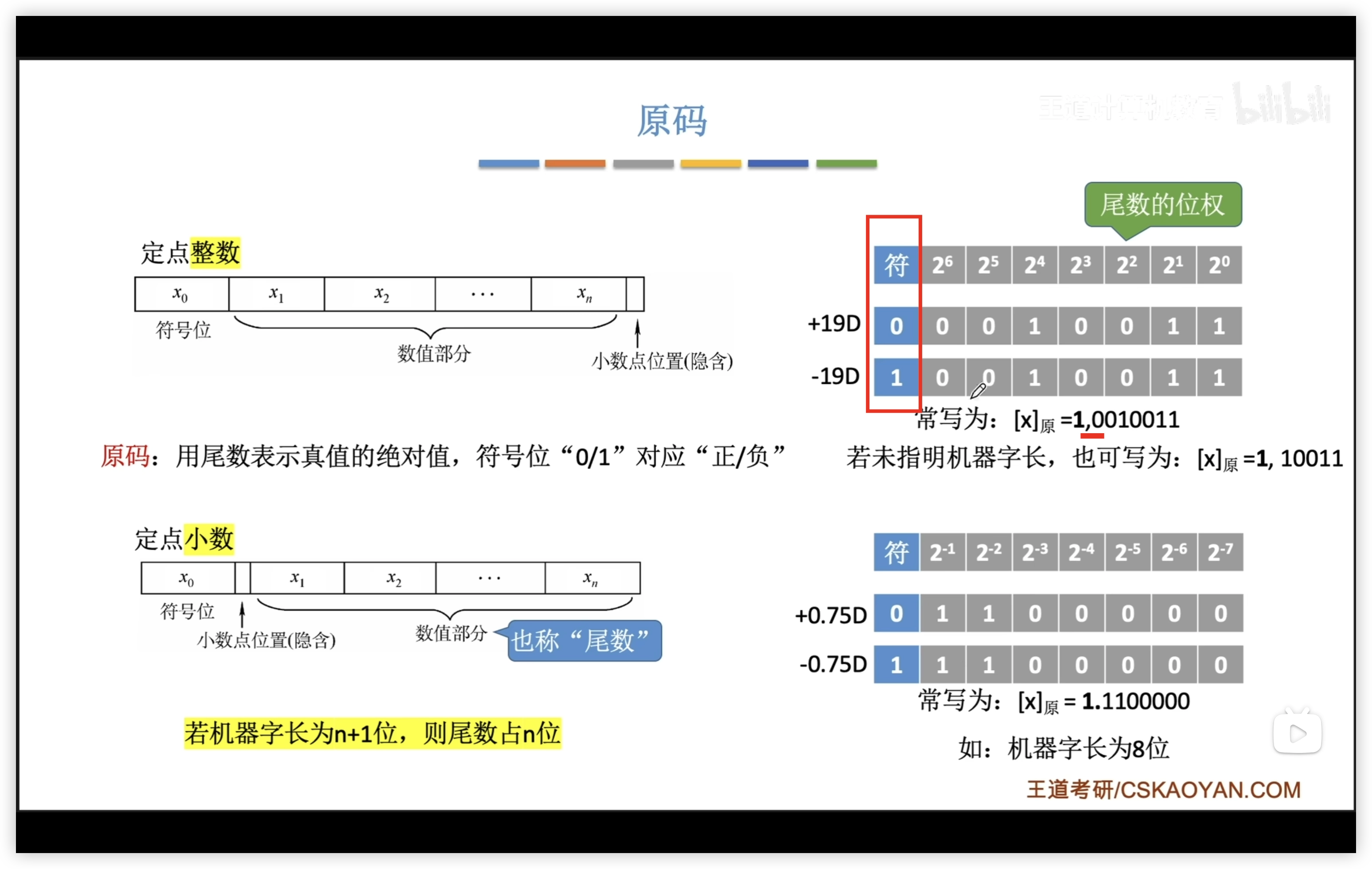
有符號數的定點表示
原碼
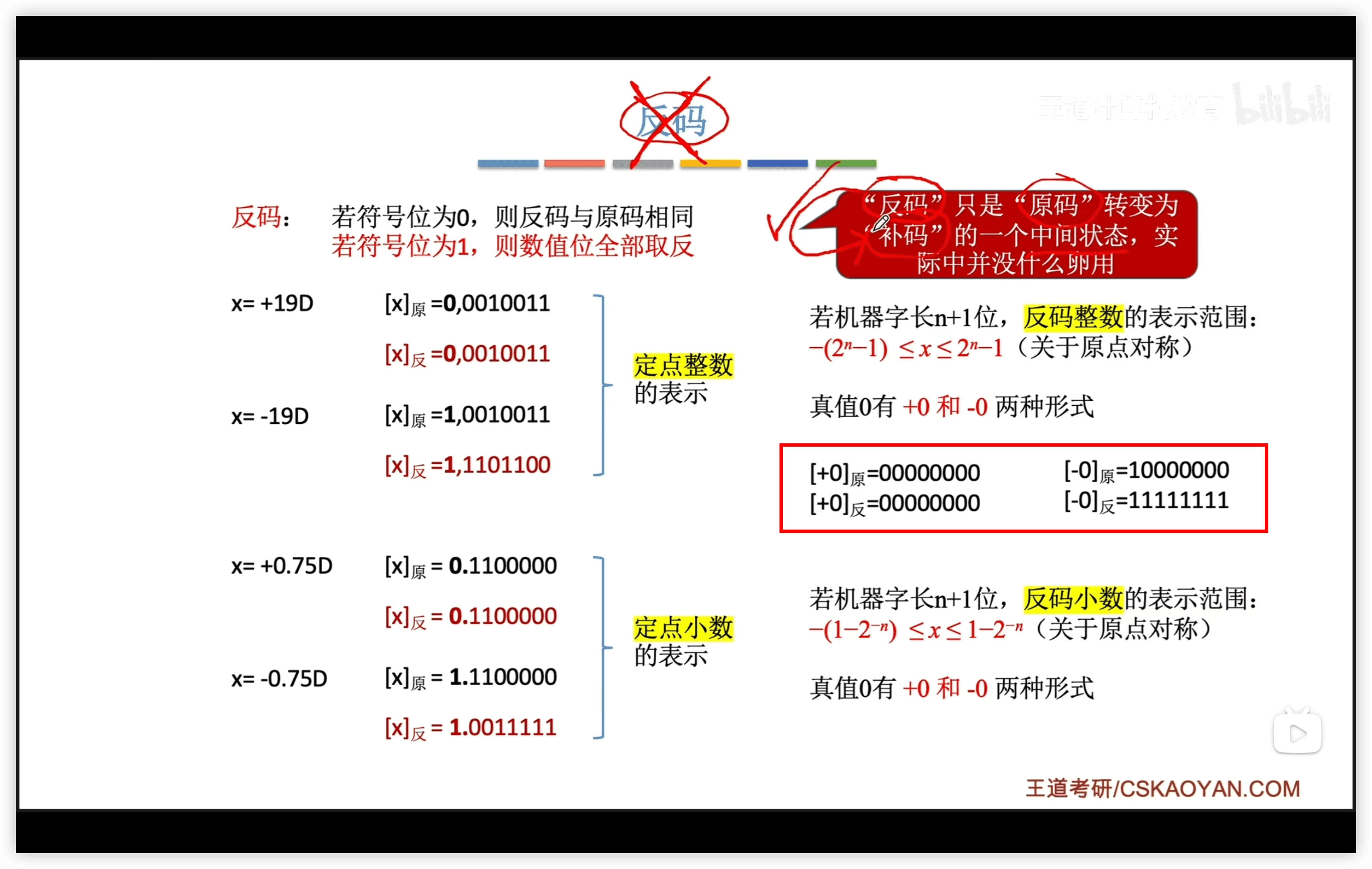
反碼
正數的反碼 = 原碼 負數的反碼 = 數值位取反
補碼
- C語言數據在內存中,以補碼形式存放
正數的補碼 = 原碼 負數的補碼 = 反碼末位+1,需要進位
- 補碼 to 原碼也是同樣的操作
- 補碼和移碼的 0 只有一種表示形式;而原碼和反碼有兩種 1. 故,補碼和移碼範圍 + 1 2. 補碼可以額外表示的數字:1. 注意,10000000沒有原碼對應的真值,因為原碼無法表示

- 補碼可以把減法轉為加法:
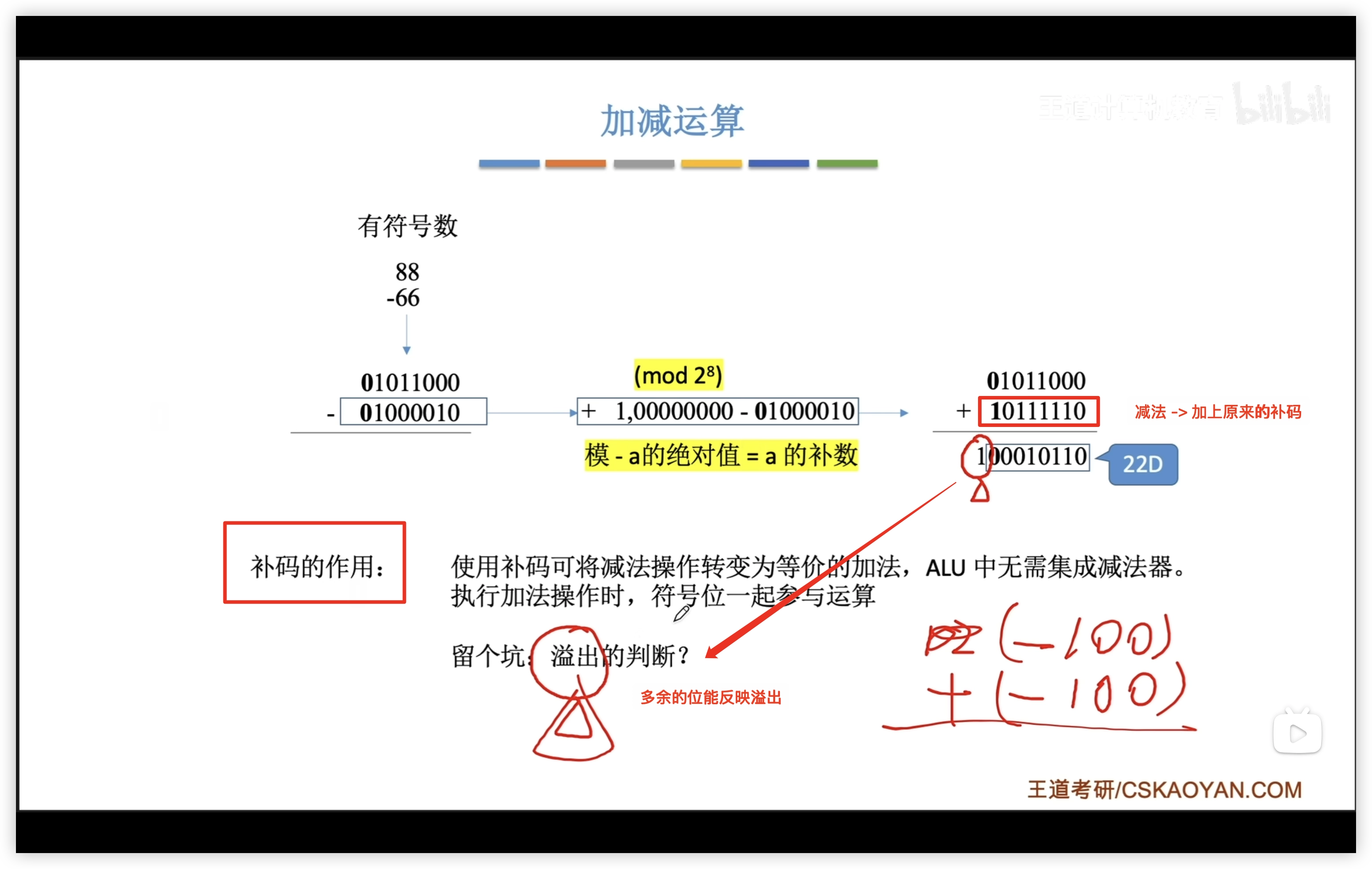
補充:
- 由補快速求的方法:符號位、數值位全部取反,末位+1
移碼
移碼 = 補碼的符號位取反
- 移碼只能表示整數
- 移碼的真值0也只有一種形式
- 表示範圍和補碼相同
移碼可以用於比較大小,從最高位開始,先出現1的數大。
- 移碼是單調增,補碼是分兩個週期線性增大(-128~-1 和 0~127)
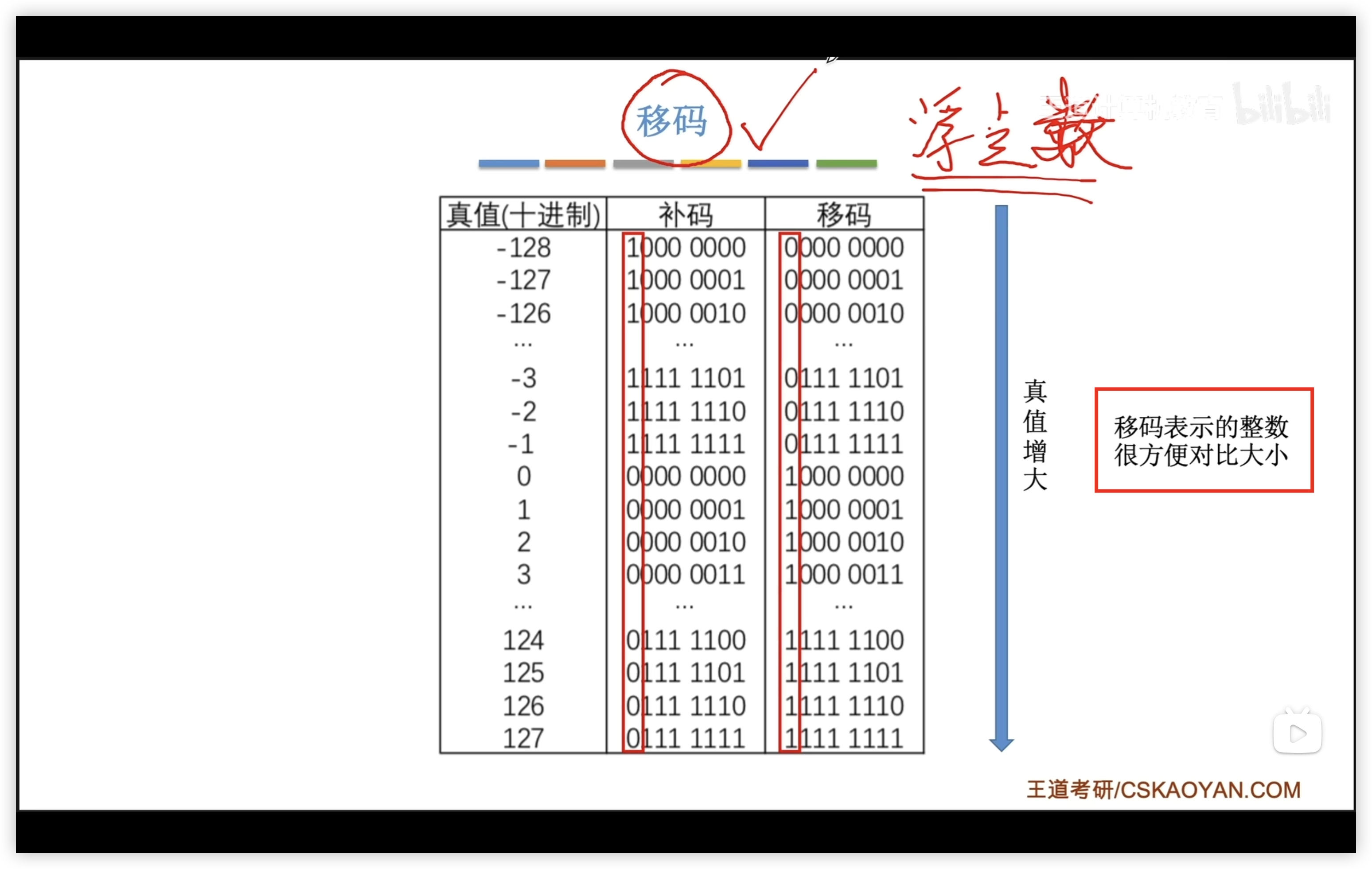
或者加偏置值
2.1.5 語言強制轉換
short to int:
- 有符號數:符號擴展,且不改變真值
- 無符號數:零擴展 int to short:高位截斷
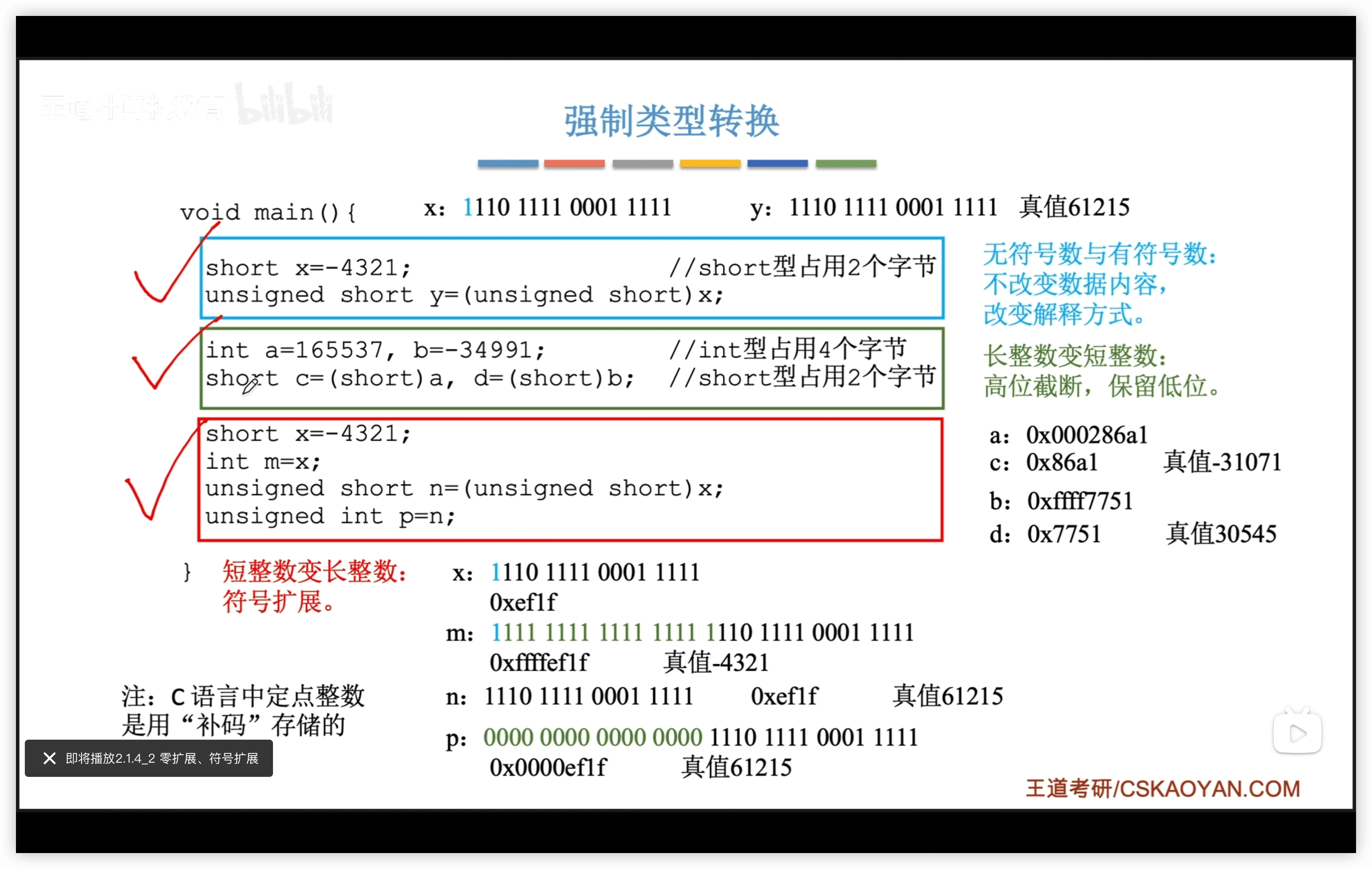
零擴展 符號擴展
- 零擴展適用於無符號數,用0擴展高位
- 符號擴展適用與有符號數,用符號位擴展高位
2.1.6 邏輯門電路基礎
2.1.6.1 邏輯門
補充:n個bit進行異或
- 若有奇數個1則異或結果為1
- 若有偶數個1則異或結果 0
公式
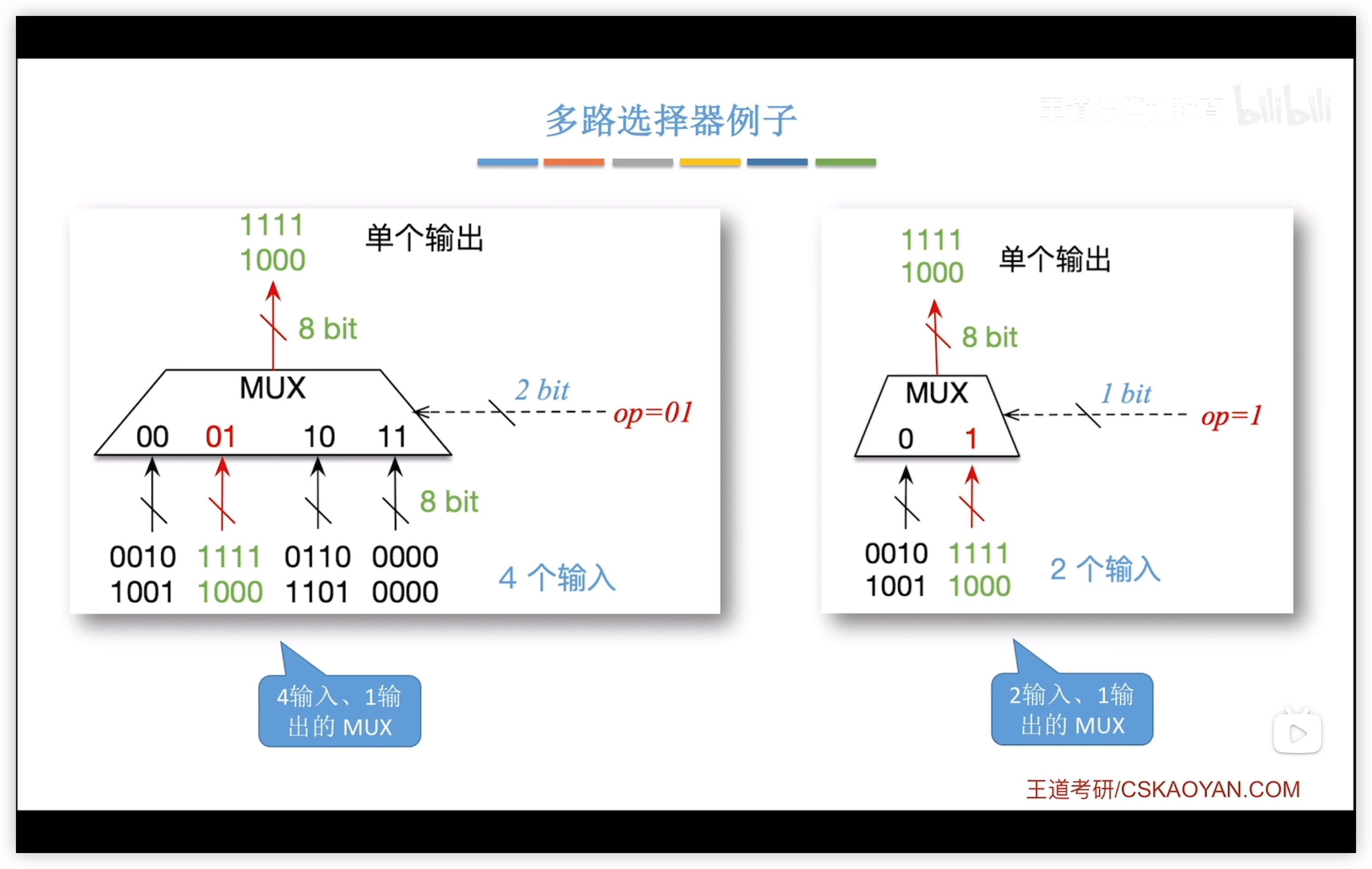
多路選擇器
三態門
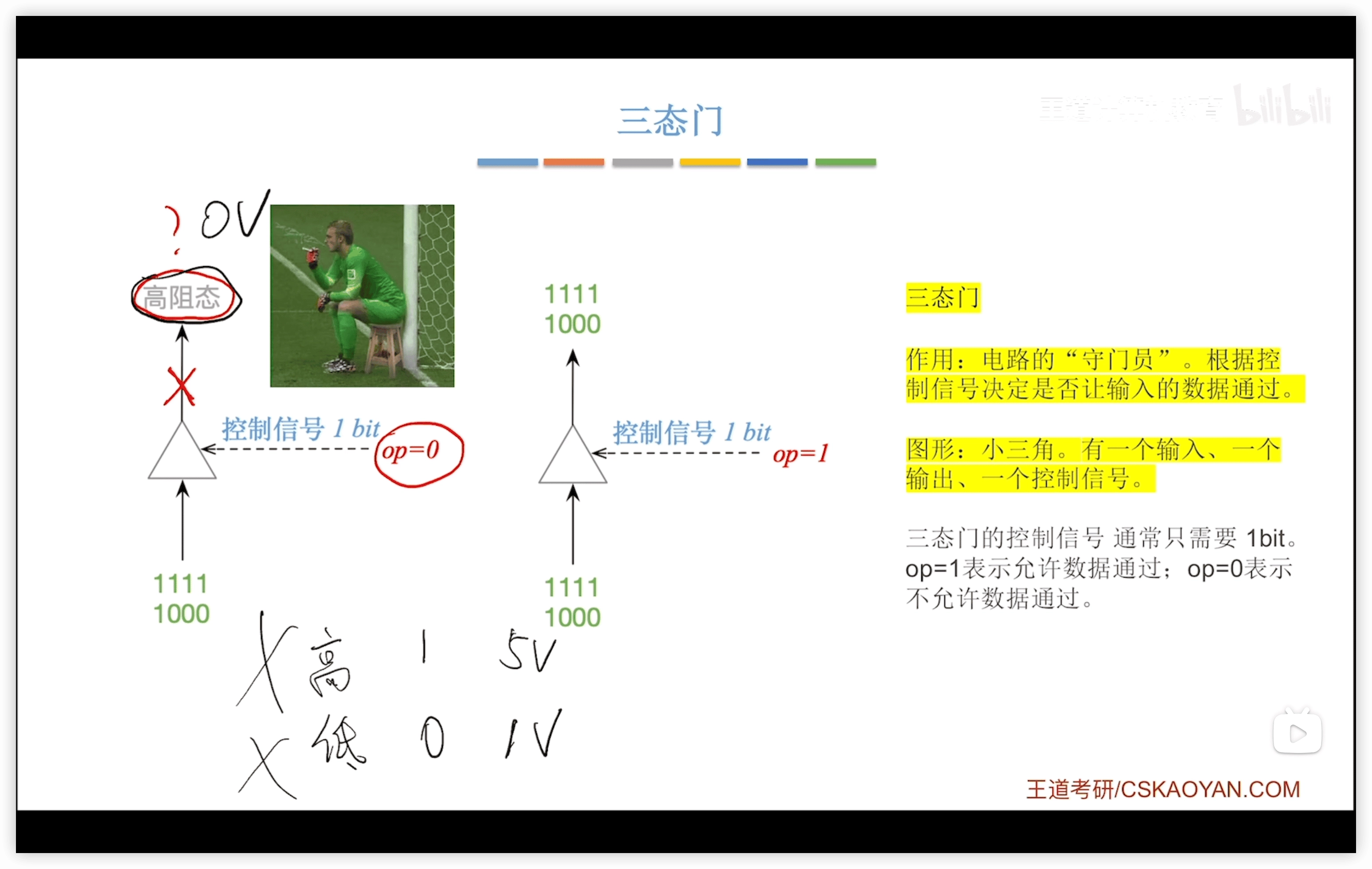
三態:高電平、低電平、高阻態
- 高阻態 = 斷線
2.2 運算方法和運算電路
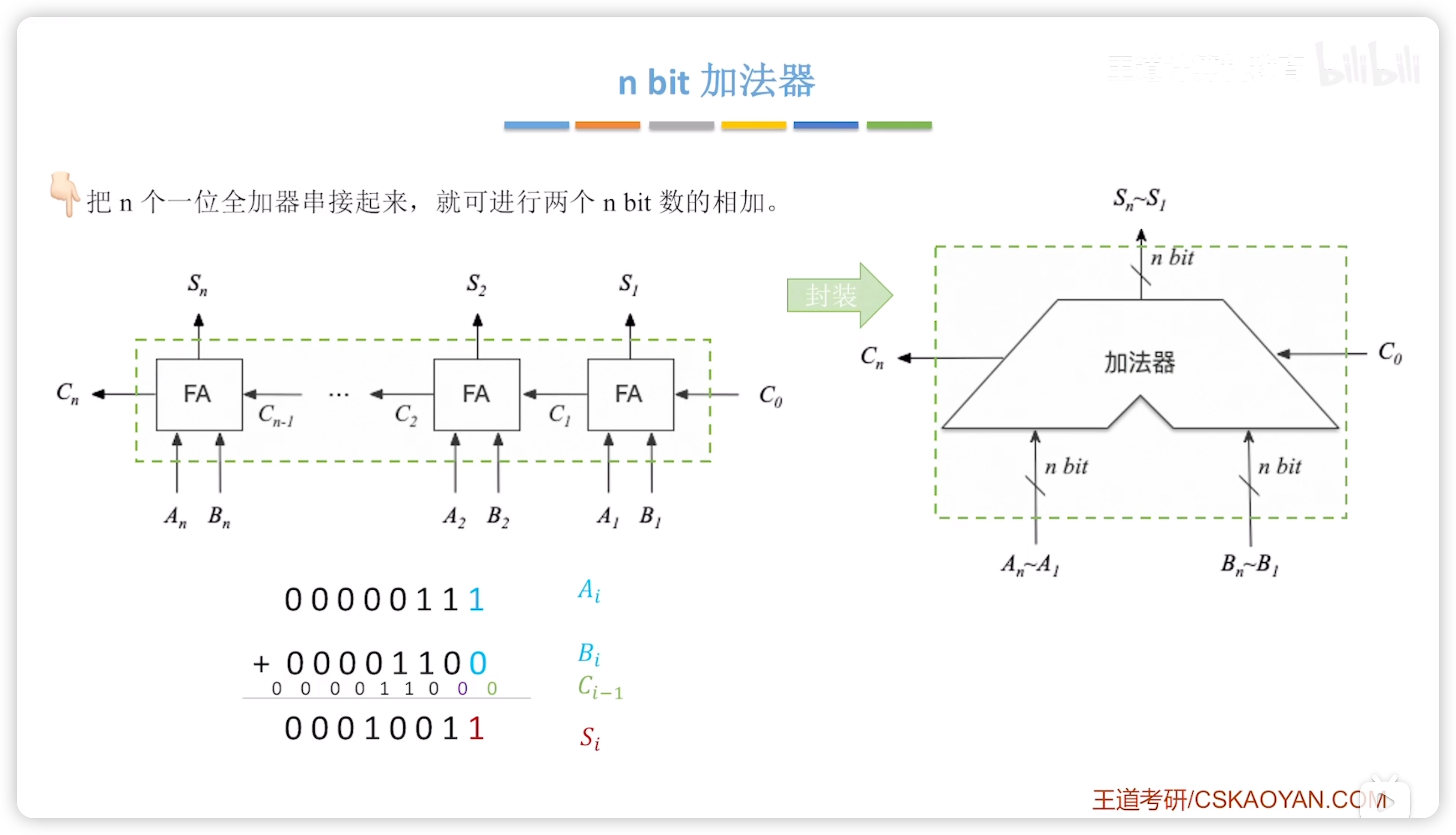
2.2.1 加法器
串行進位加法器
- 串行進位又稱為行波進位
- 但是屬於並行加法器,見術語辨析
問題:進位信息串行傳遞,導致計算速度取決於進位產生和傳遞速度
術語辨析
- 由於兩個輸入端允許並行輸入 n bit,因此這種加法器屬於:並行加法器
- 由於進位信息是串行產生的,因此從“進位方式”看,這種加法器屬於:串行進位加法器
- 綜上,很多教材把這種加法器稱為:串行進位的並行加法器
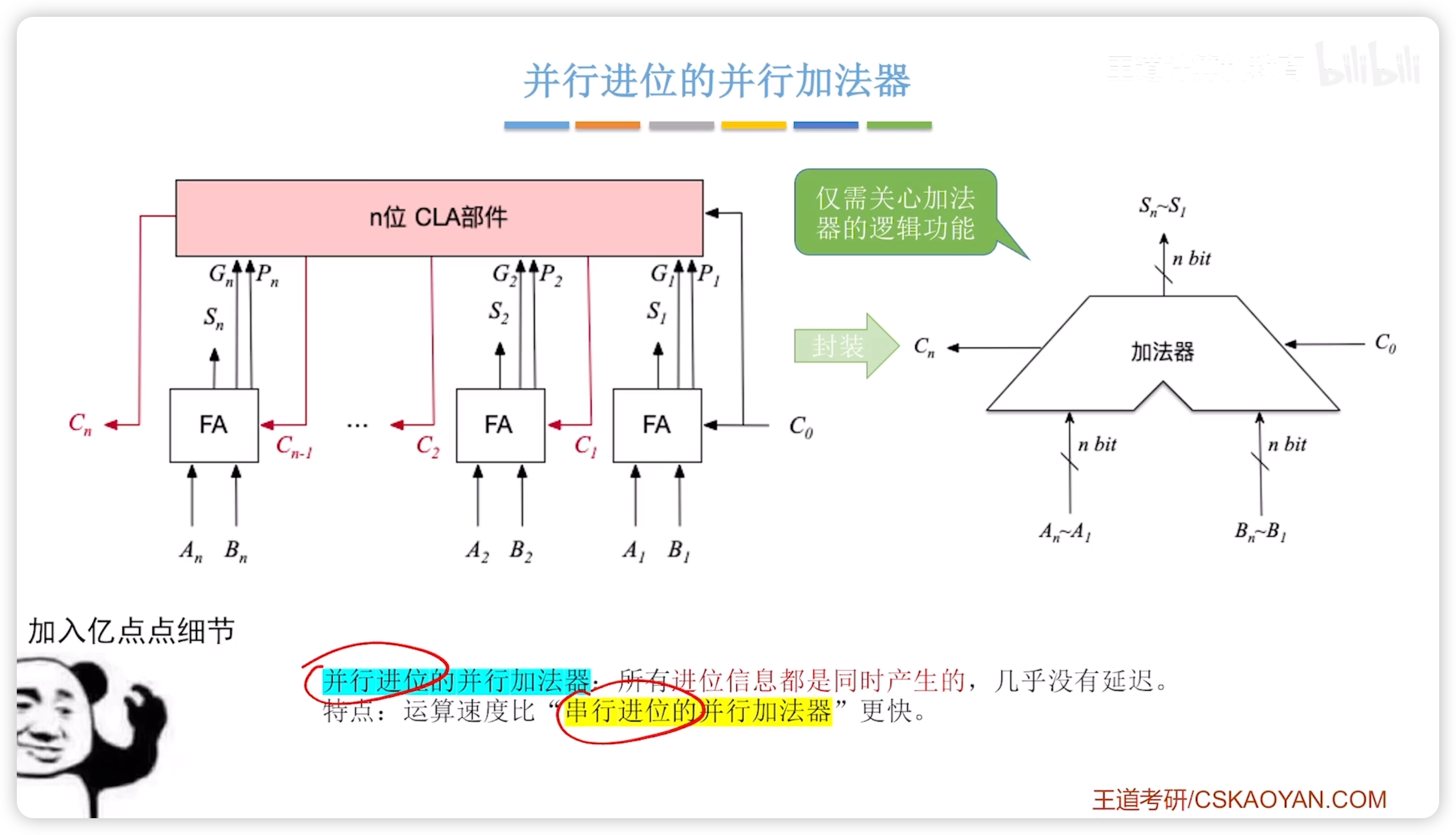
並行進位加法器
加入了CLA部件,使得所有進位信息同時產生。
帶標誌位的加法器
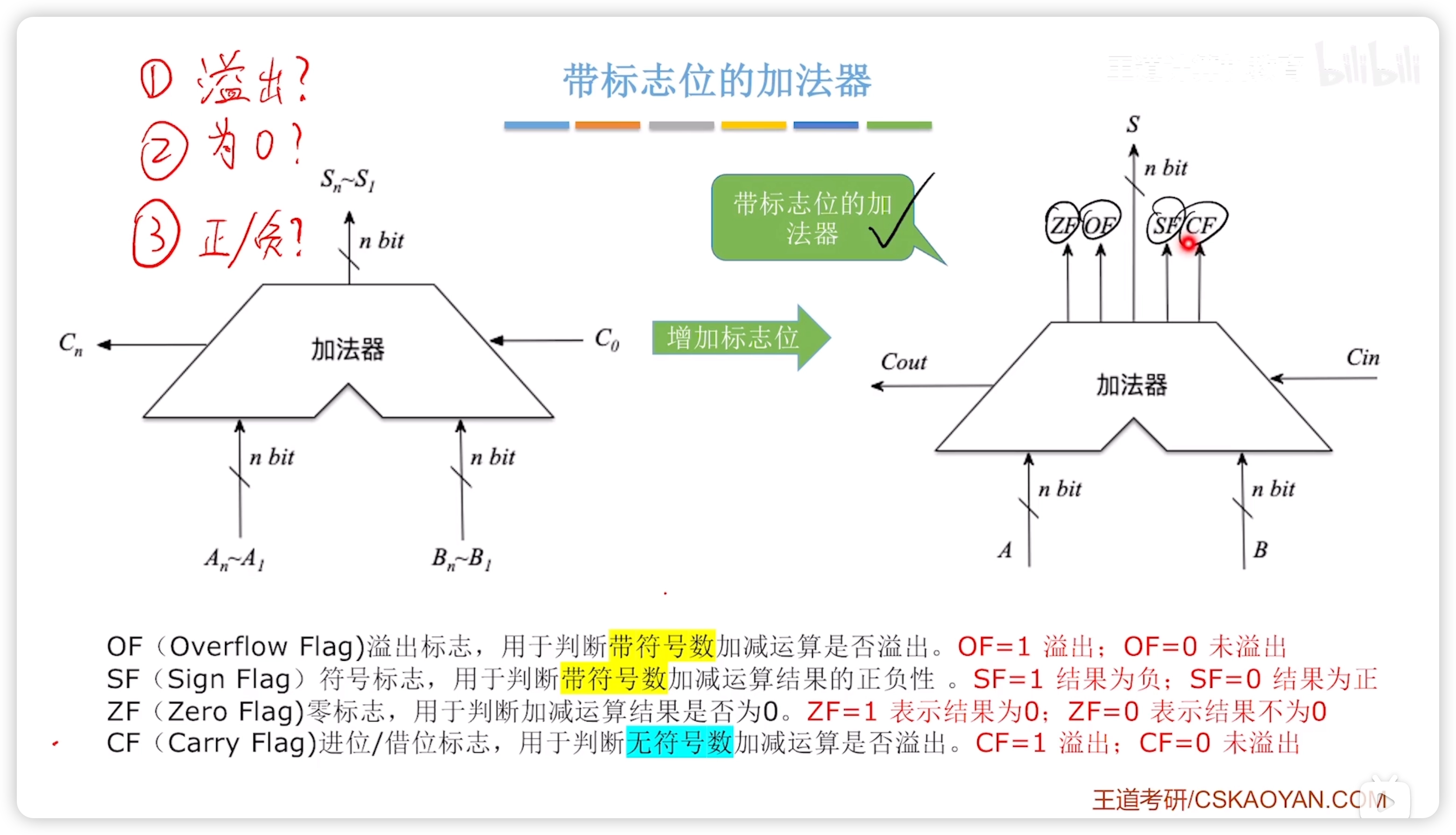
- OF(Overflow Flag)溢出標誌,用於判斷帶符號數加減運算是否溢出。
- OF=1 溢出:OF=0 未溢出
- 也用於表示有符號/無符號整數乘法是否溢出
- SF(Sign Flag)符號標誌,用於判斷有符號數加減運算結果的正負性。
- SF=1 結果負:SF=0 結果為正
- ZF(Zero Flag)零標誌,用於判斷加減運算結果是否為0。
- ZF=1 表示結果0;ZF=0 表示結果不為0
- CF(Carry Flag)進位/借位標誌,用於判斷無符號數加減運算是否溢出。
- CF=1 溢出:CF=0 未溢出
注意,SF 和 OF 對於無符號數運算沒有意義!
- 408p172.27.2011真題
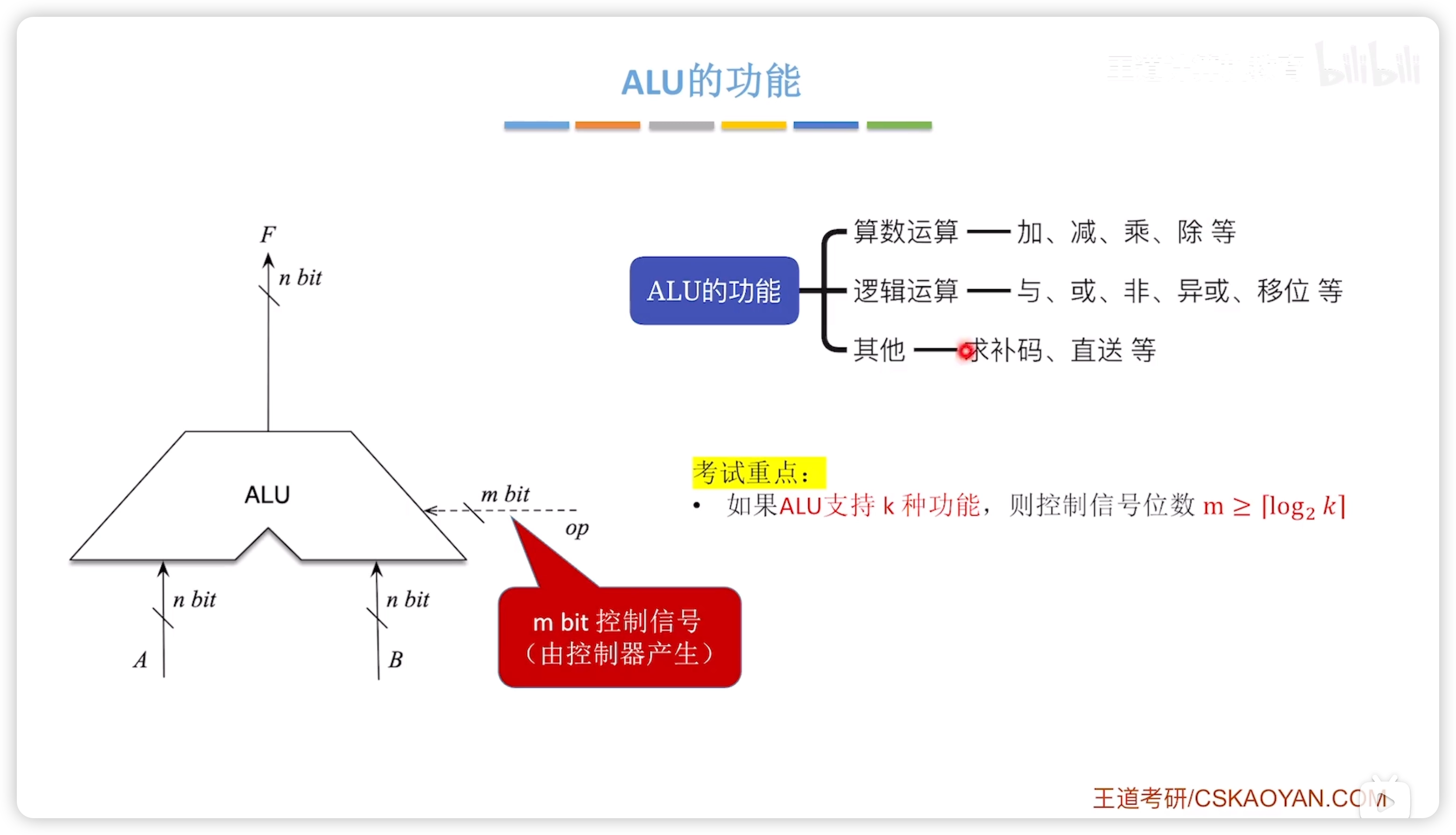
2.2.2 算數邏輯單元 ALU

CPU
- 控制器
- 運算器
- ALU
- 加法器
- 通用寄存器
- 狀態寄存器 PSW
- 移位器
- ALU
ALU是運算器的核心;加法器是ALU的核心。
功能
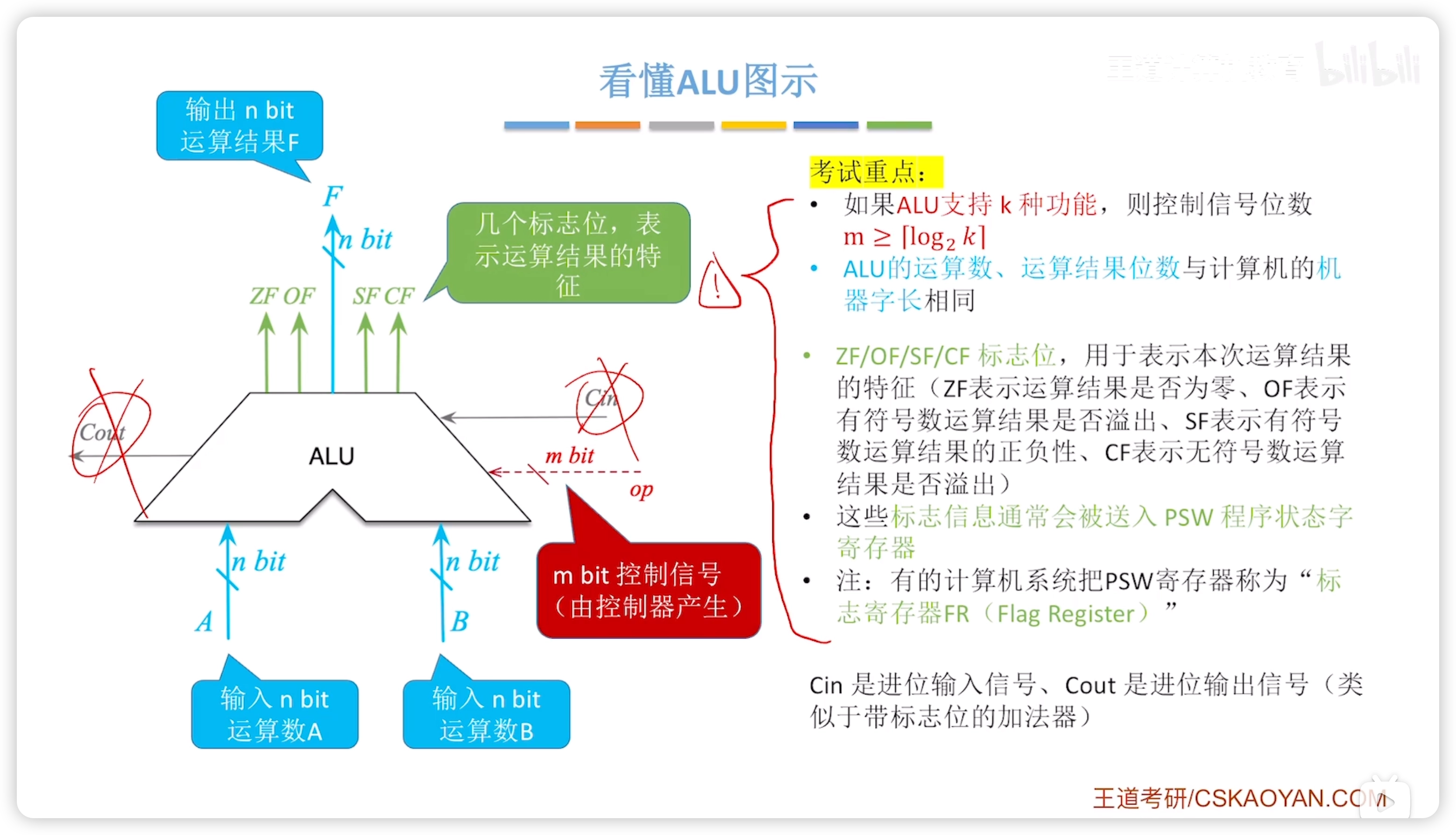
重點:如果ALU支持 種功能,則控制信號位數
2.2.3 定點數的移位
左右移動 位 約等於 乘除
邏輯移位
用於無符號整數
左移:高位丟棄,低位補零
- 右移類似,但是右移丟棄位 = 1則會損失精度
- 溢出判斷:丟棄位是否為 1

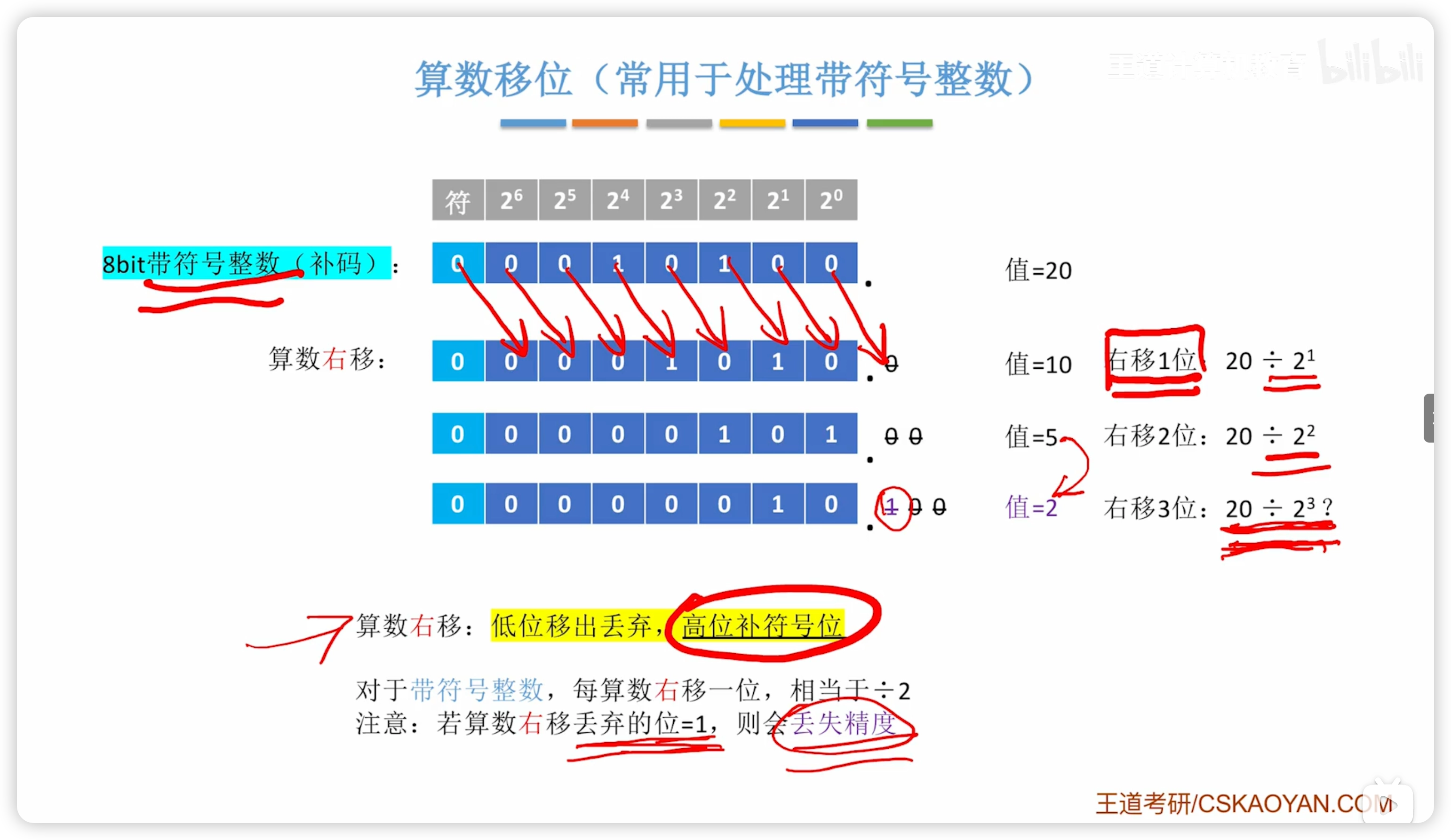
算數移位
用於有符號整數
左移:移動與邏輯移位完全相同,符號位一起移動
- 溢出判斷不同,改為判斷符號位是否改變
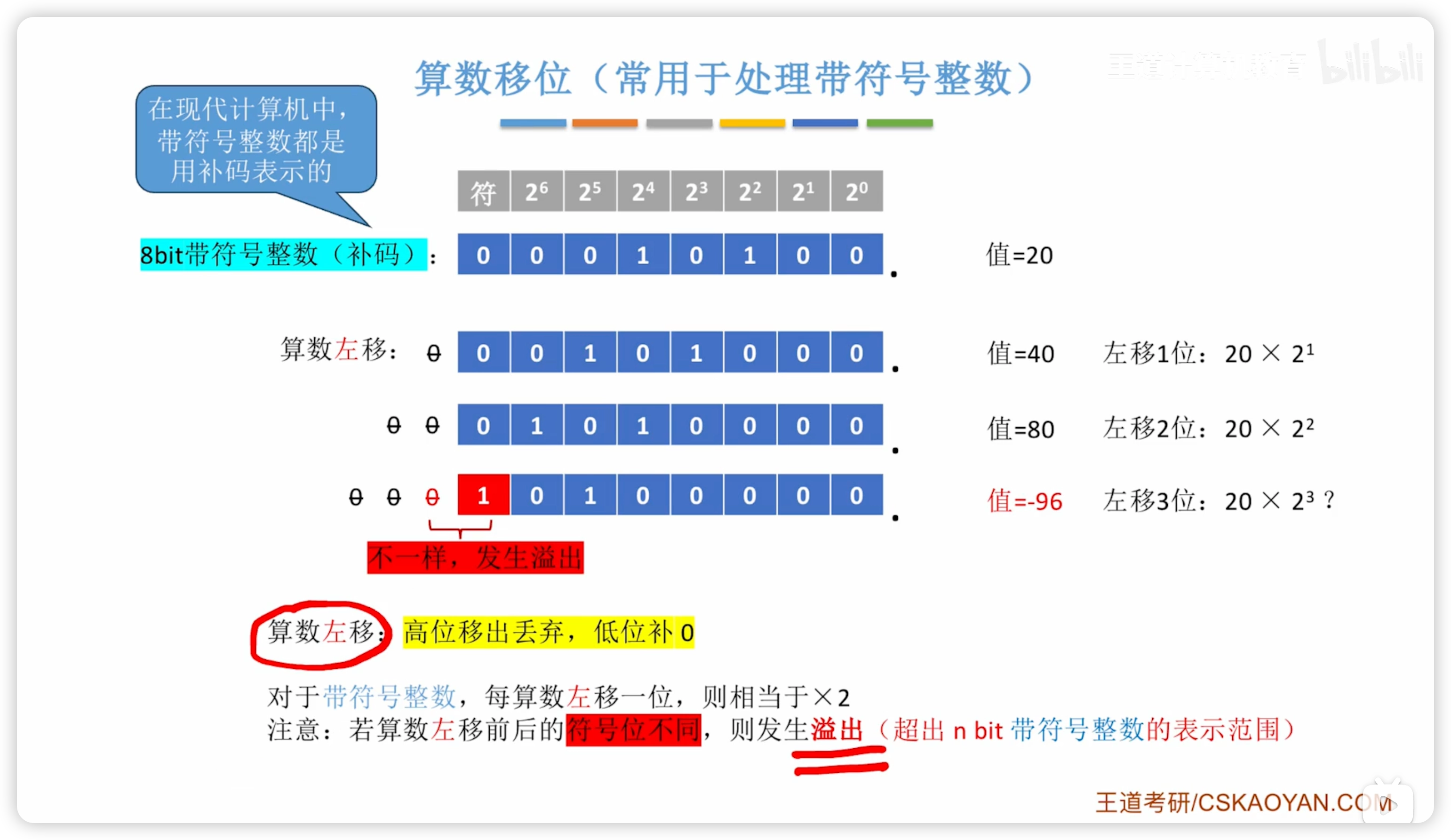
右移高位補充符號位,丟棄位 = 1則也會損失精度
2.2.4 定點數的加減
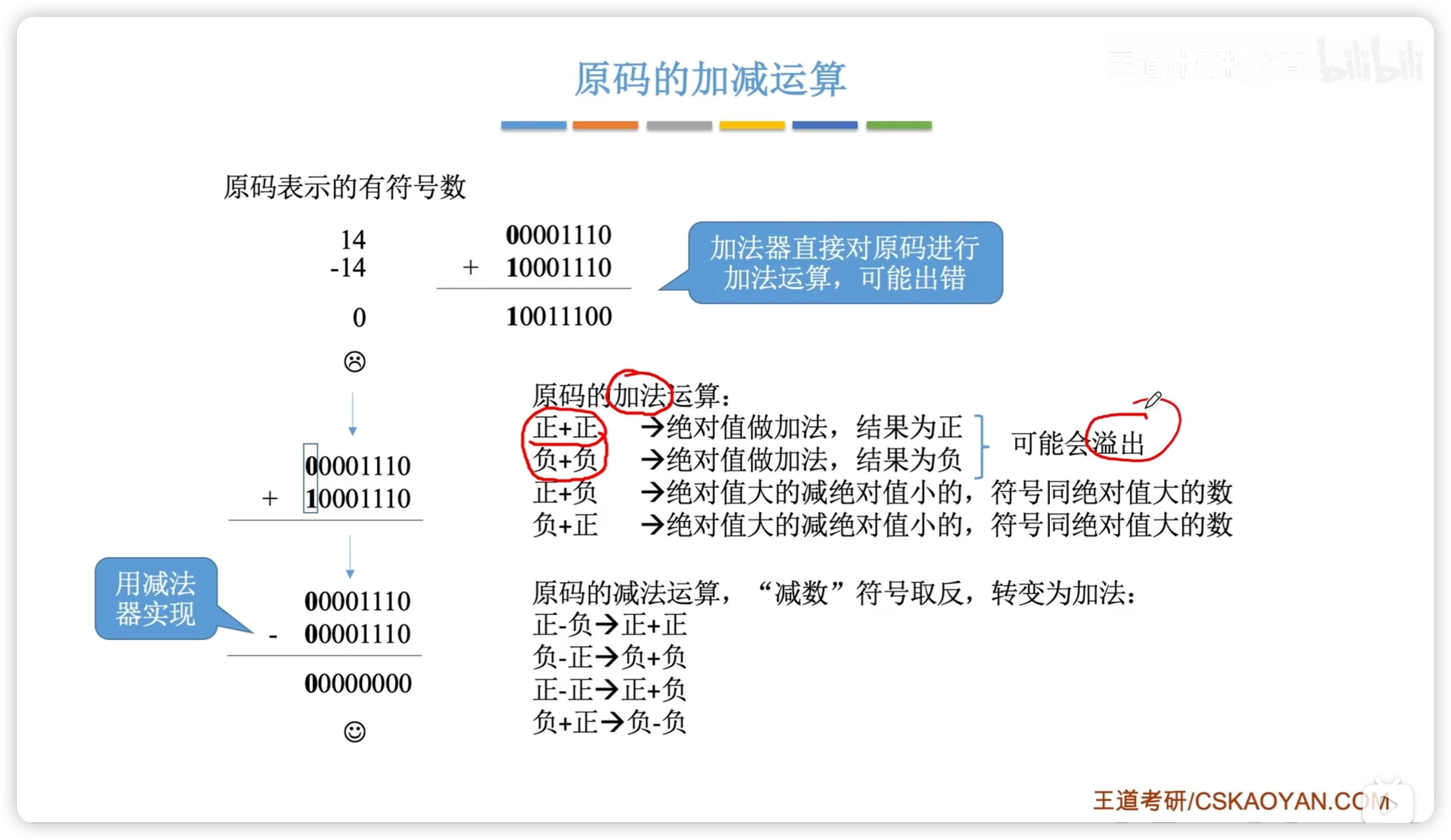
原碼運算麻煩,一般採用補碼運算
原碼加減
絕對值加減,再處理符號
補碼加減
- 減法 = 加負數
- 符號位直接參與運算

溢出判斷:
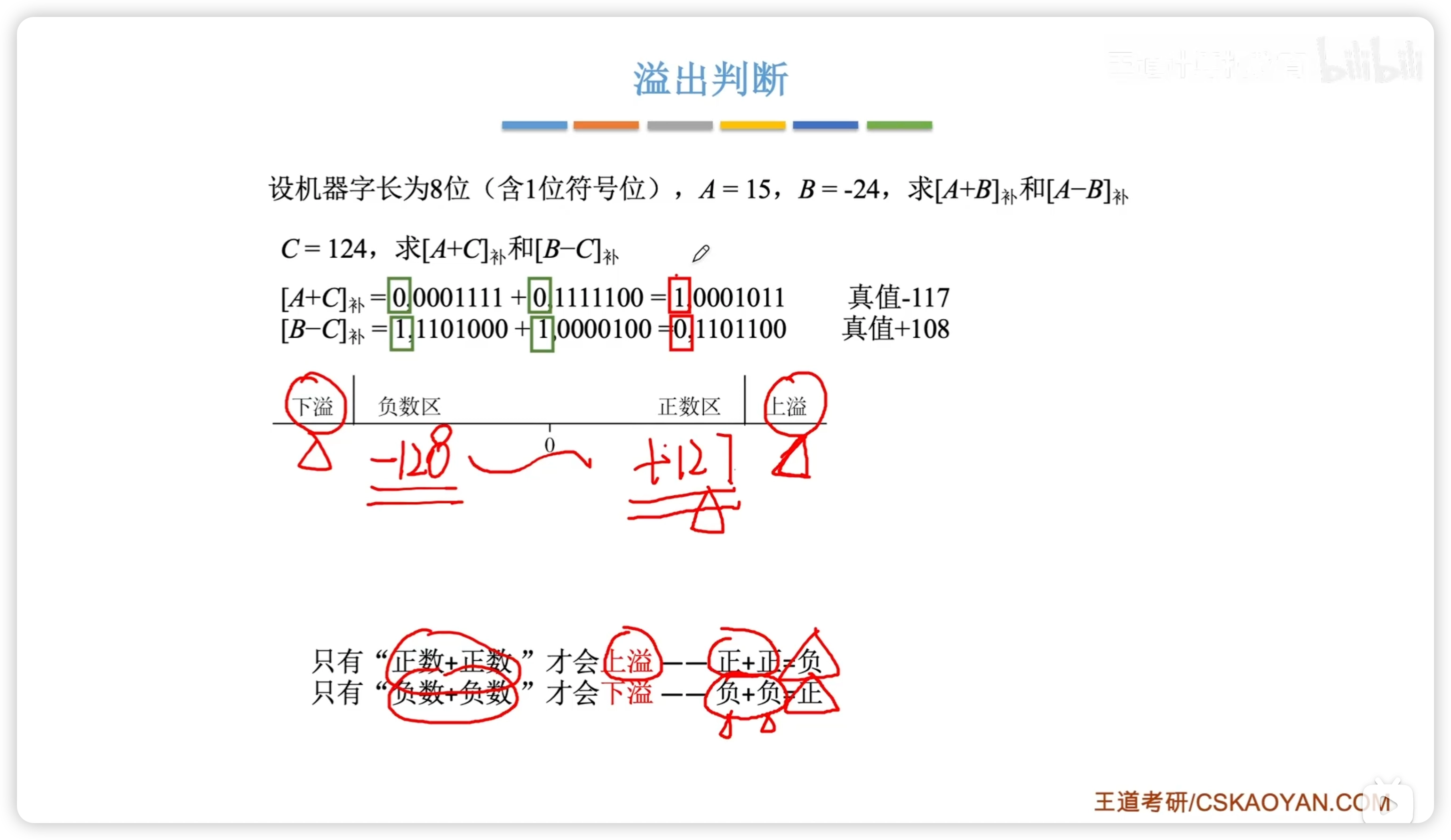
由上圖易知,溢出情況看符號位即可:
- 上溢:正 + 正 = 負 0 0 1
- 下溢:負 + 負 = 正 1 1 0
- 這個就是判斷後文 OF 溢出標誌位的方法
- 減法看成加負的數即可,也可以按照 001 和 110 推導
模4 和 模2 補碼
模4:雙符號位 模2:單符號位

2.2.5 無符號數的加減
加法:按位相加即可
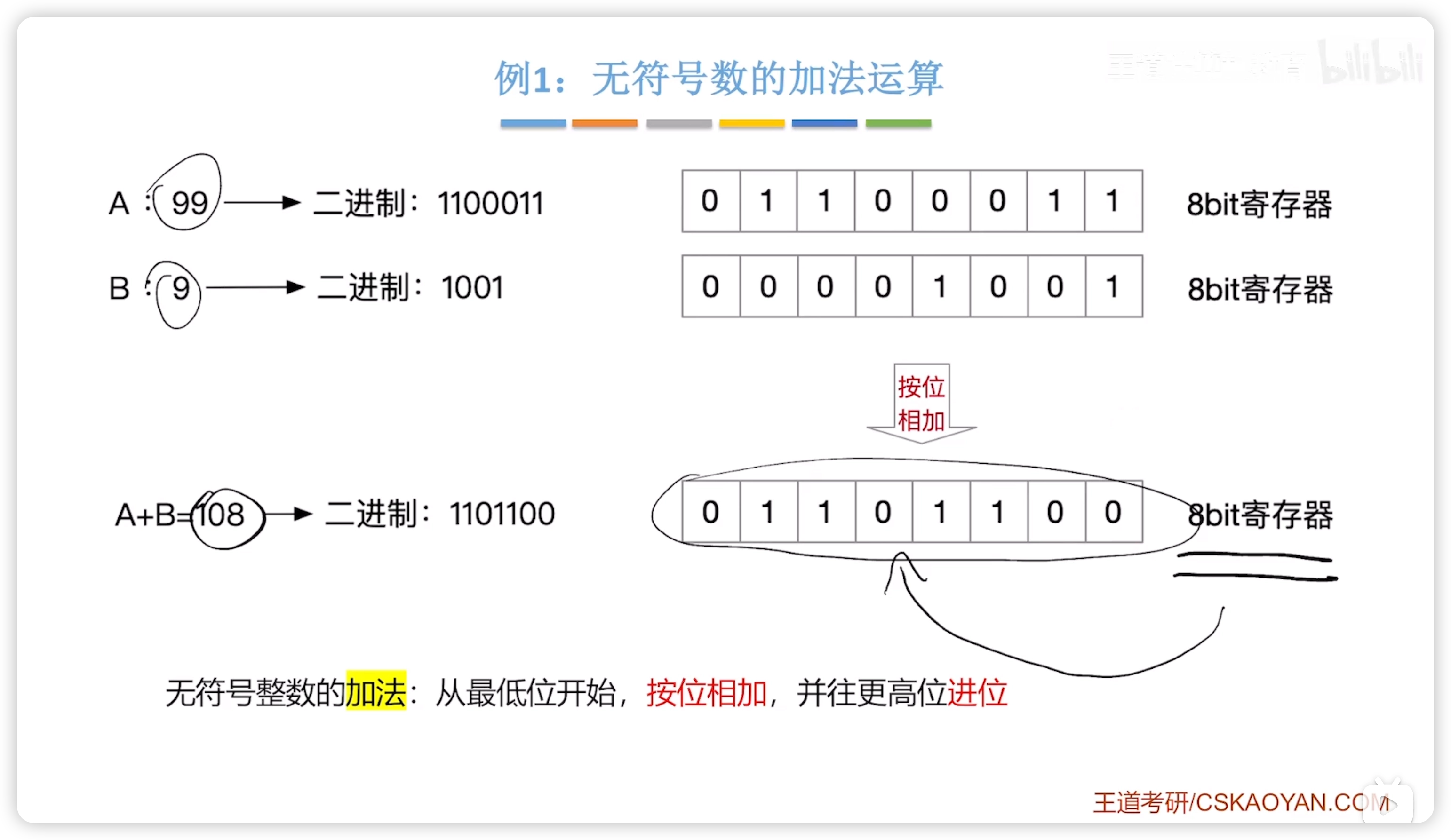
減法:減數取補碼,減法變加法
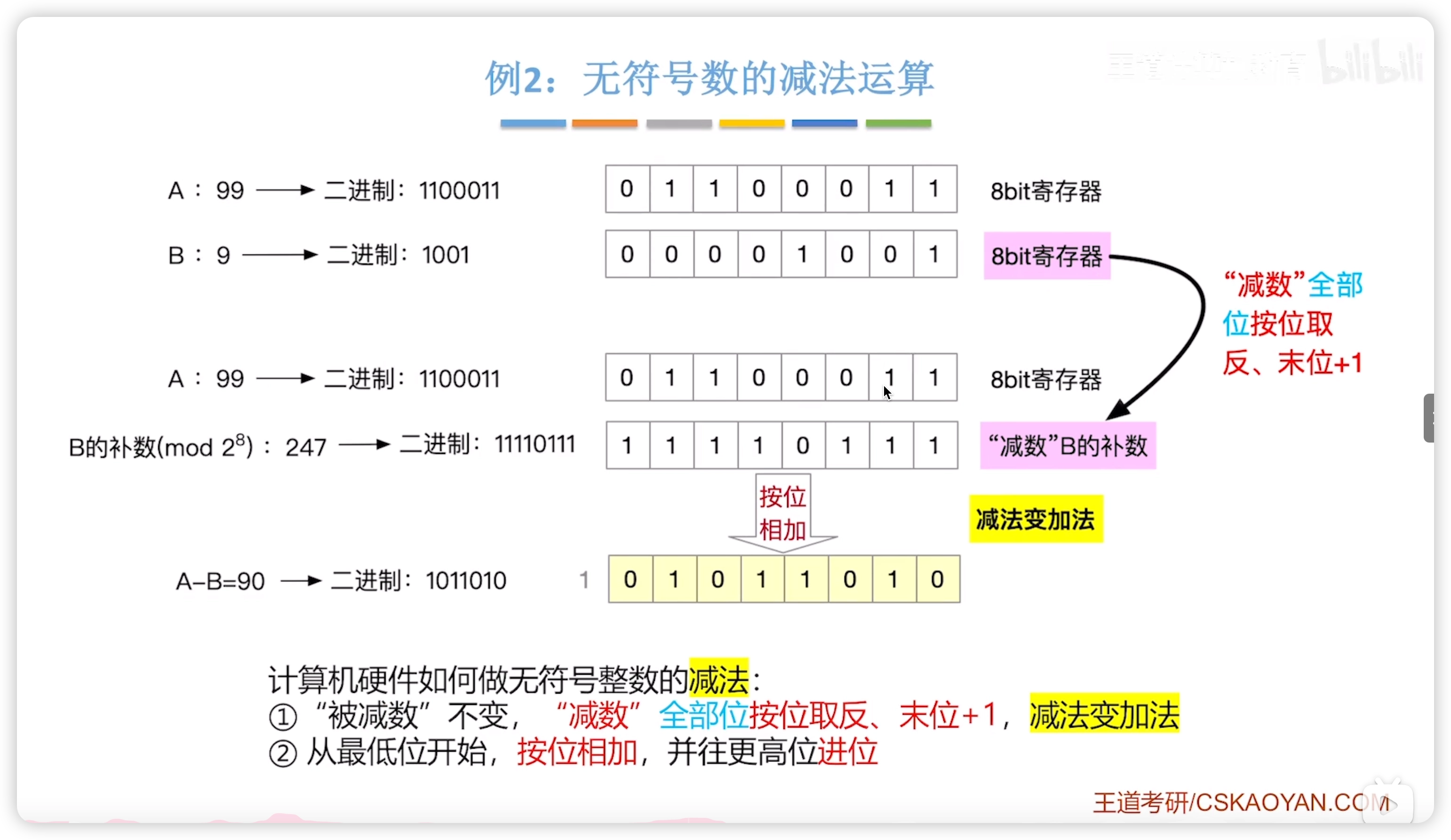
溢出判斷

- 考試時,直接按照十進制算一下即可
- 注意,無符號數是沒有負數的, 是溢出的!
結合標誌位理解:

2.2.6 補碼加減運算電路
補碼加減運算電路實現了無符號數和有符號數的統一,電路只是計算兩個二進制串,並不關心是否有符號。
- 對於 OF 標誌位,當作有符號數理解,判斷加/減是否有溢出即可
- 對於 CF 標誌位,當作無符號數理解,判斷加/減是否有進位/借位即可 - 可能涉及有符號數到無符號數的轉換,快速方法是

當然也可以按公式算,不過就慢了。

- 大題寫計算過程可能需要公式
sub 信號的兩點作用:
- 多路選擇器由 sub 信號控制,實現了(減法時)減數取反的操作
- sub 信號作為 cin (來自低位的進位),實現了取反之後 + 1
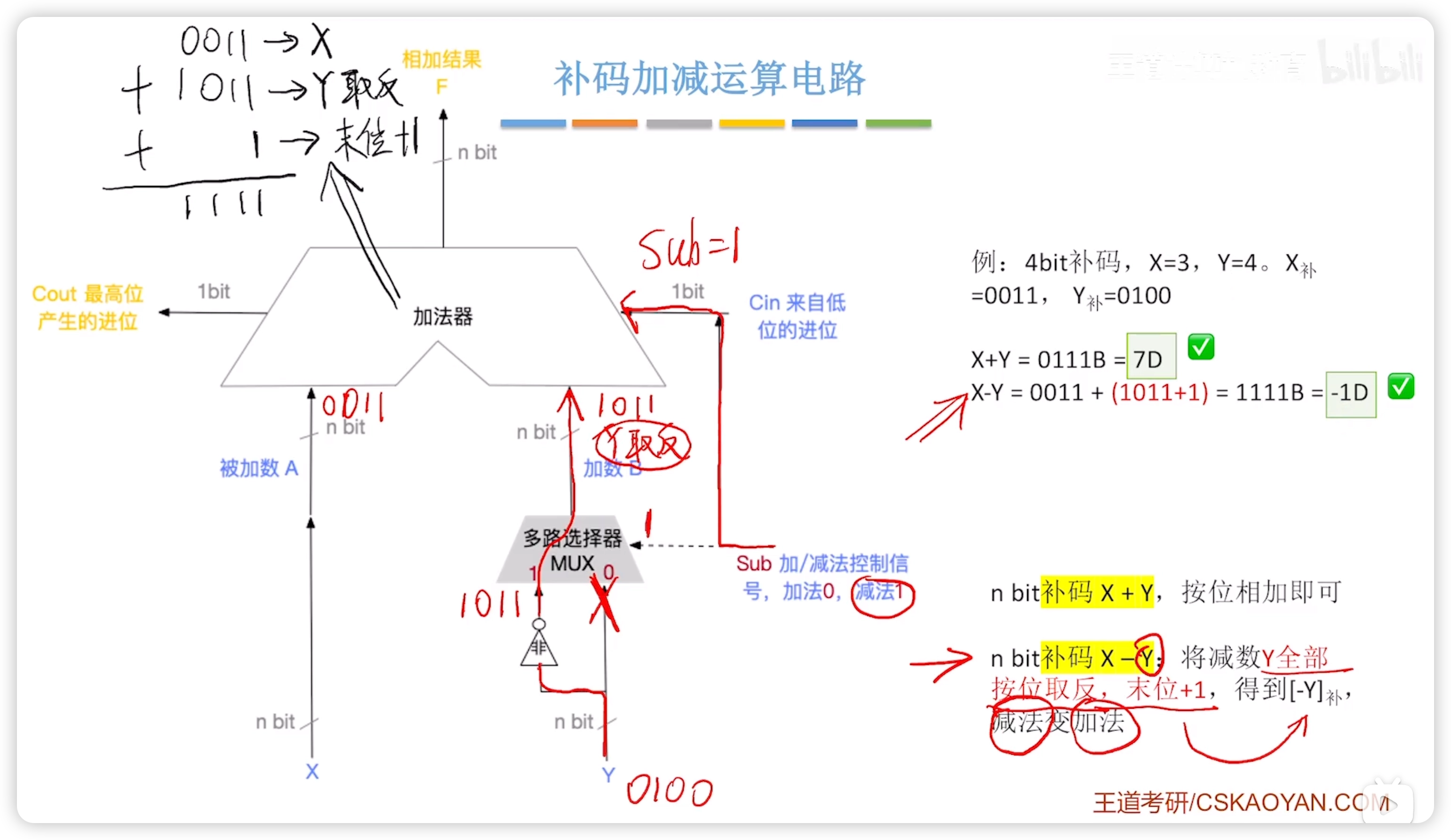
注意,加法器的(加數)輸入端僅取反,加1操作依靠 cin 的進位(sub信號)
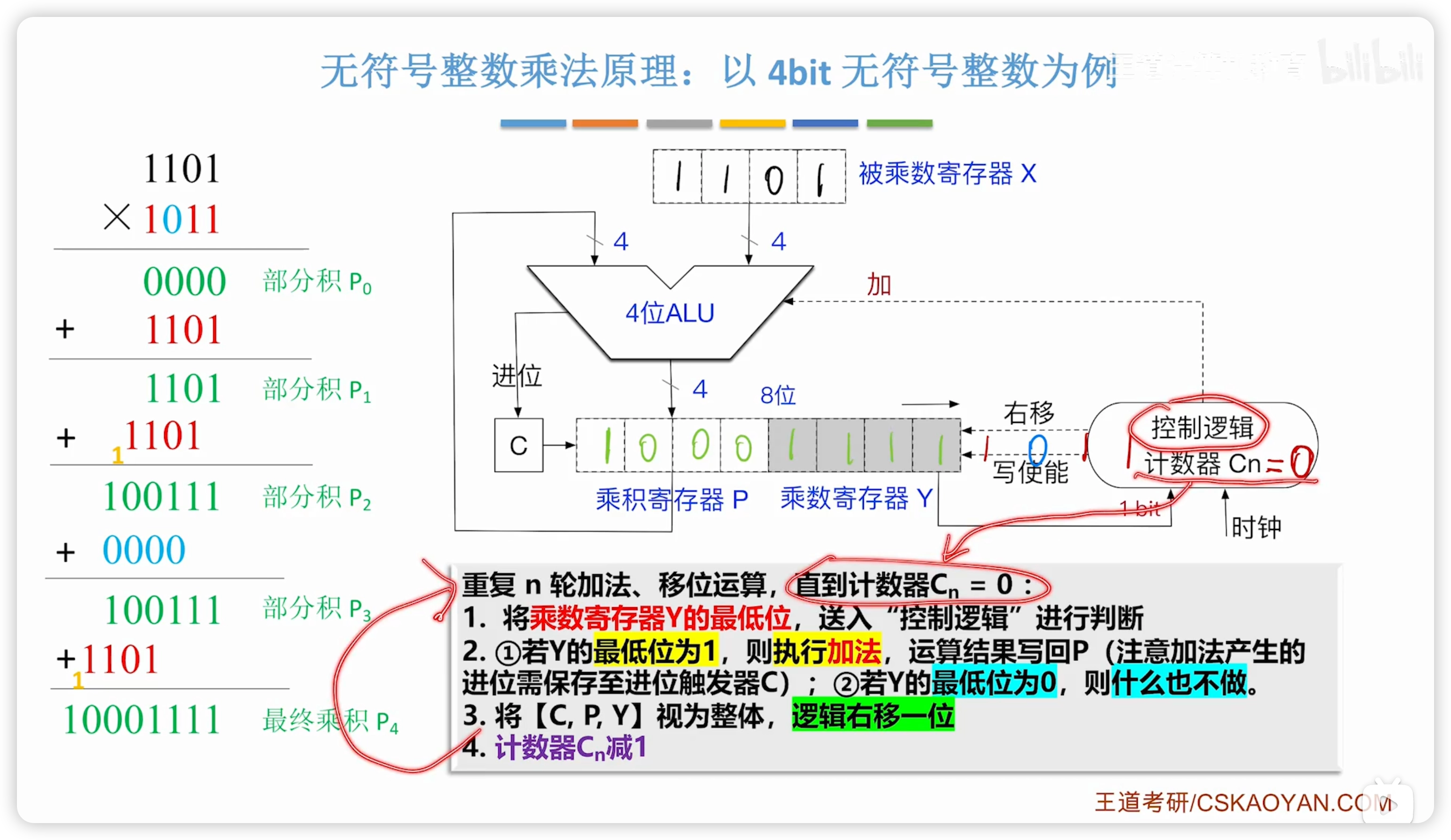
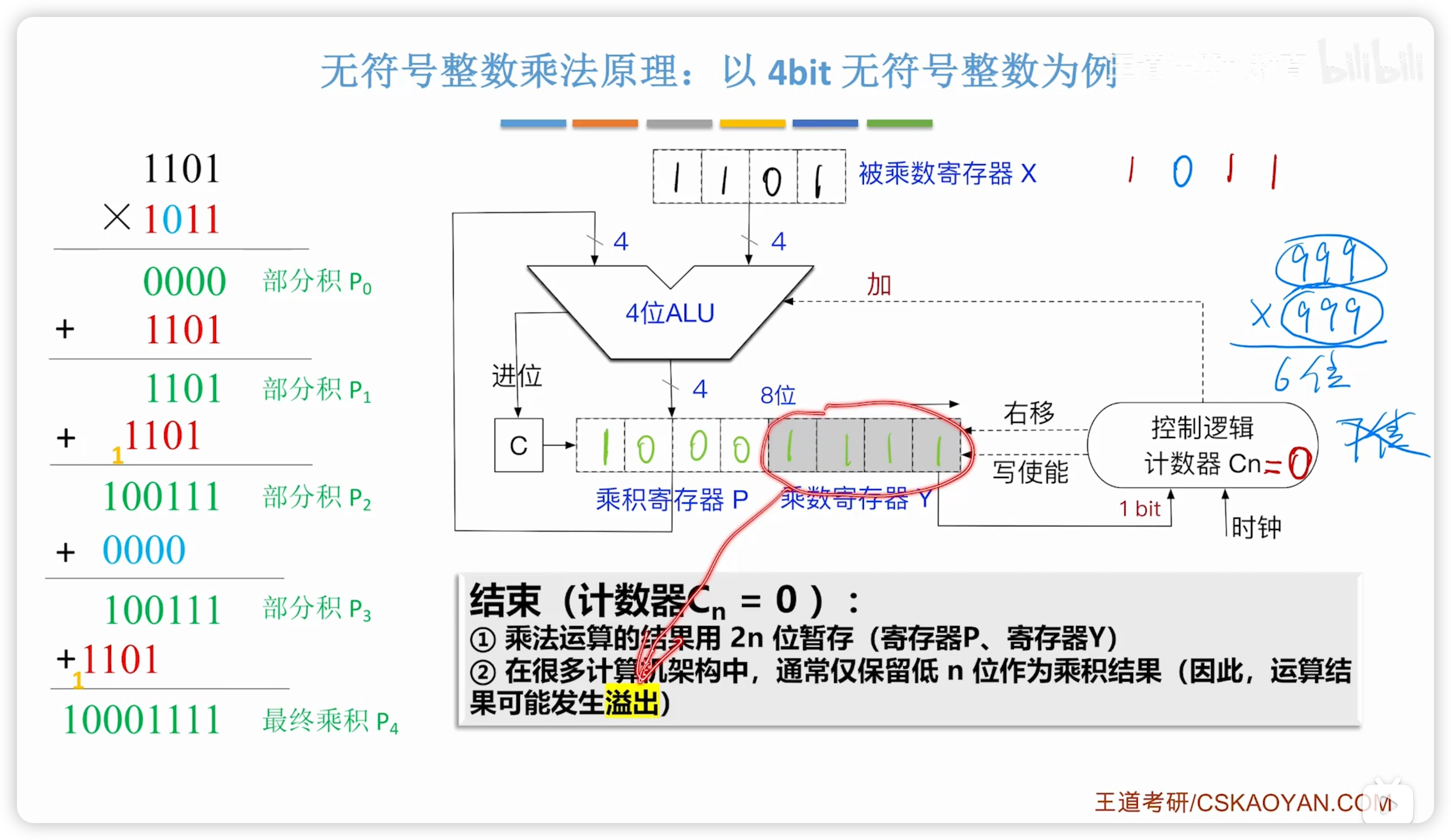
2.2.7 無符號整數的乘法
- 王道說明:考綱側重考察在整數的乘除法,而教材以浮點數的乘除法作為引入
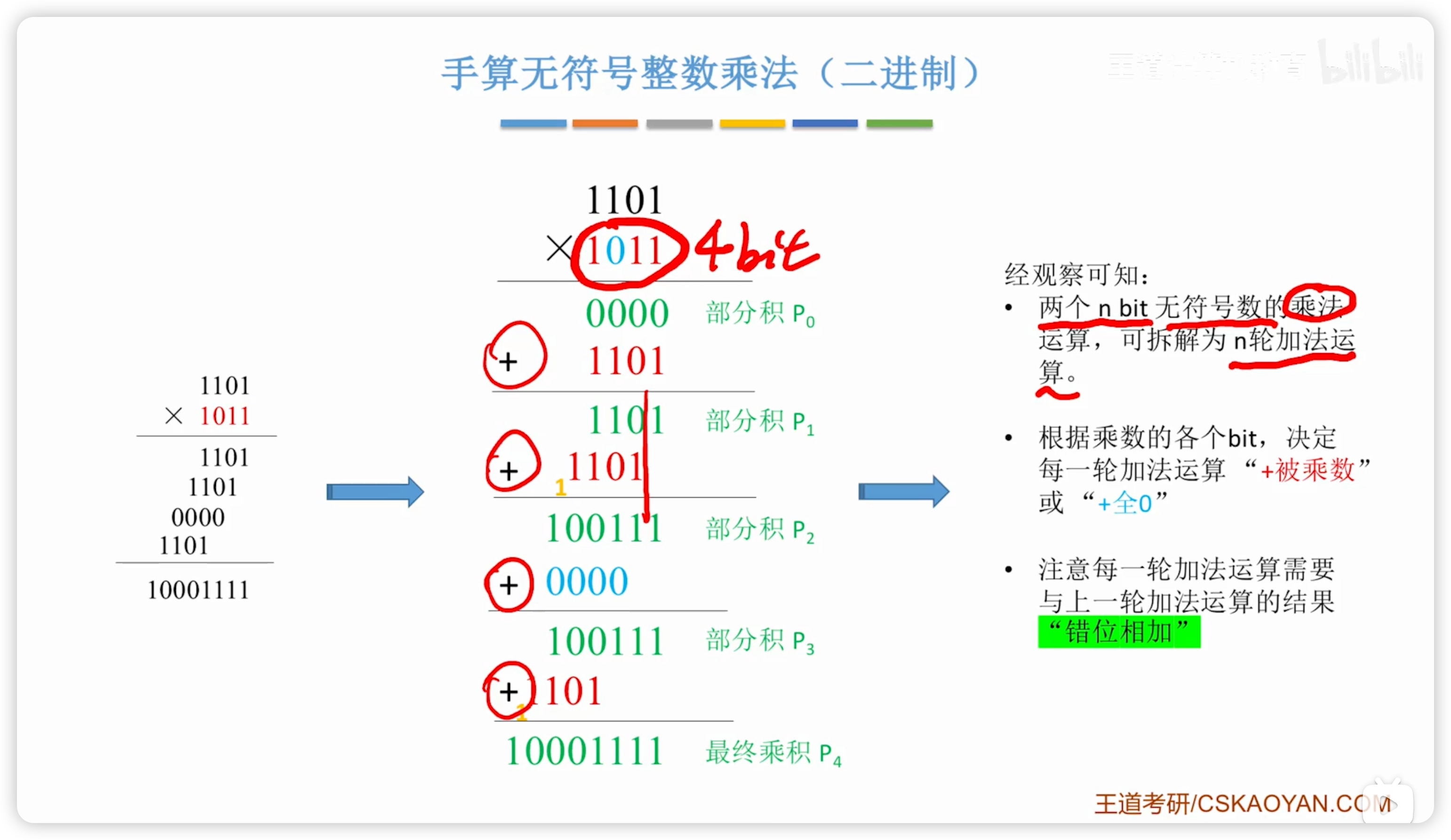
電路
特殊處理:控制邏輯會先檢查兩個是否都是 0,如果是則直接結果為 0
循環:
關於乘法溢出判斷:
- 實際上,P Y寄存器共 2n 位,而兩個 n 位整數乘法結果一定小於 2n,計算過程中是不可能溢出的
- 但是,由於計算機只保留 n 位,所以結果上可能溢出
溢出實例 及 2 種溢出處理:
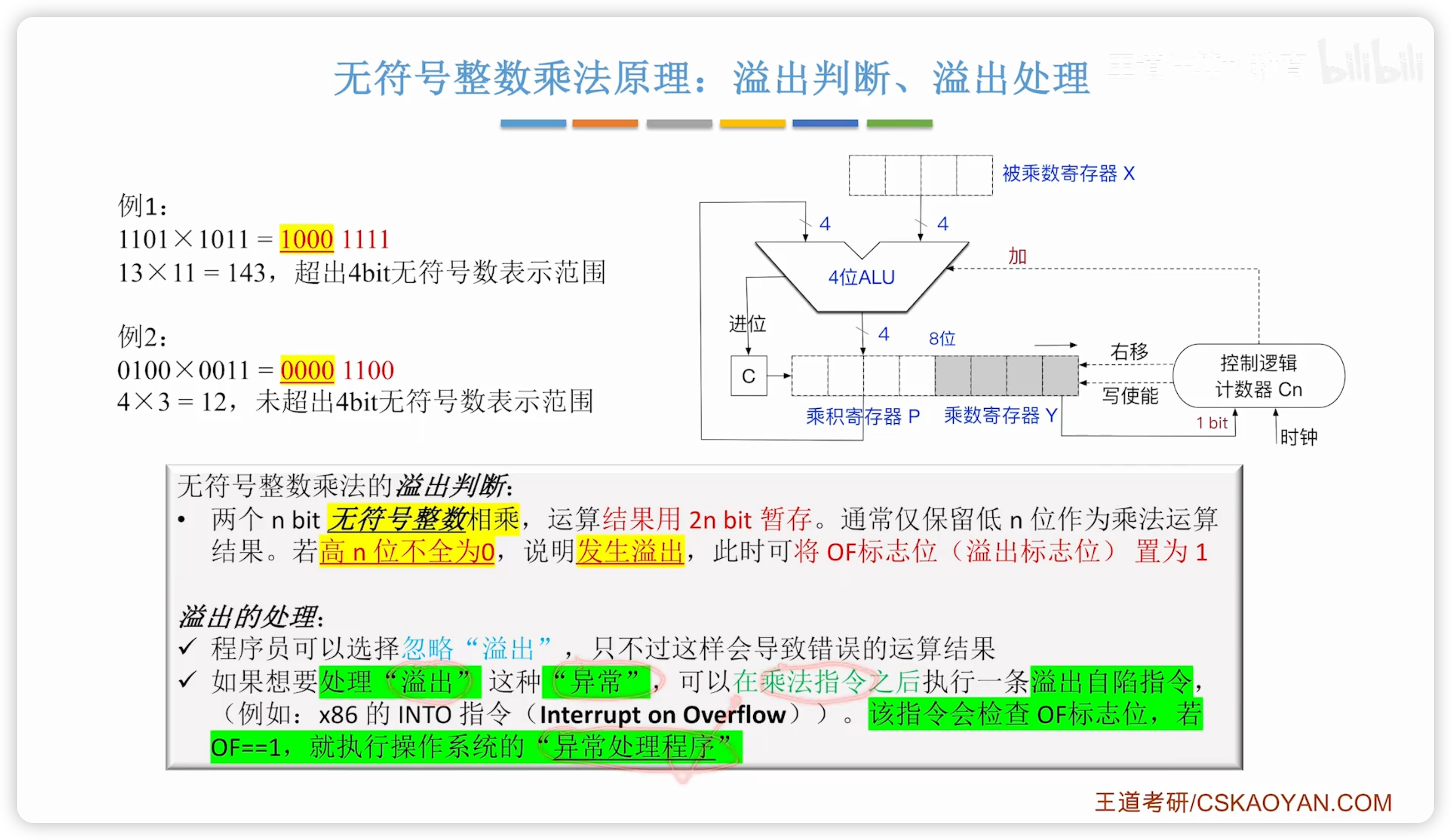
注意:
- 有/無符號整數乘法都是用 OF 標誌位記錄溢出
- 無符號整數乘法時,CF 也會記錄
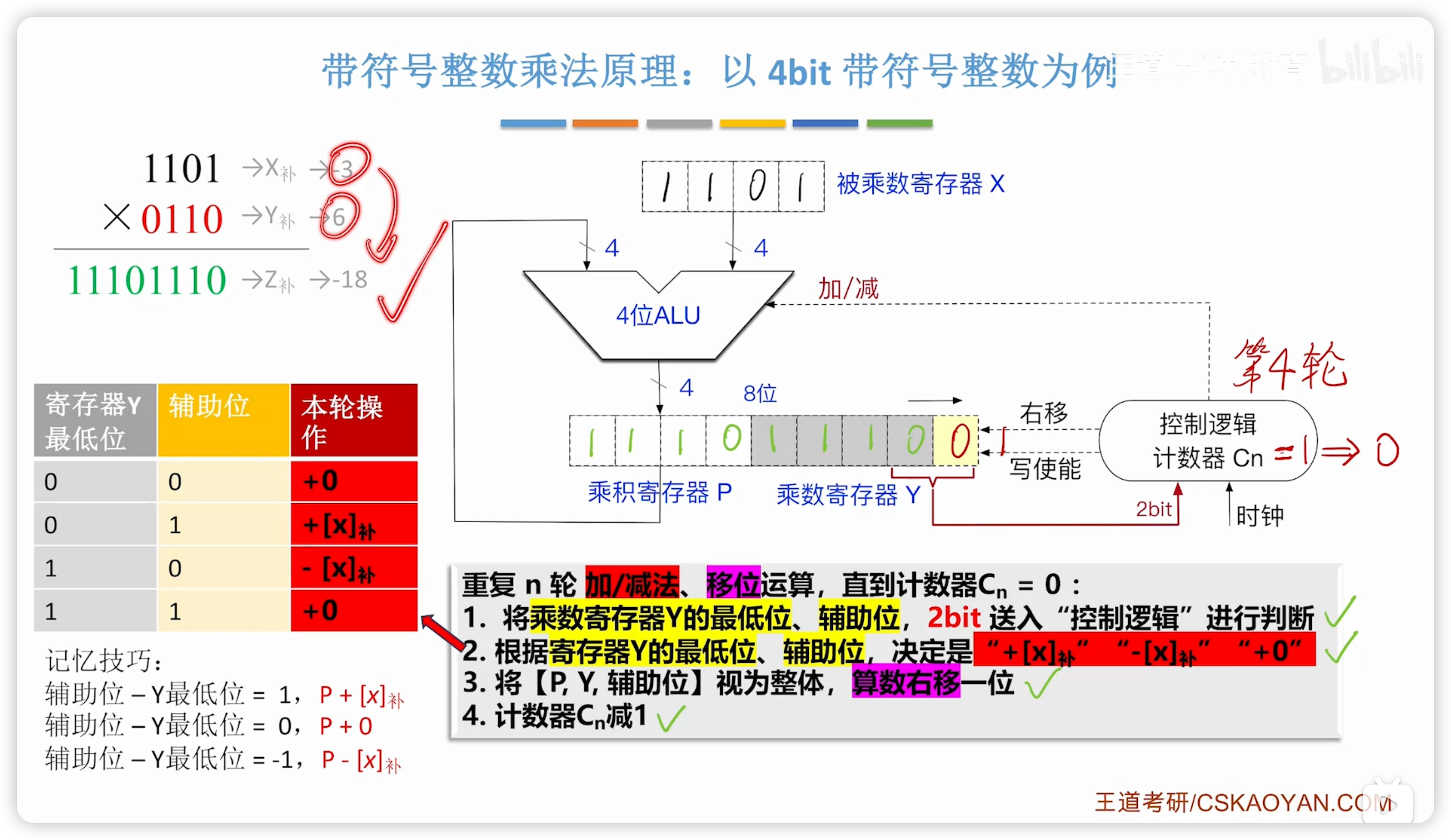
2.2.8 有符號整數的乘法
- 簡單思路是直接算絕對值,符號位異或
- 王道網課用了純電路的方式實現
- 這個方法叫補碼一位乘法,Booth乘法
電路的主要區別是:
- 在最右側添加了輔助位,初始為 0
- ALU 可以執行加減法
- 改為算數右移
另外添加了一個比較繁瑣的規則,見左表:
溢出判斷:
- 檢查高 位是否完全相同
- 不完全相同則溢出
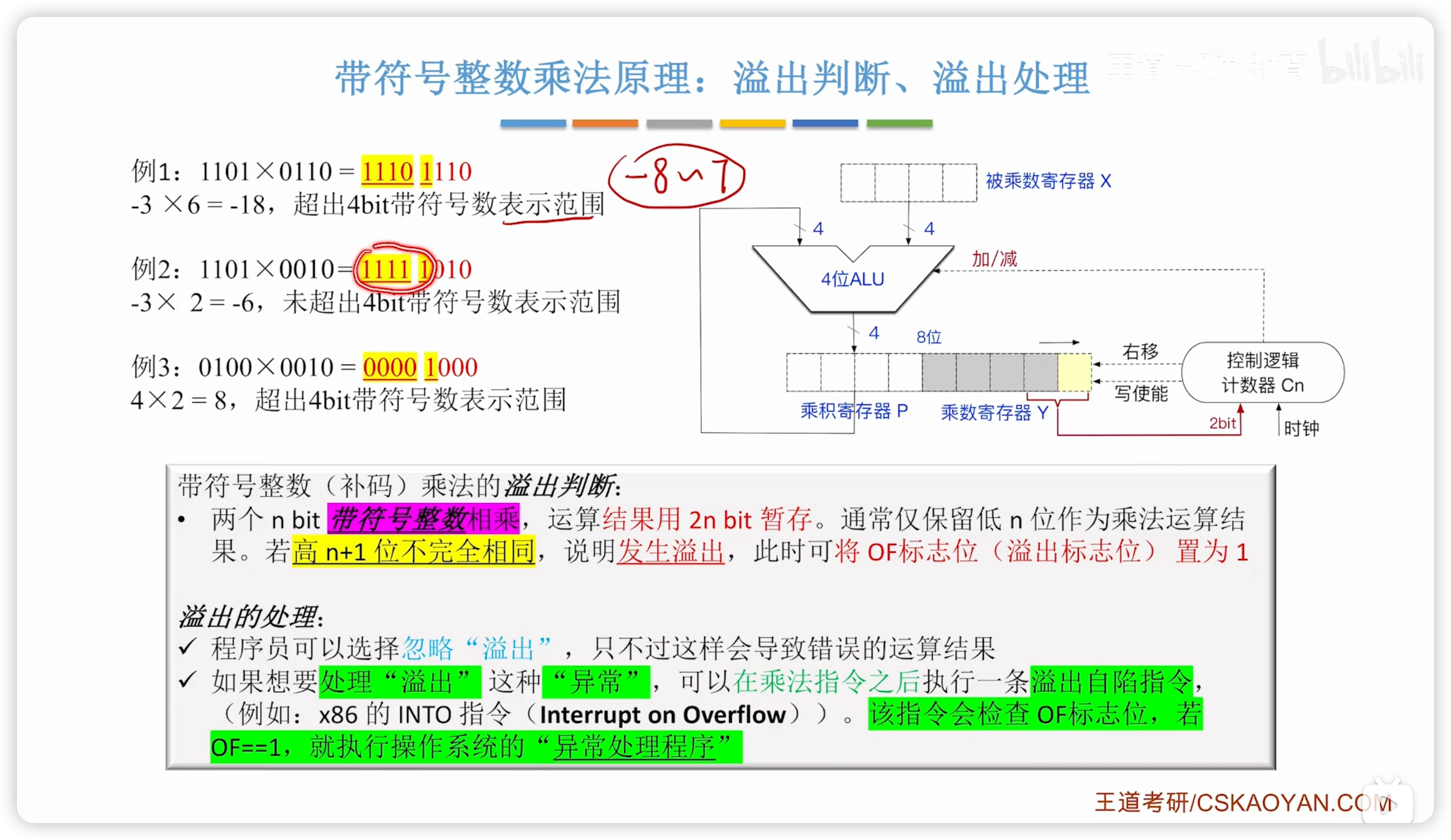
注意,有/無符號整數乘法都是用 OF 標誌位記錄溢出。
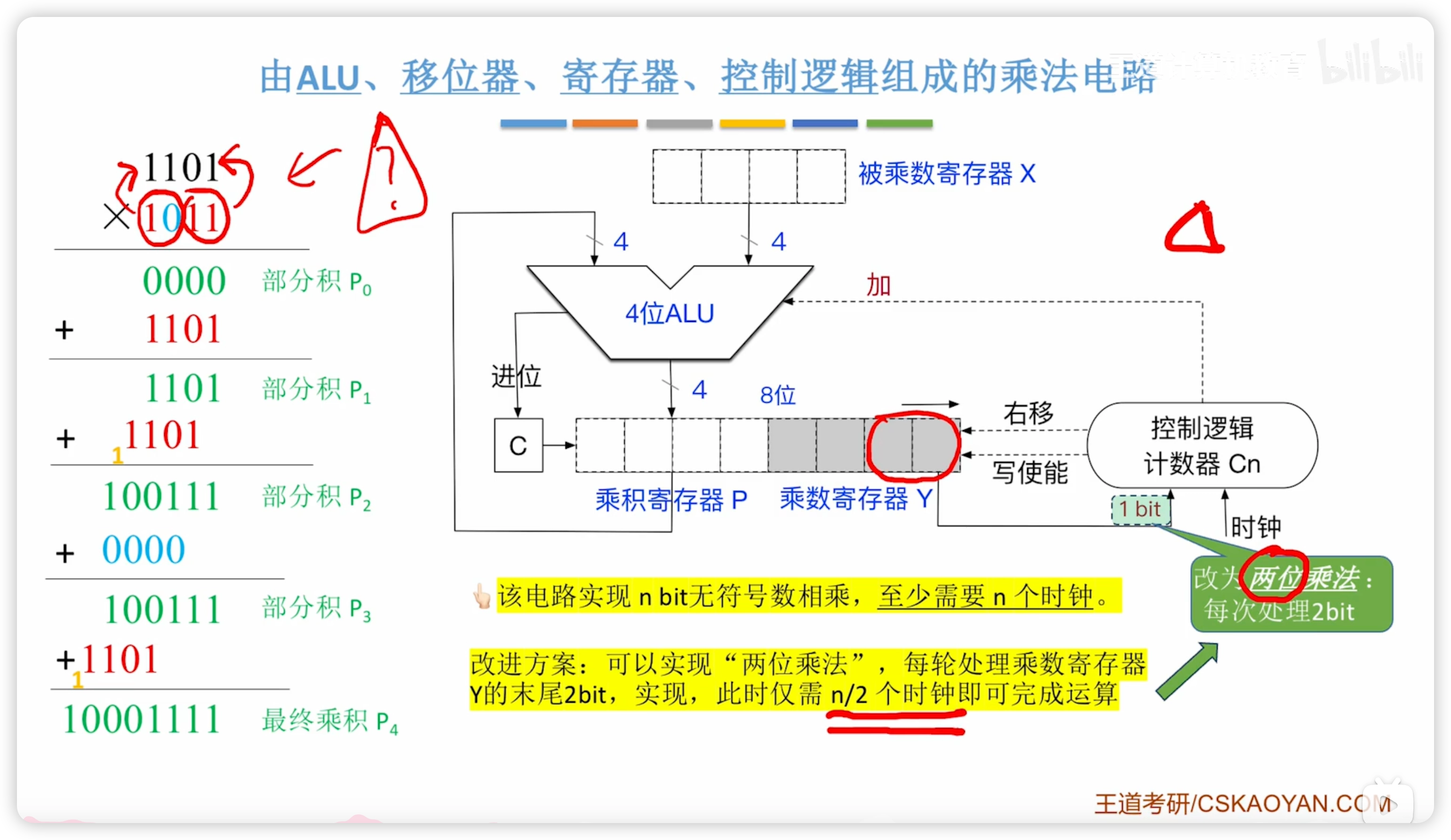
2.2.9 計算機實現乘法電路的三種方式
上一節的電路實現 n bit 無符號數相乘,至少需要 n 個時鐘。
兩位乘法
改進方案:可以實現“兩位乘法”,每輪處理乘數寄存器Y的末尾2bit,實現,此時僅需 n/2 個時鐘即可完成運算
- 具體如何實現兩位乘法沒有深入
陣列乘法器
- 快速乘法器
可以在 1 個時鐘內完成乘法運算
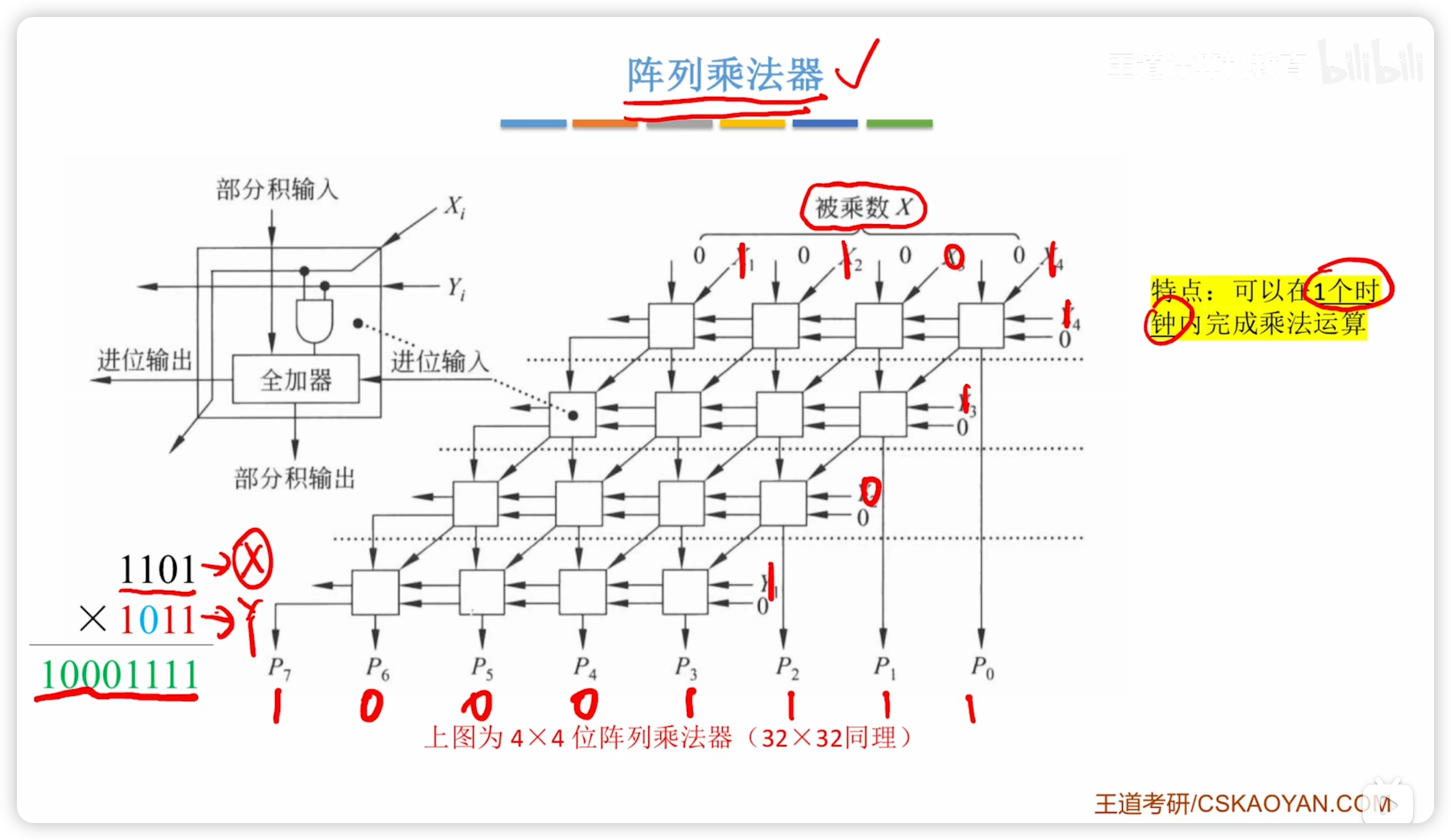
邏輯運算等效
運算速度很慢

總結
- 速度:陣列 > ALU移位 > 邏輯等效
- 本節的三種方法,對於有無符號整數都適用
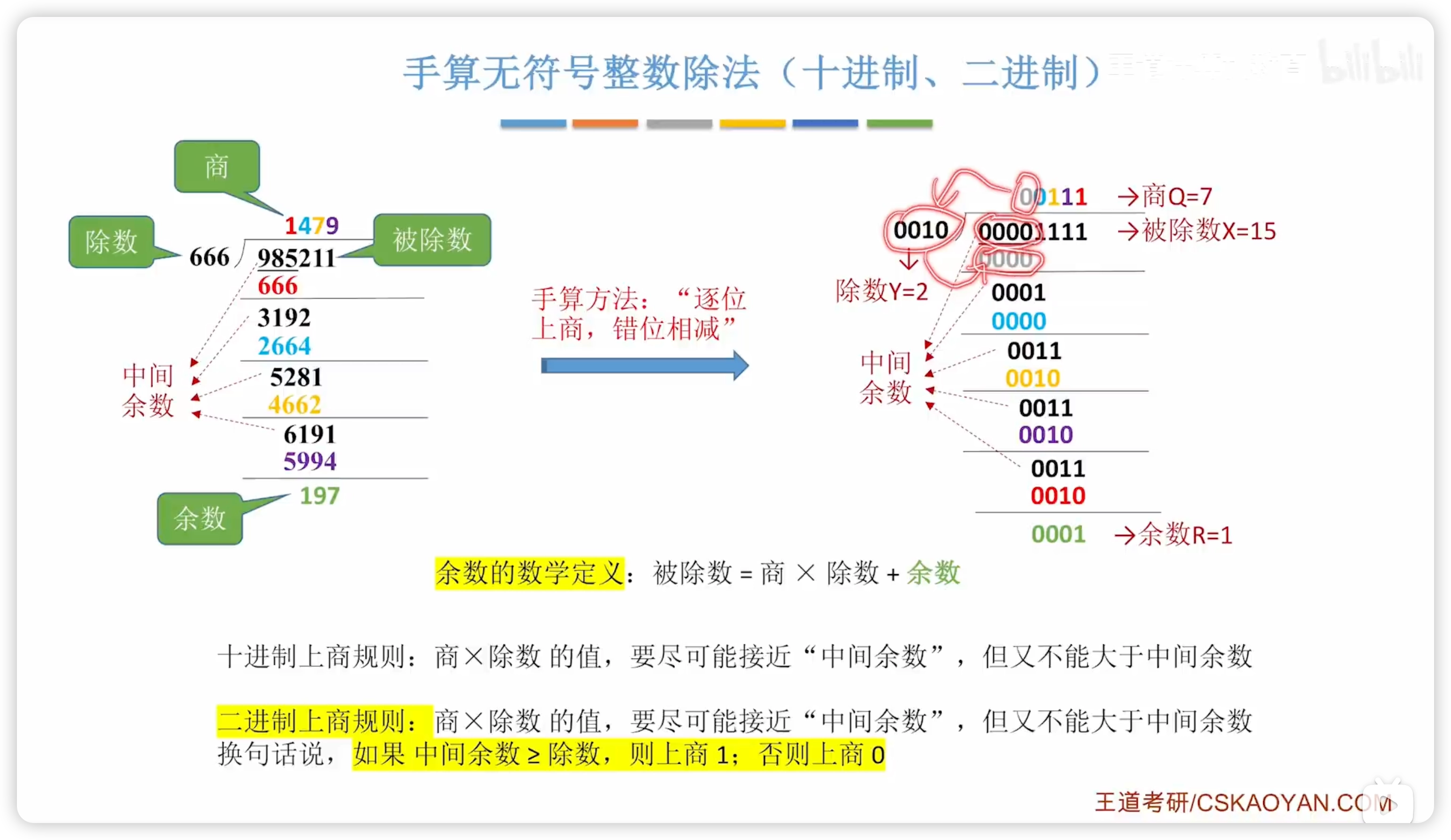
2.2.10 無符號整數的除法運算
- 除法異常包括:商溢出、除數0
手算
二進制和十進制差不多,很簡單
除法電路
被除數作零拓展
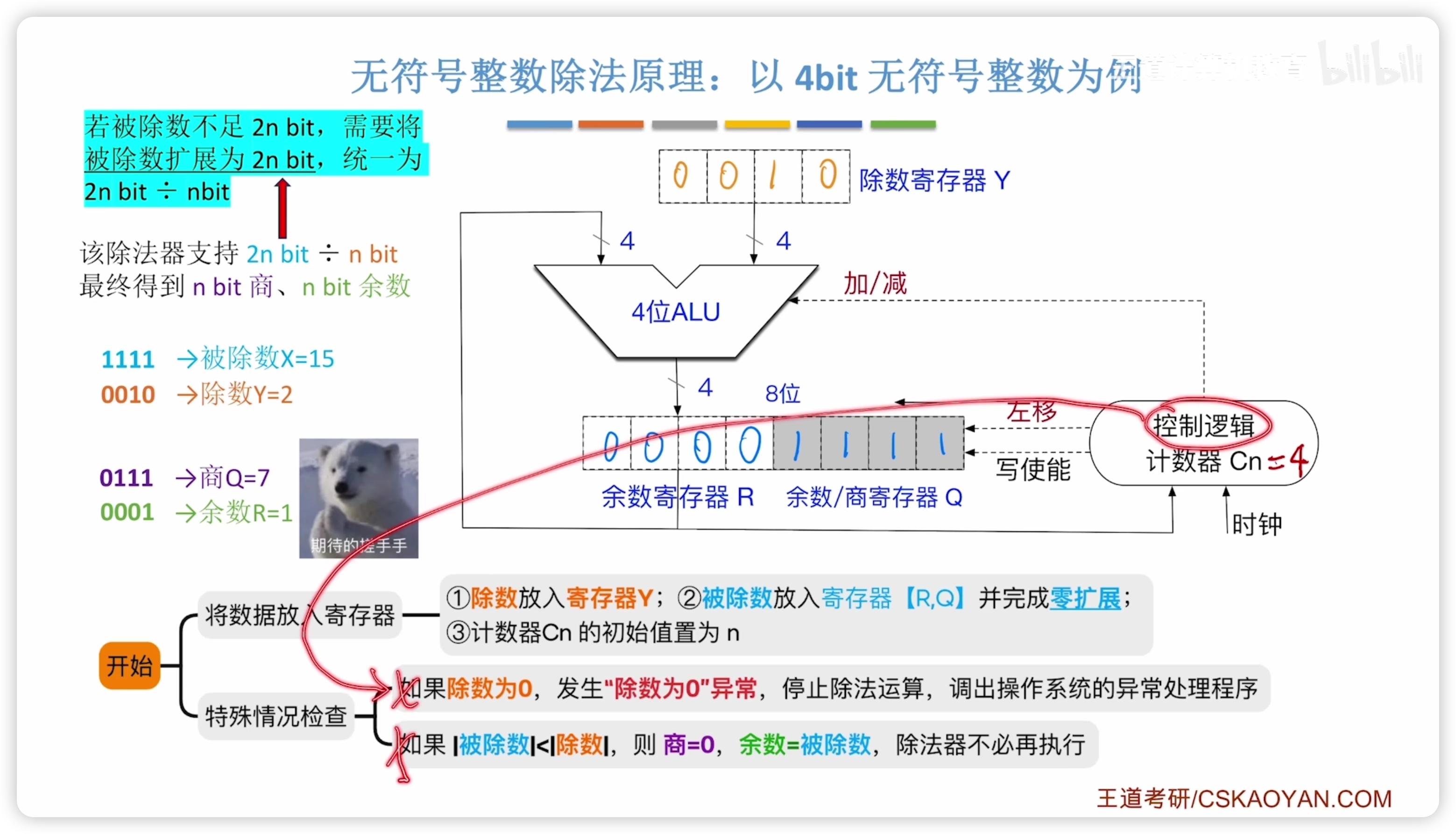
特殊情況:
- 除數 = 0,異常停止
- 被除數 < 除數,商 = 0
具體過程:
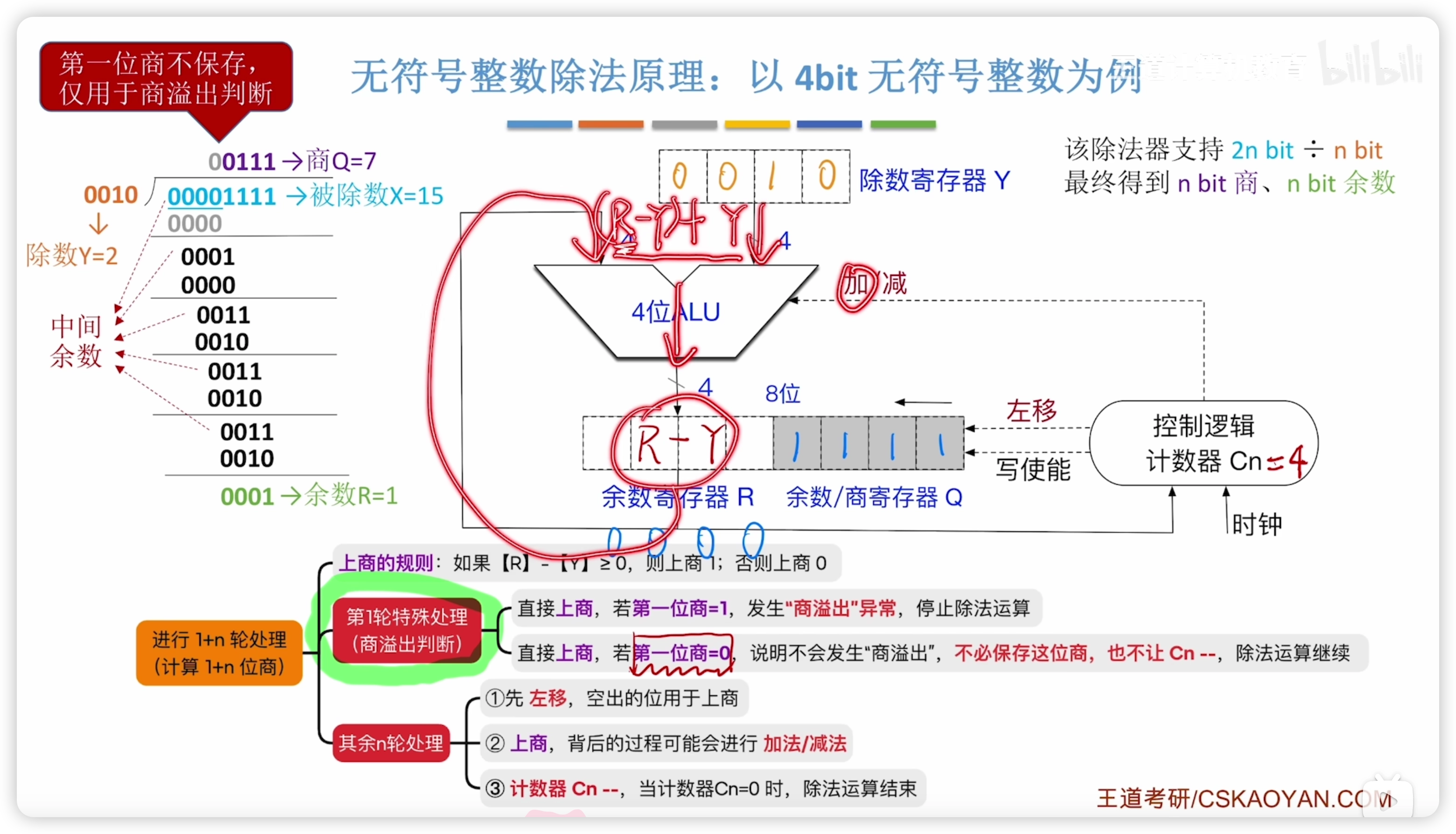
- 判斷商溢出:看第一位商(第一輪特殊處理)
- 1,則商溢出異常,停止
- 由於默認高4位填充 0,
- 所以 n 除 n 時(單精度)不可能商溢出,
- 2n 除 n 時(雙精度)可能溢出,
- 這一點商溢出小節有提到。
- 0,則這次計算不可能發生溢出
- 1,則商溢出異常,停止
- 有關ALU加法操作:
- 上商 0 的時候,ALU實際上還是做了 的操作(發現小於 0 才判斷上商 0),所以需要做一次 的操作,使得餘數恢復為正確的值,之後再左移。
- 所以,ALU實際上的過程和手算的中間餘數不一樣,手算是人腦判斷之後直接
- 稱作恢復餘數法
商溢出
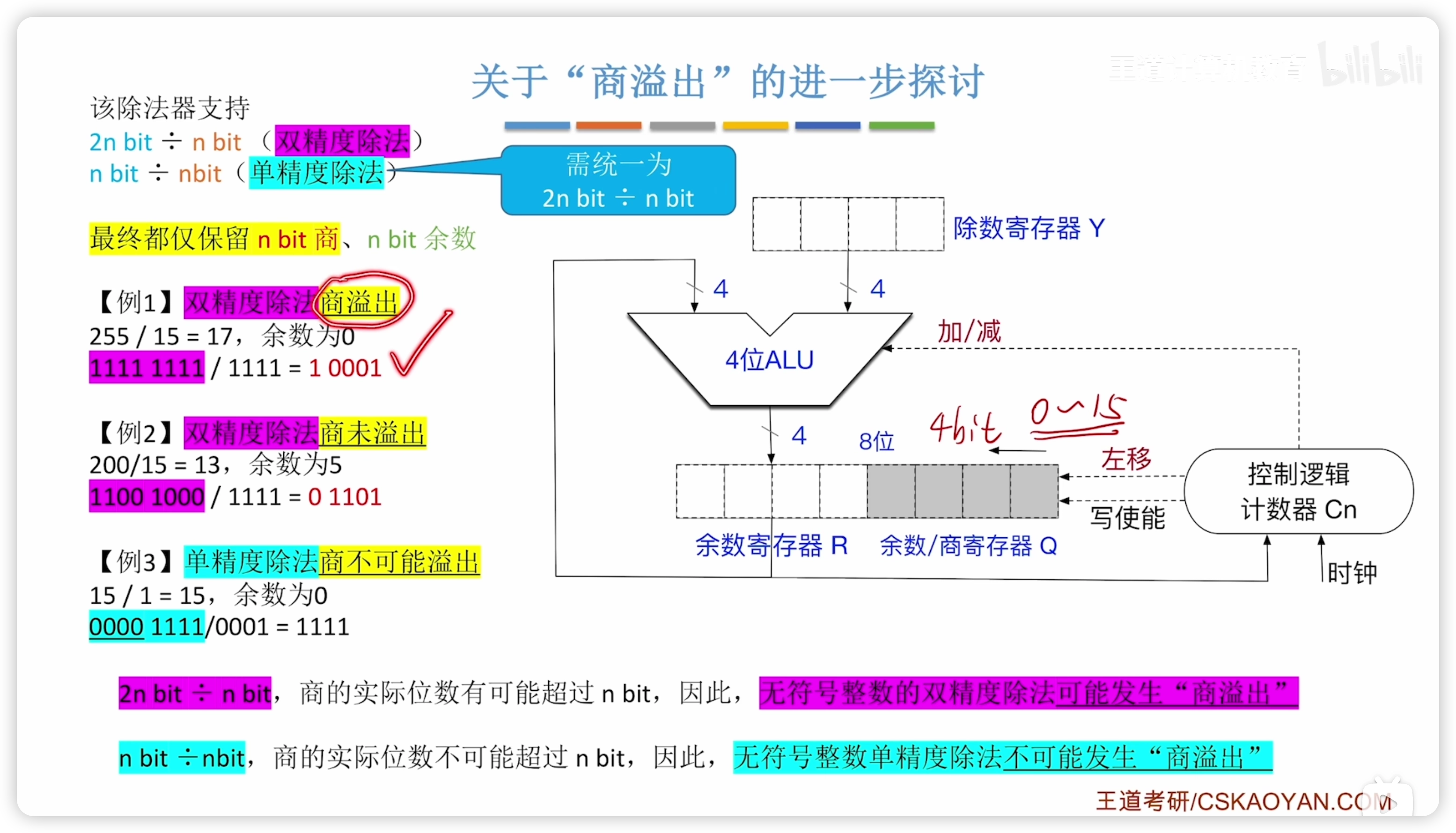
按被除數 n/2n 分為單雙精度
- 雙精度可能溢出
- 單精度不可能溢出
2.3 浮點數
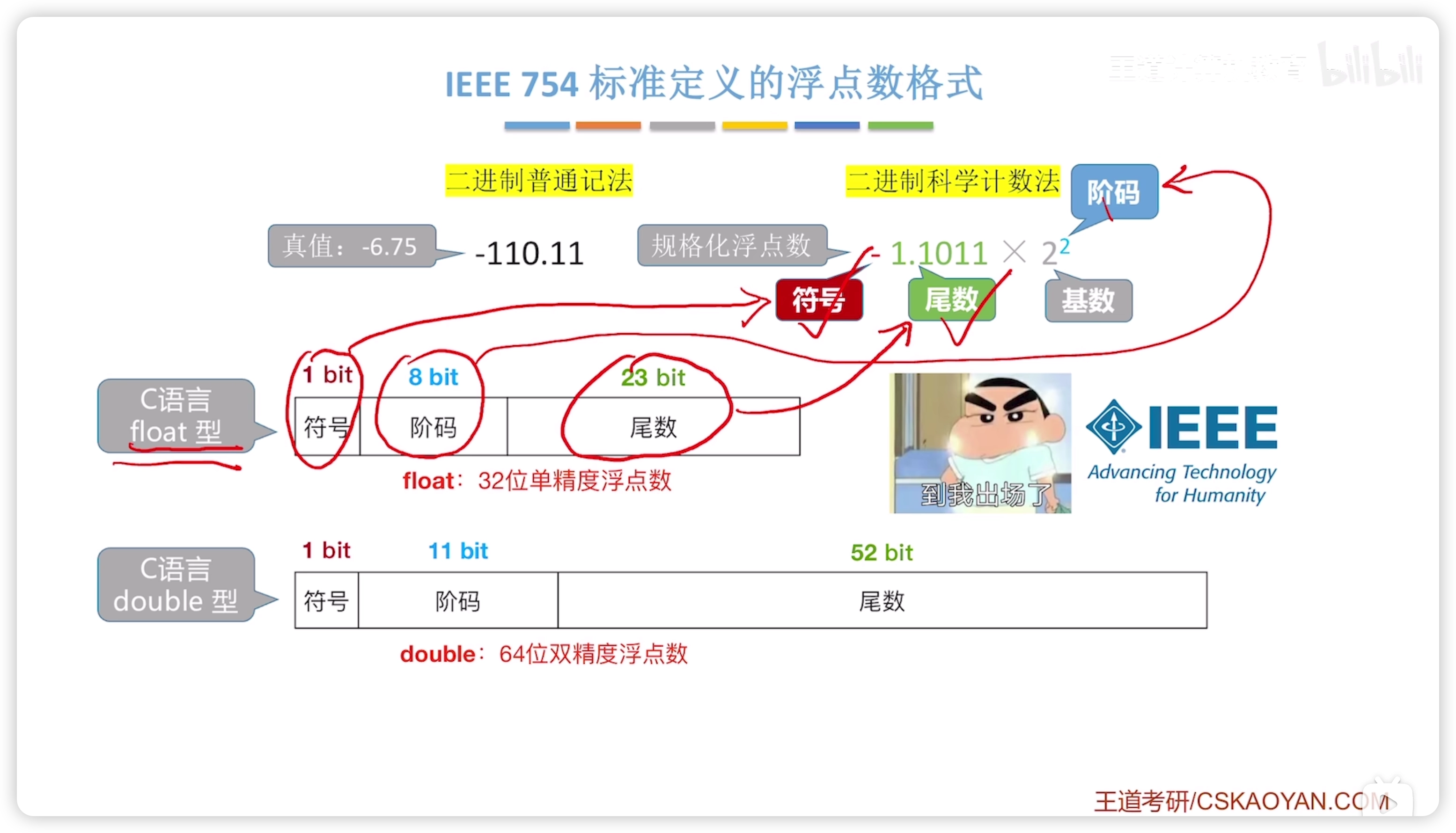
2.3.1 IEEE 754
- 二進制浮點數算數標準
C語言的 float(單精度 32bit)、double(雙精度 64bit)就是符合 IEEE 754 標準的浮點數格式。
二進制科學計數法
- 引入 符號、尾數、基數、階碼的概念
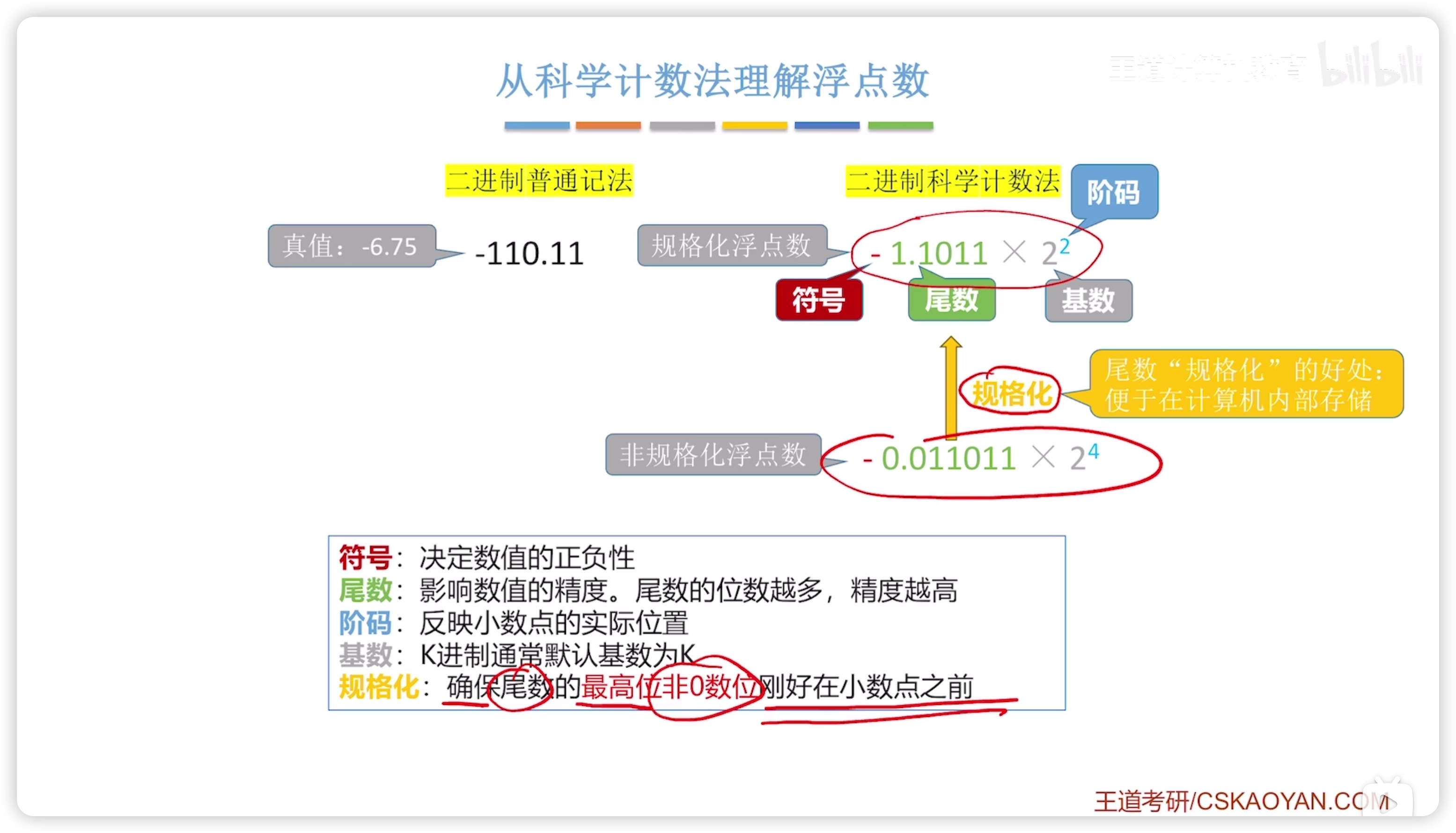
浮點數由 符號、階碼、尾數 組成
- 尾數的位數決定了精度
- 階碼的位數決定了表示範圍
float 的存儲
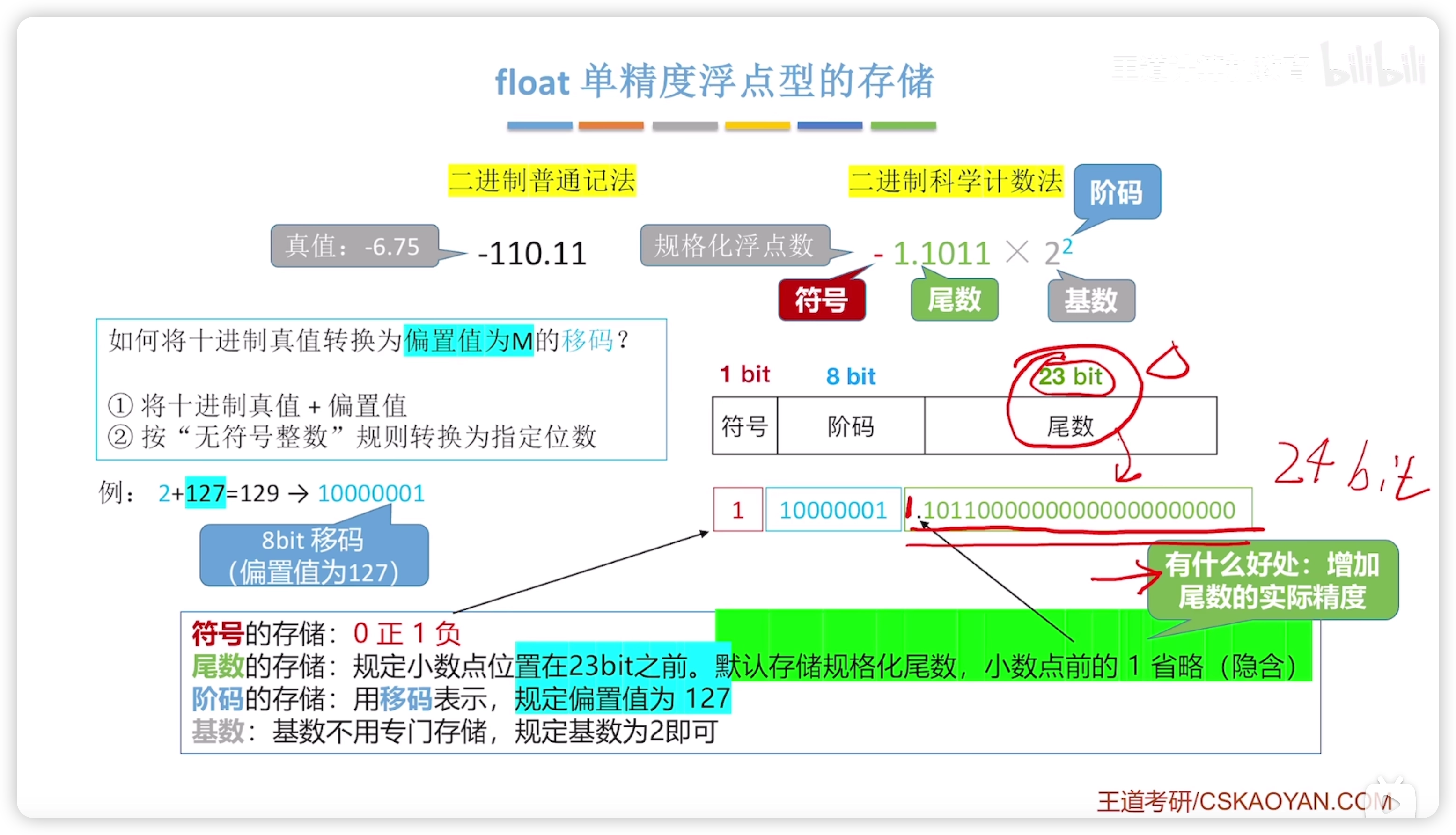
- 尾數省略了小數點前的 1(但是尾數概念本身包含這個 1),省略是因為這是隱含的,不用浪費空間表示;所以,實際上 23 bit 表示的是 24 bit 的精度。
- 如何求移碼:十進制 + 偏置值,轉為二進制
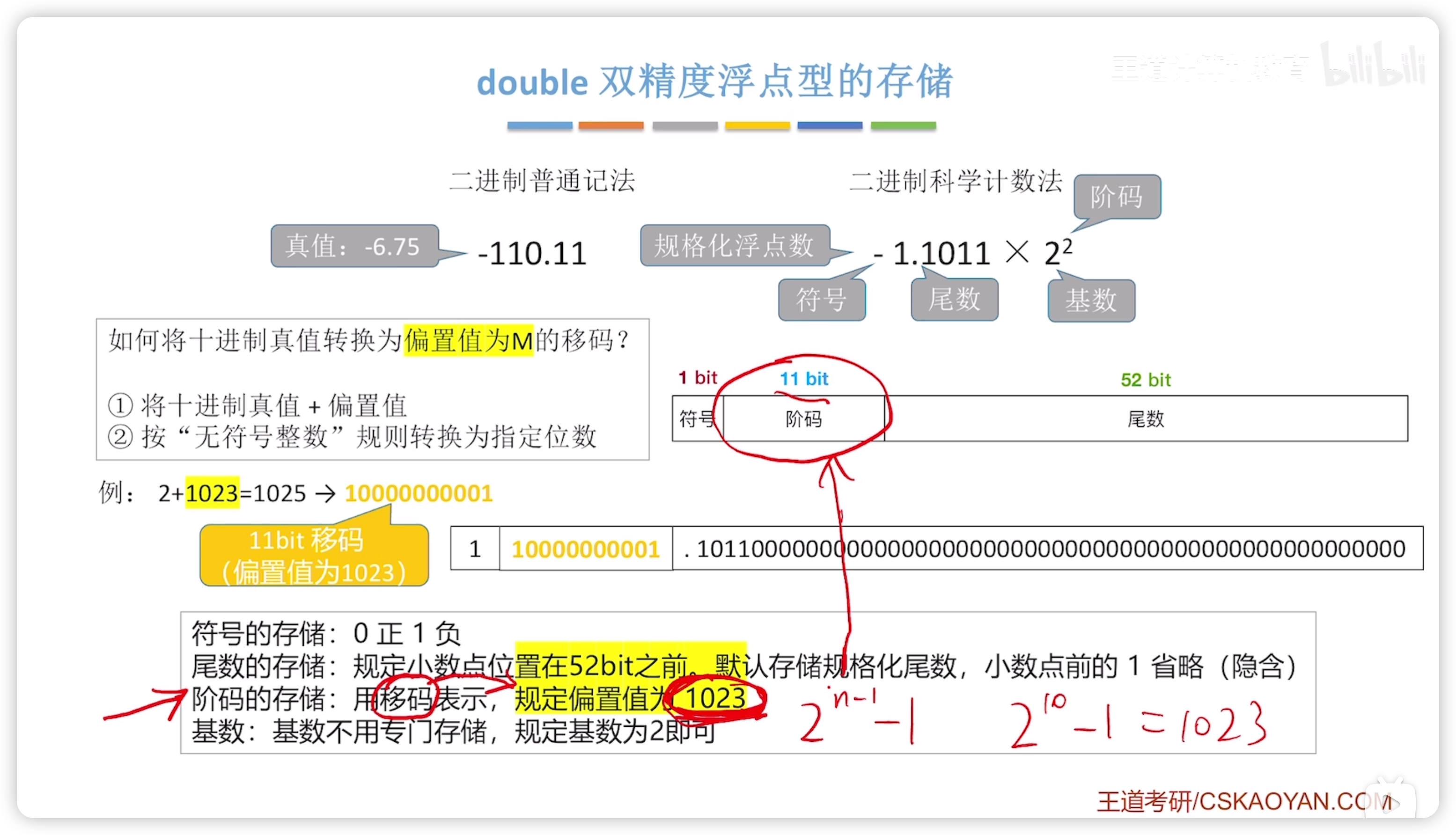
double 的存儲
基本一致,注意記憶偏置值
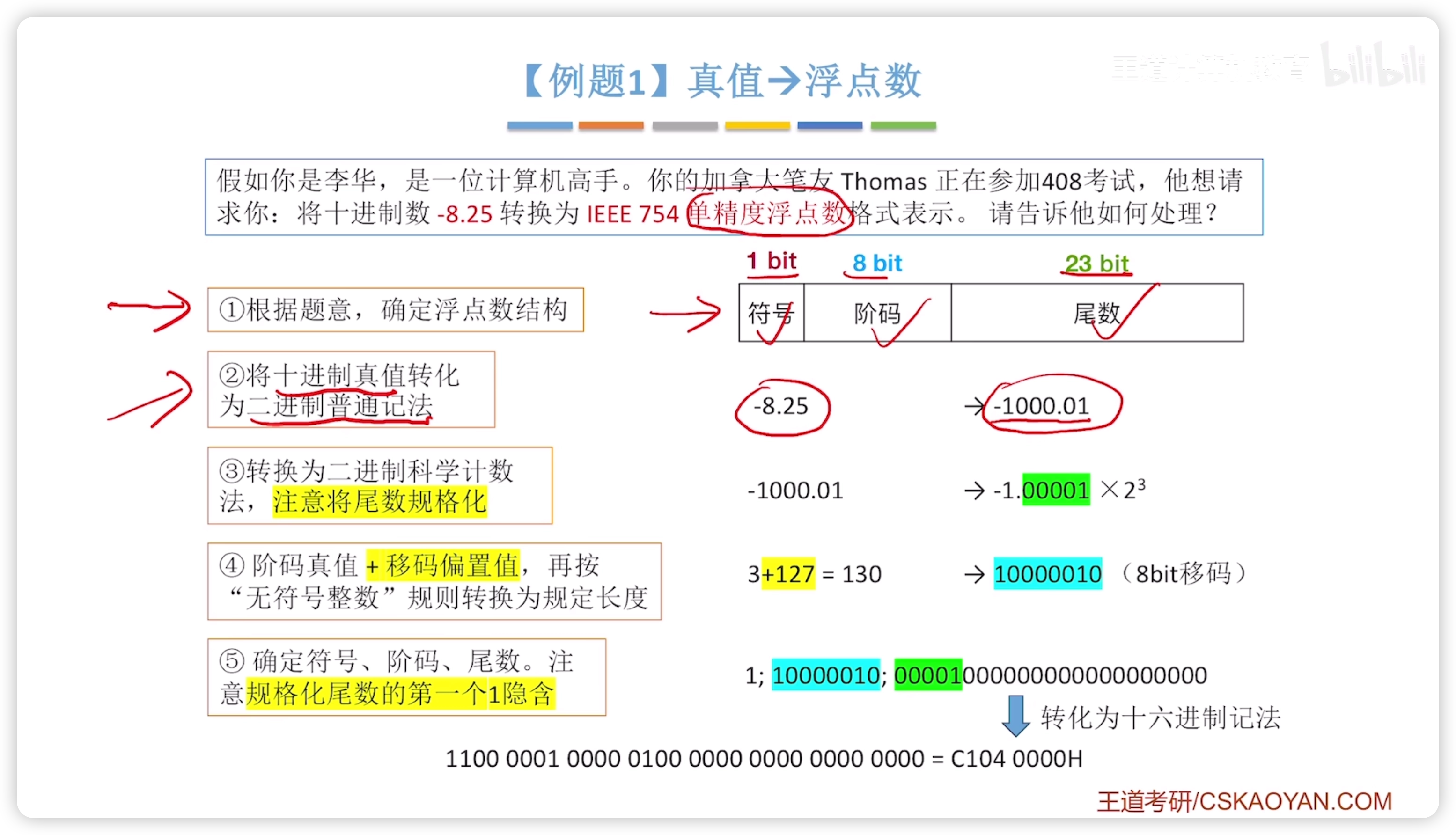
例題
2.3.2 浮點數表示範圍
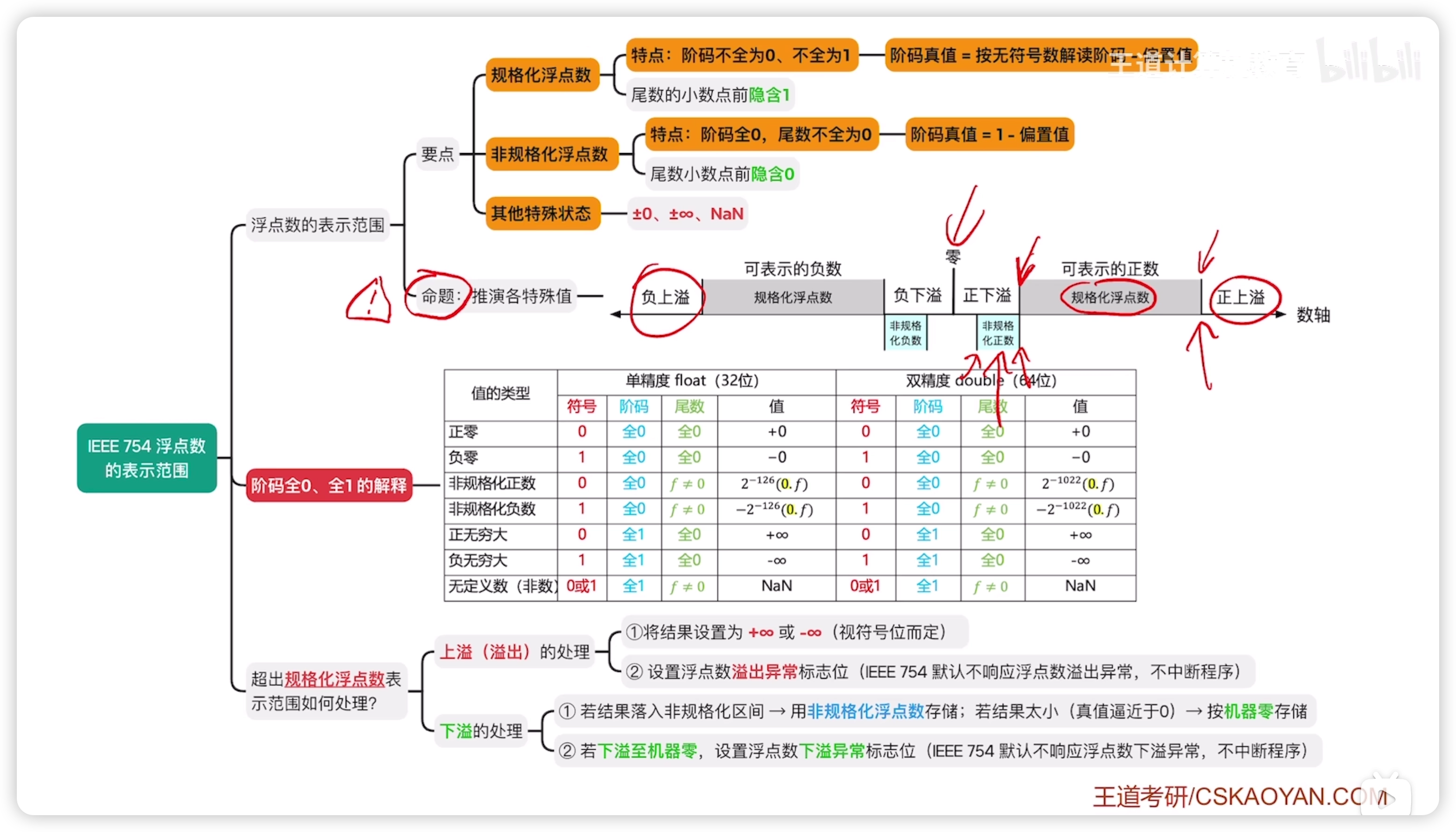
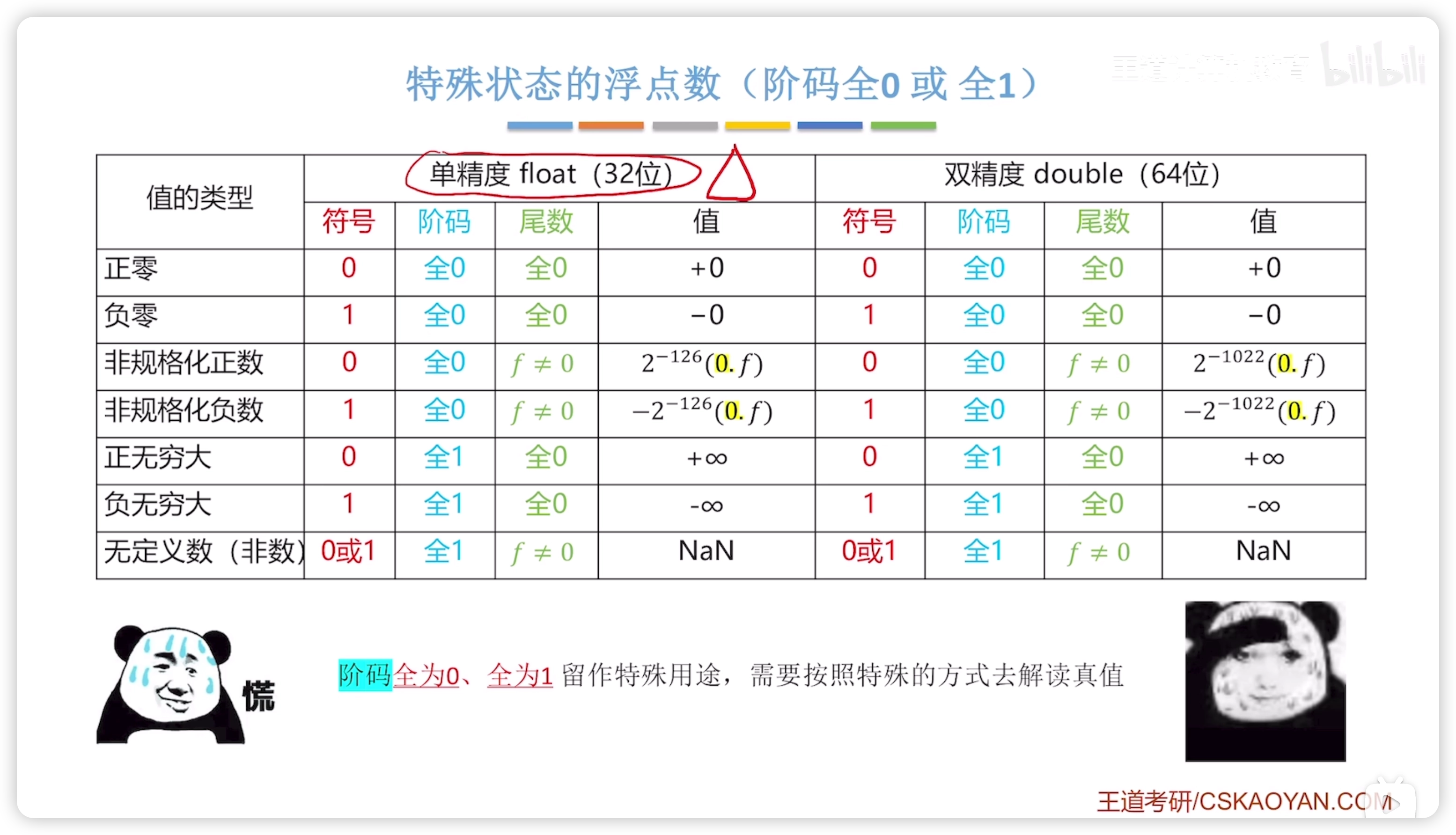
特殊狀態的浮點數
- 階碼全 0 / 1,視為特殊狀態
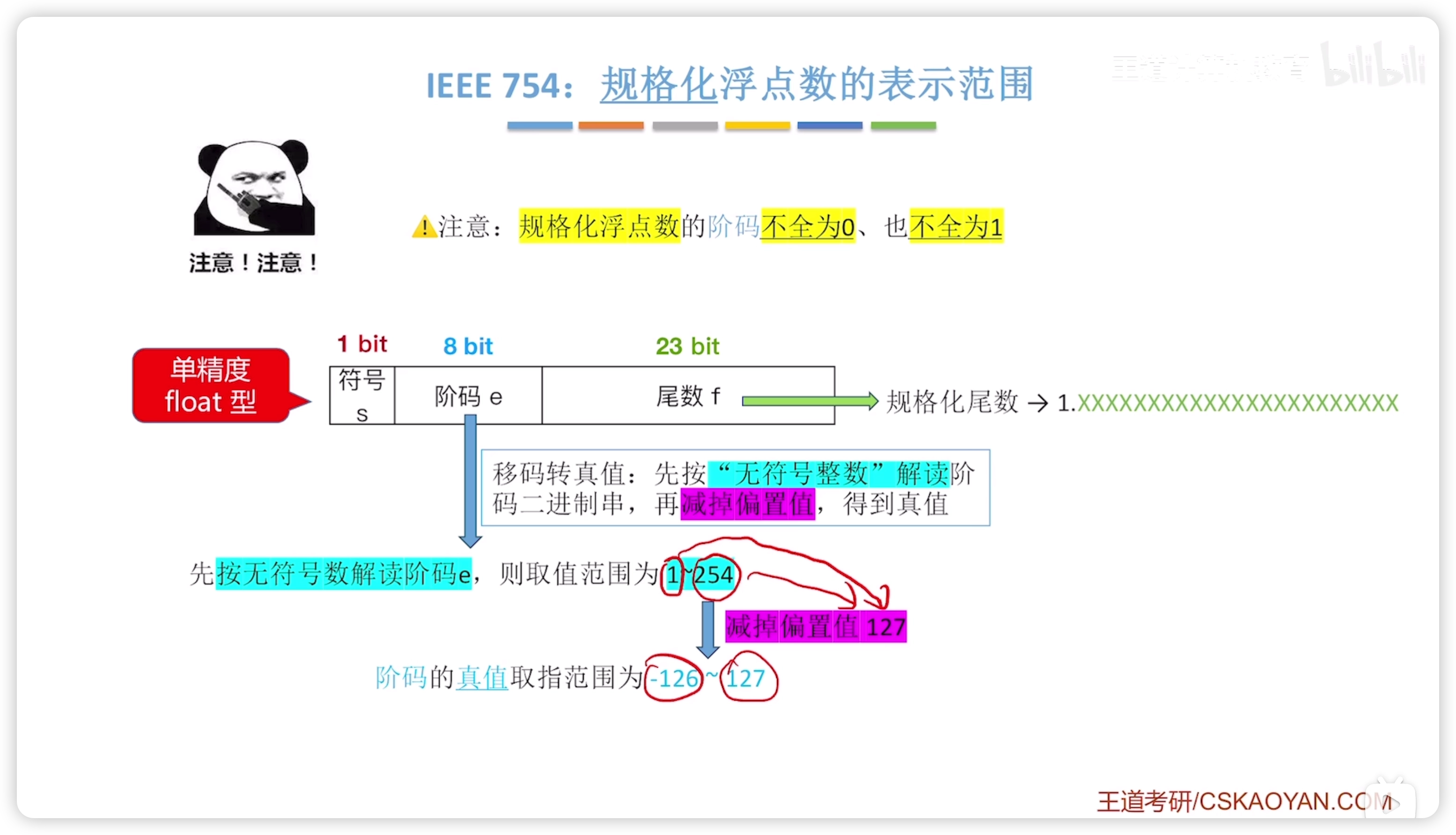
規格化浮點數
- 注意,規格化的階碼不存在全 0 / 1
float 階碼真值表示範圍:
float 規格化浮點數表示範圍:
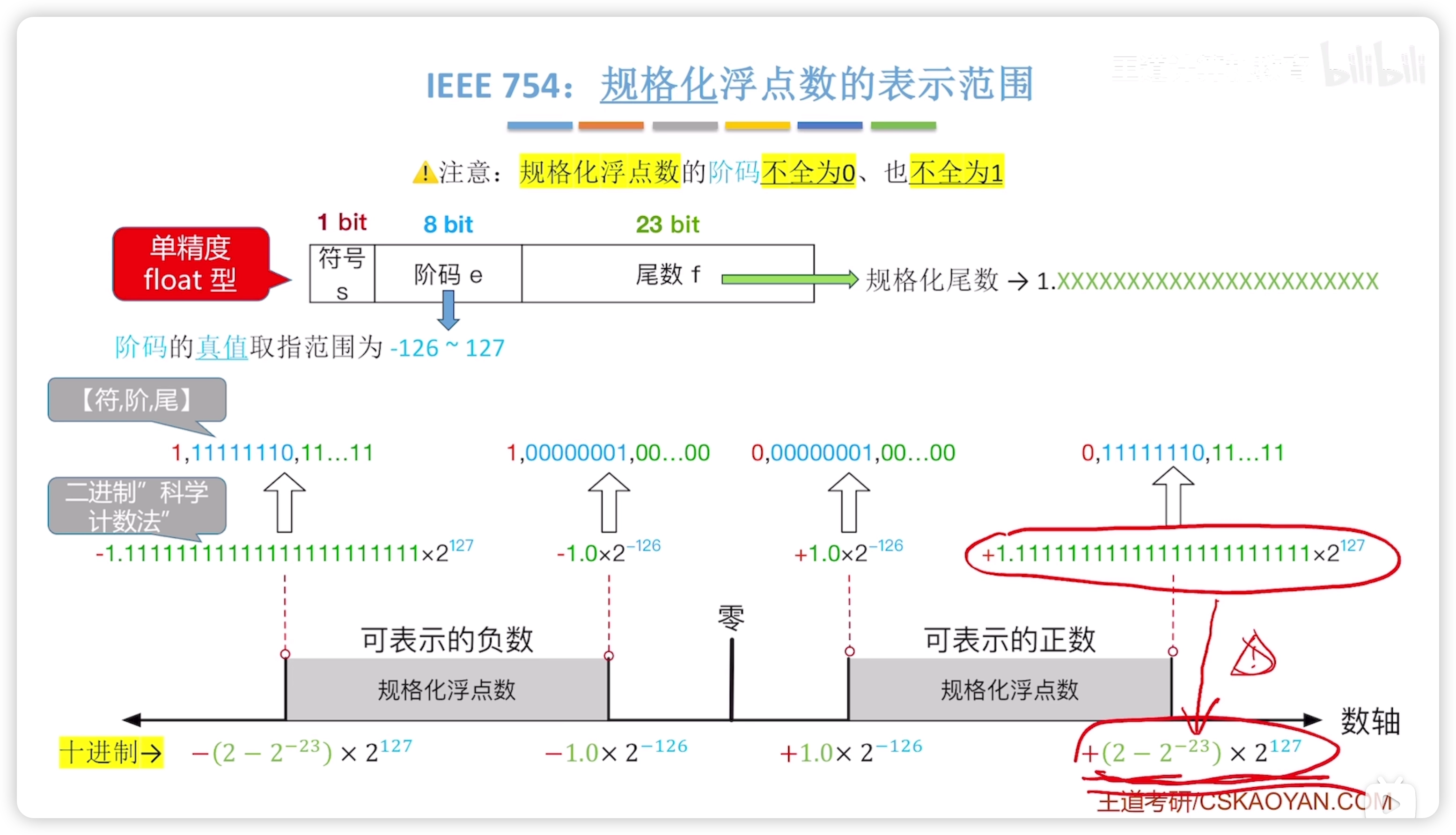
- 理解 : 是尾數第23位
- 正負是對稱的,注意,表示範圍不包括 0
其實從這個圖也可以理解:
- 階碼全 1 (127+1)表示無窮大
- 階碼全 0 (-126-1)表示零
- 注意,127、-126是移碼
- 移碼轉換:
- 127 是 127+127=254;
- 127+1 是 128+127=255;
- 255 是 全 1
- 移碼轉換:
下溢處理
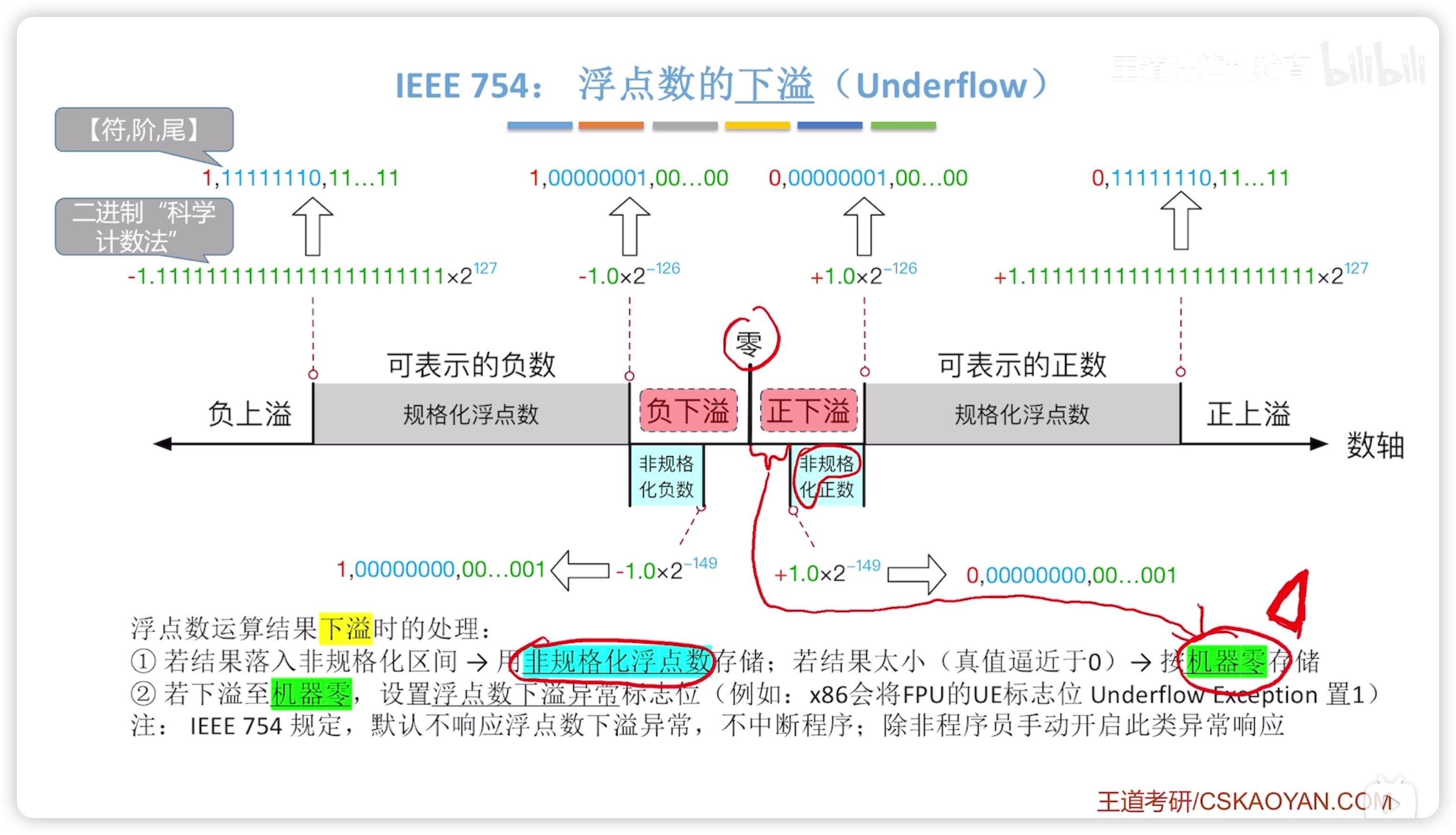
非規格化浮點數
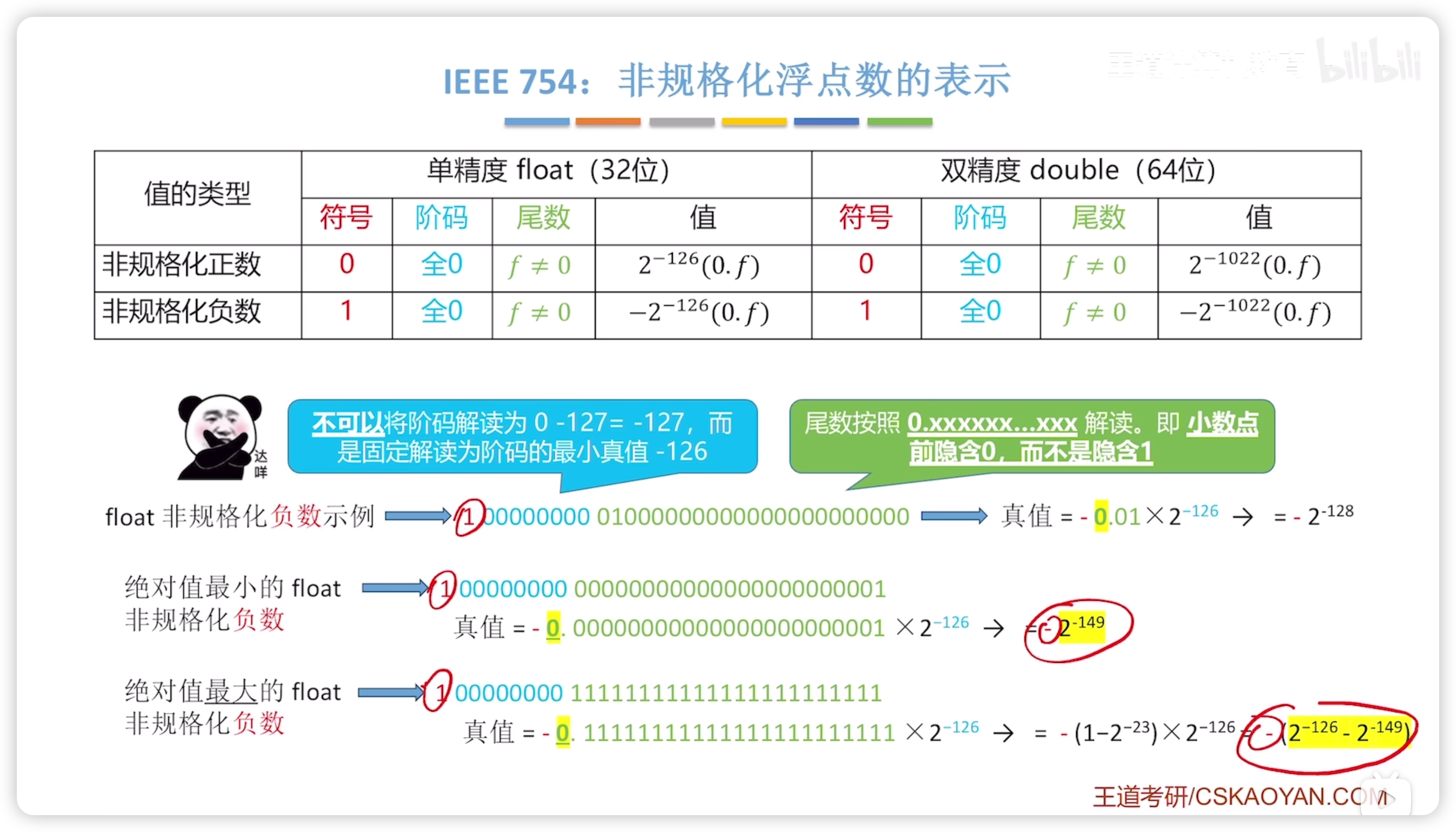
臨界值要記住,最大最小的數
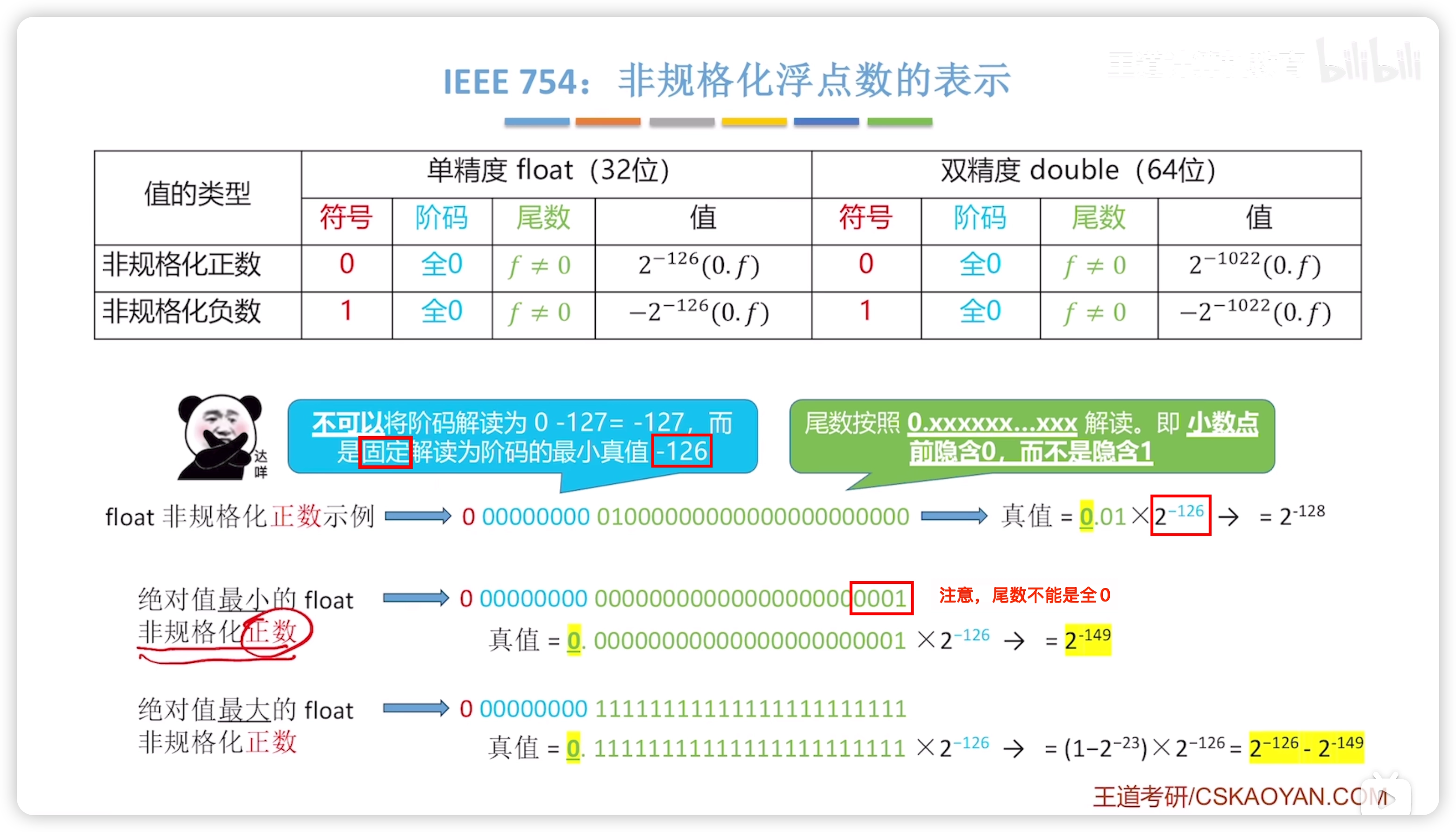
- 非規格化表示的階碼固定為 -126
- 尾數不能為全零
- 尾數解讀為 0.xxxx 而不是正常的 1.xxxx
負數同理:
2.3.3 浮點數加減運算
浮點數運算的特點:階碼運算和尾數運算分開。
對階
對階:使兩個操作數的小數點對齊,使得兩個數的階碼相同。
- 一般是 小階向大階對齊
對階會導致尾數右移,為保證精度,應該不丟棄移出的尾數,使其參與尾數運算。
規格化
規格化:將尾數改寫為 形式。
- 右規:尾數右移(小數點左移),階碼 + 1
- 左規:尾數左移(小數點右移),階碼 - 1
舍入
對階和右規時移出的位會保留,在舍入這一步時做具體的捨去操作。
- 就近舍入
- 正/負向舍入
- 截斷法
溢出判斷
- 左右規:可能指數下/上溢
- 尾數舍入:可能尾數溢出,溢出需要通過右規調整,然後又可能指數上溢。
尾數溢出,結果不一定溢出。
- 尾數溢出可以通過右規調整,所以不一定溢出
- 當然調整之後可能指數溢出,最終導致溢出
- 結果是否溢出主要看指數溢出
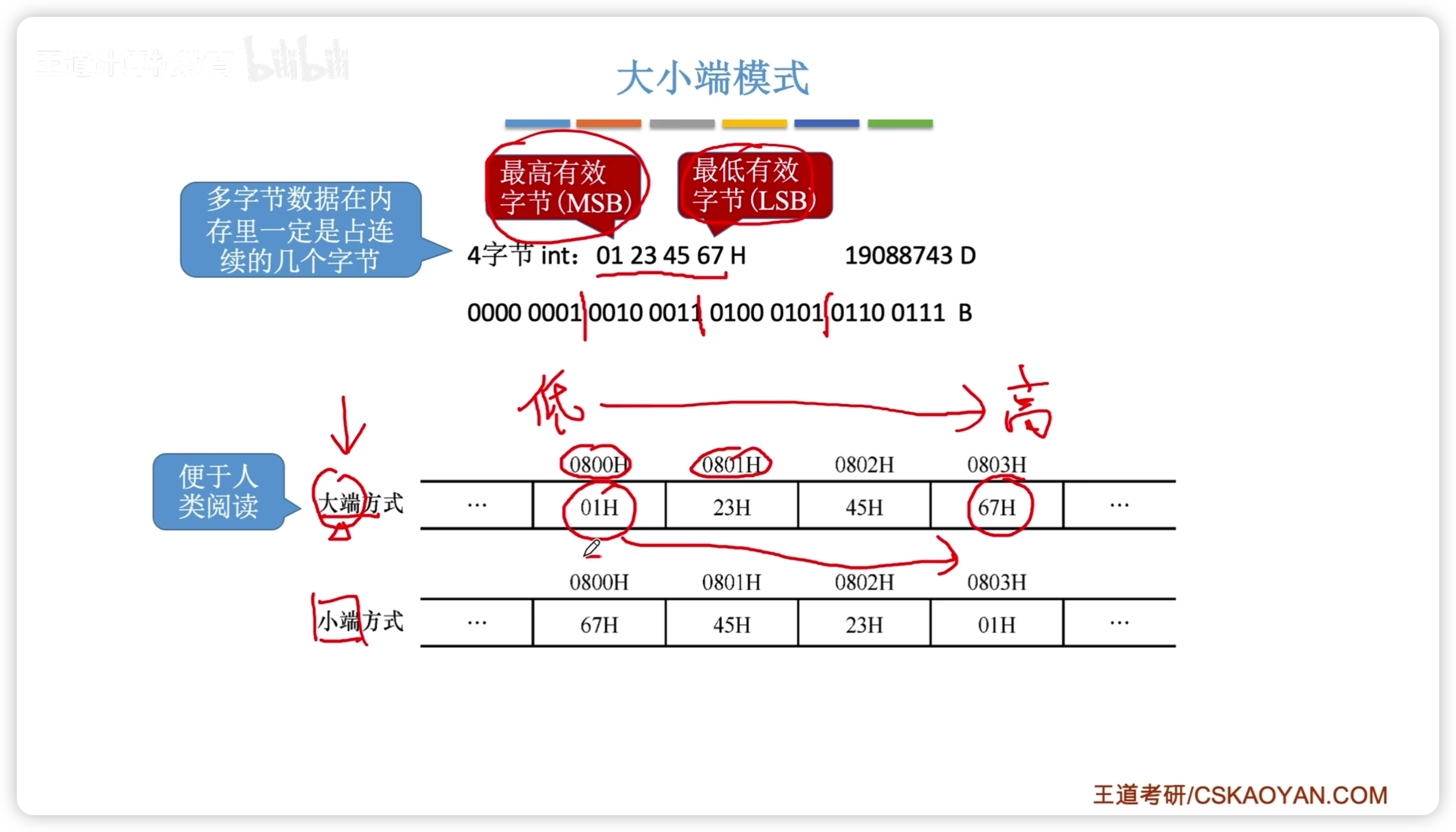
2.3.4 數據存儲和排列
大端:高字節在低地址 小端:高字節在高地址
- 注意,以字節(2位16進制)為單位
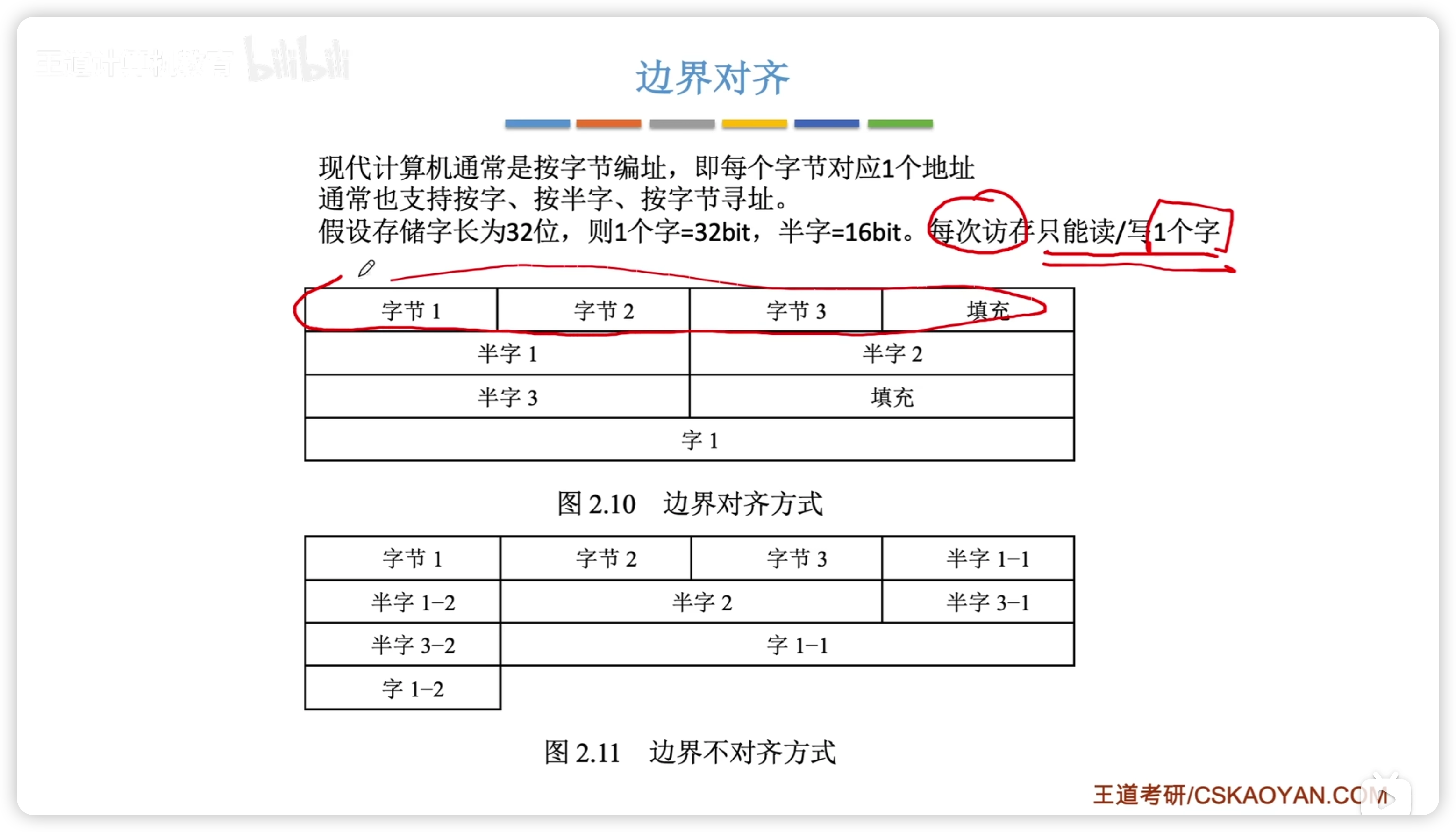
邊界對齊
- 一般是按字節編址,即一個地址對應一個字節
2.4 補充:C語言
在 C 語言裡,類型的長度(字節數)取決於編譯器實現和平臺架構,但常見的 32 位、64 位主流平臺(如 Windows x86/x64、Linux x86_64、macOS ARM64)大致遵循下面的規律:
| 類型 | 常見字節數(bytes) | 常見位數(bits) | 備註 |
|---|---|---|---|
char | 1 | 8 | 保證是 1 字節(標準規定 sizeof(char) 永遠是 1)。 |
short | 2 | 16 | 最少 16 位(標準只保證 ≥16 位)。 |
int | 4 | 32 | 在現代主流桌面平臺幾乎都是 32 位。 |
long | 4 / 8 | 32 或 64 | Win 平臺的 LLP64 模型 vs Unix/Linux 的 LP64 模型。 |
long long | 8 | 64 | 標準保證 ≥64 位,幾乎總是 64 位。 |
float | 4 | 32 | IEEE 754 單精度。 |
double | 8 | 64 | IEEE 754 雙精度。 |
3 存儲系統
3.1 存儲器概述
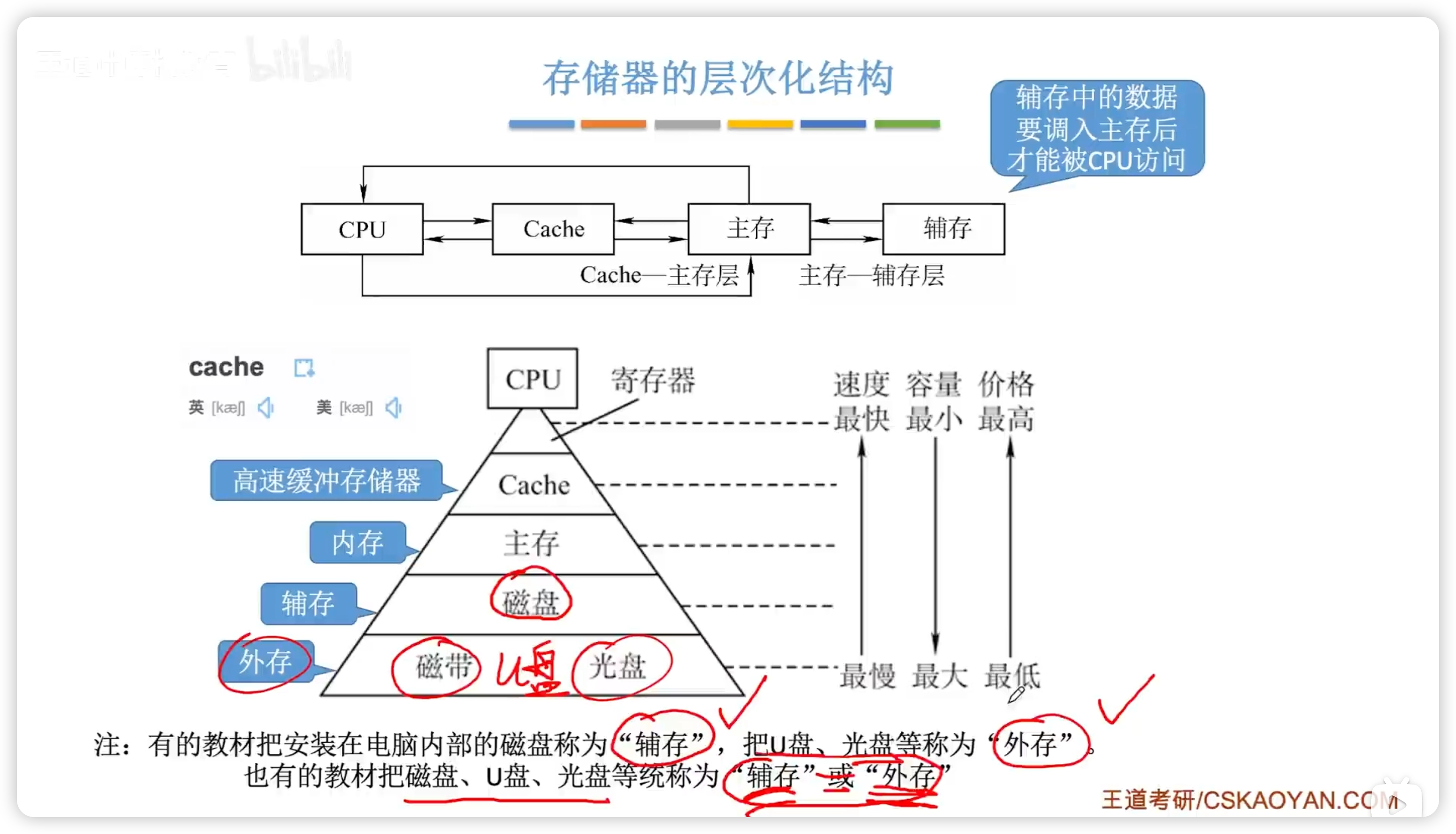
- 輔存中的數據需要調入主存後才能被 CPU 訪問
主存與輔存:實現了虛擬存儲系統,解決了主存容量不夠的問題
Cache與主存:解決了主存與 CPU 速度不匹配的問題(CPU 速度更快)
3.1.1 存取方式

- 隨機存取存儲器 RAM:支持隨機訪問
- 順序存取存儲器 SAM:只能順序訪問
- 直接存取存儲器 DAM:支持直接選取區域(隨機訪問),區域內按順序訪問
- 磁盤是 DAM
- 相聯存儲器 CAM:按照內容檢索 或者 地址檢索
- 快表是一種相聯存儲器
3.1.2 性能指標
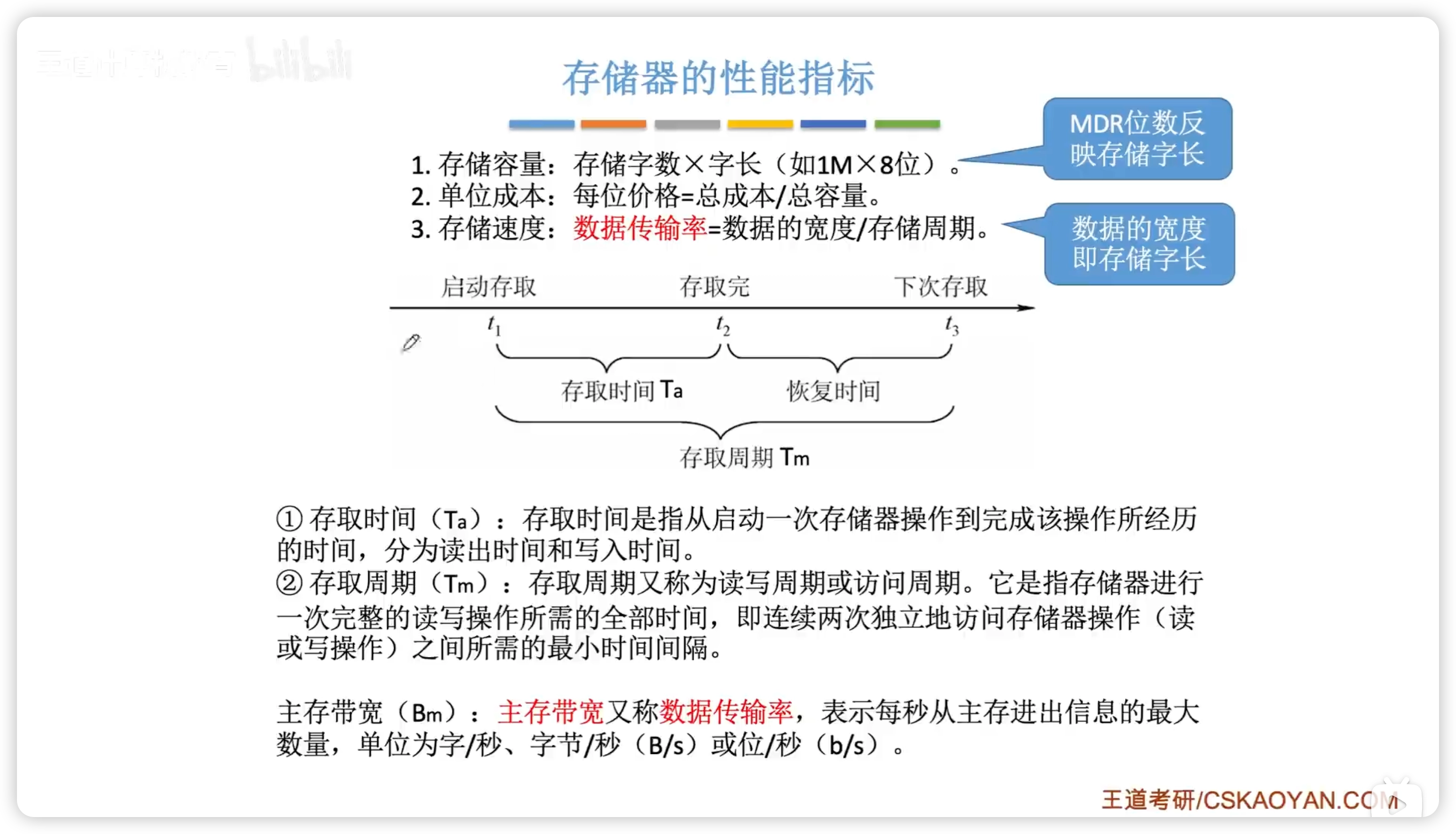
存儲容量
單位成本
存儲速度
數據傳輸率也稱主存帶寬
3.2 主存儲器
主存儲器是內存,主要有 RAM 和 ROM 兩種。
- RAM:易失性,斷電後數據丟失
- ROM:非易失性
3.2.1 半導體原理
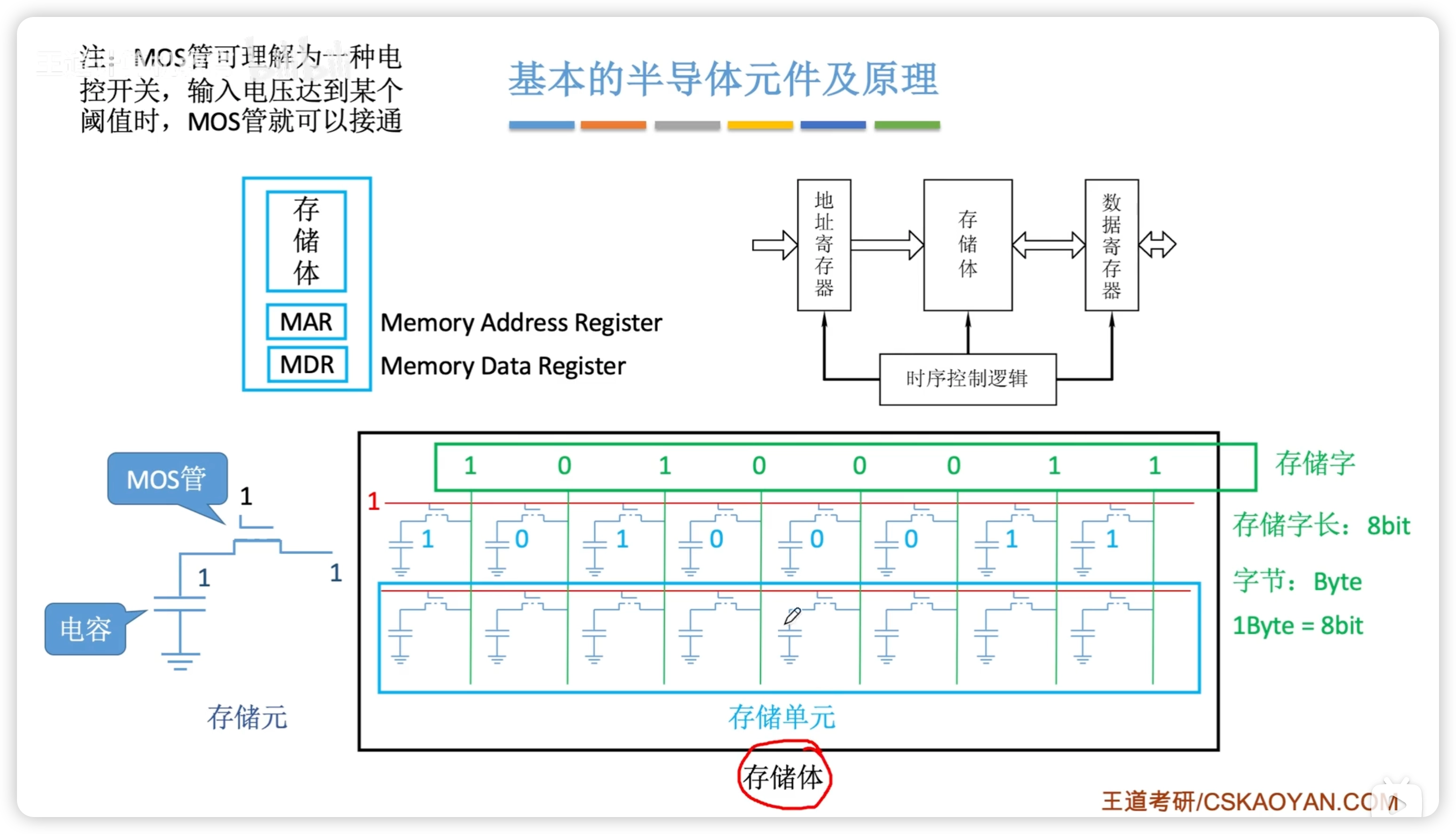
存儲字:一次可以讀出的 bit 數
存儲字長:
- 存儲字的長度
- 一個存儲單元中的二進制位數
- 一個存儲單元中的存儲元數量
多個存儲單元構成存儲體/存儲矩陣。
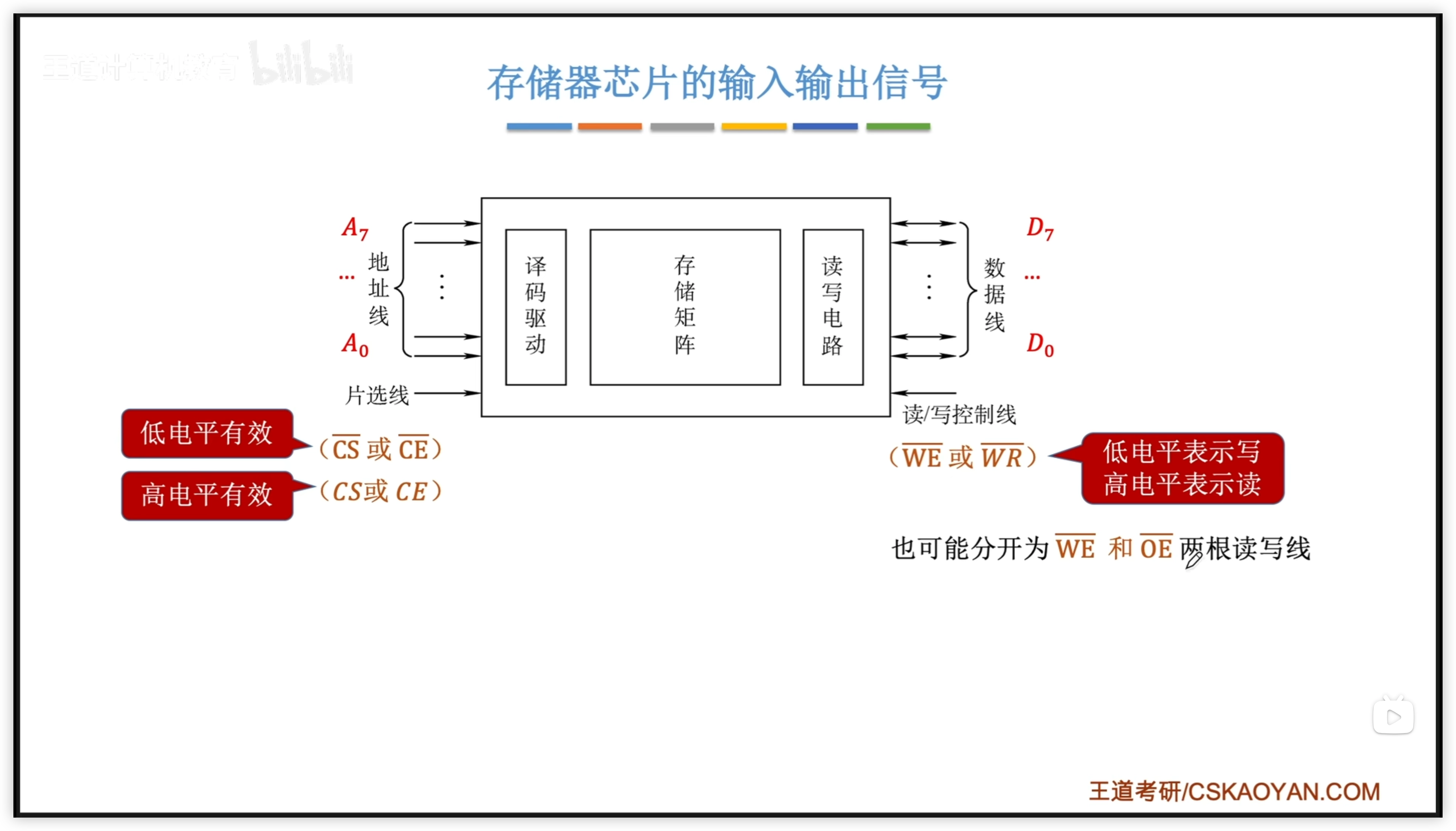
3.2.2 存儲器芯片原理
- CPU 通過 地址總線 傳遞地址 to MAR
- 控制電路 控制 MAR
- MAR to 譯碼器
- 譯碼器 選擇 存儲元
- 存儲元 to MDR
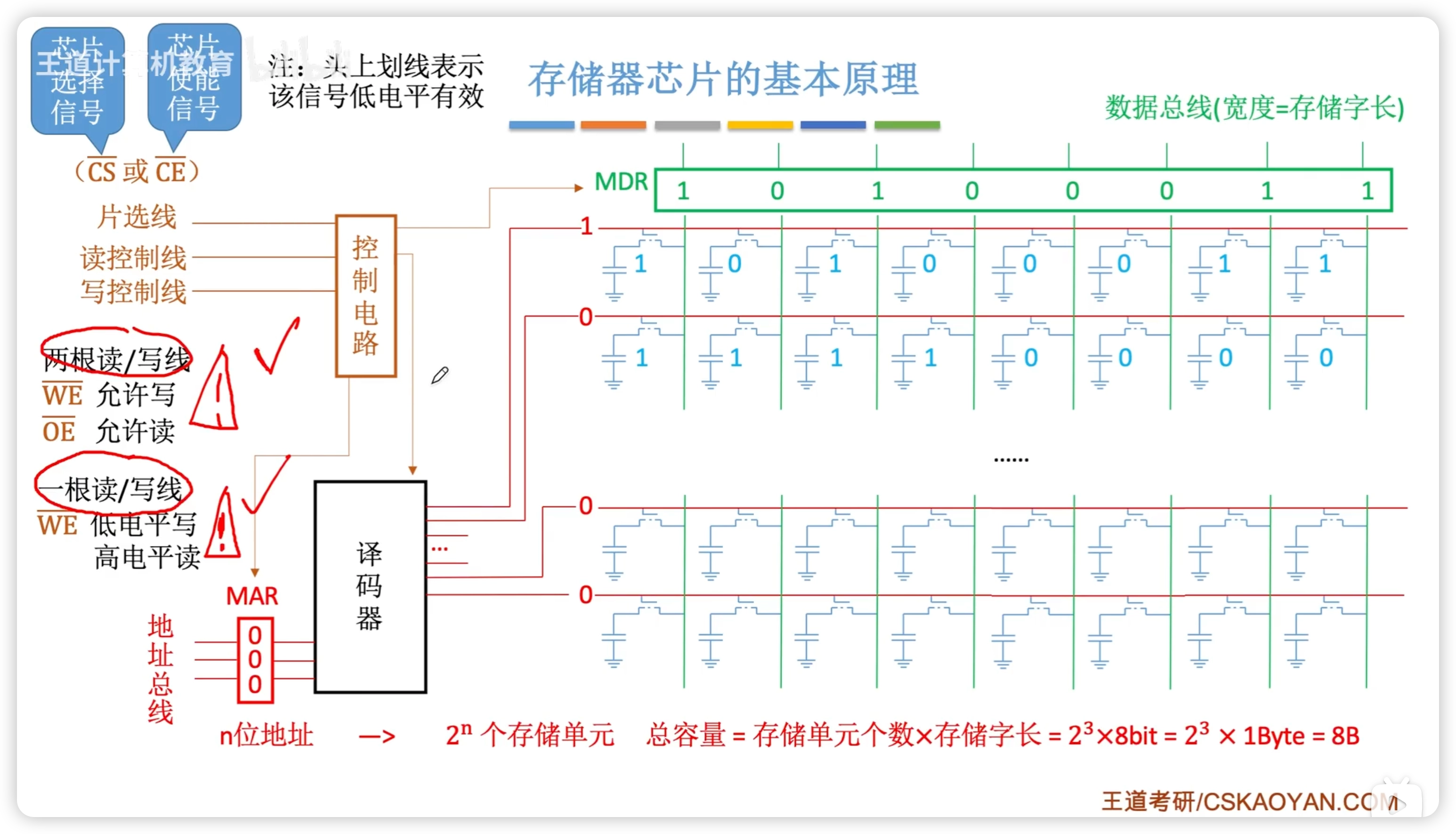
- 讀寫線可能有 1 或者 2 根
- 片選線:選擇哪個芯片

引腳數量:
- 每個線對應一個引腳
- 讀寫線可能有 2 根
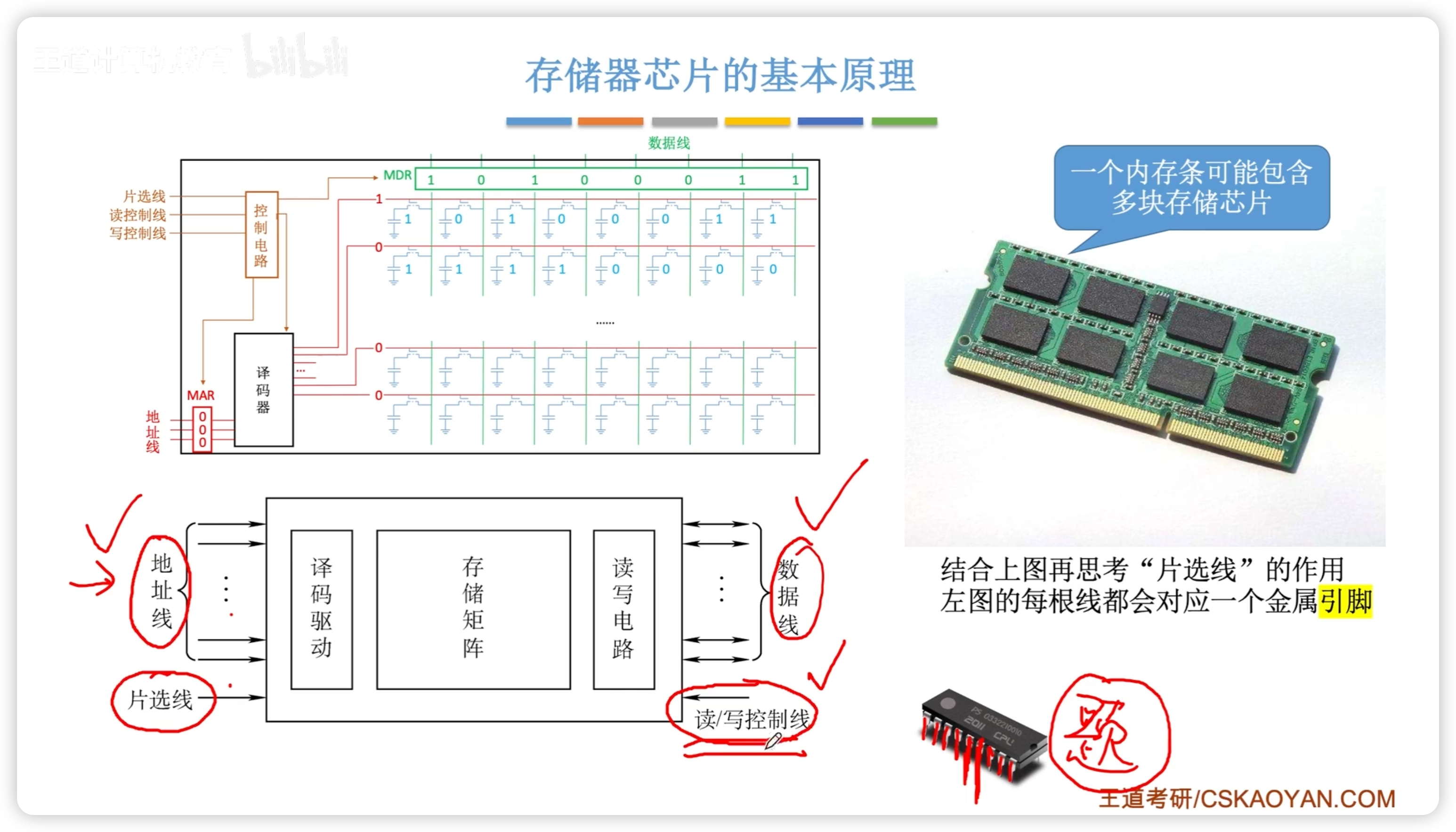
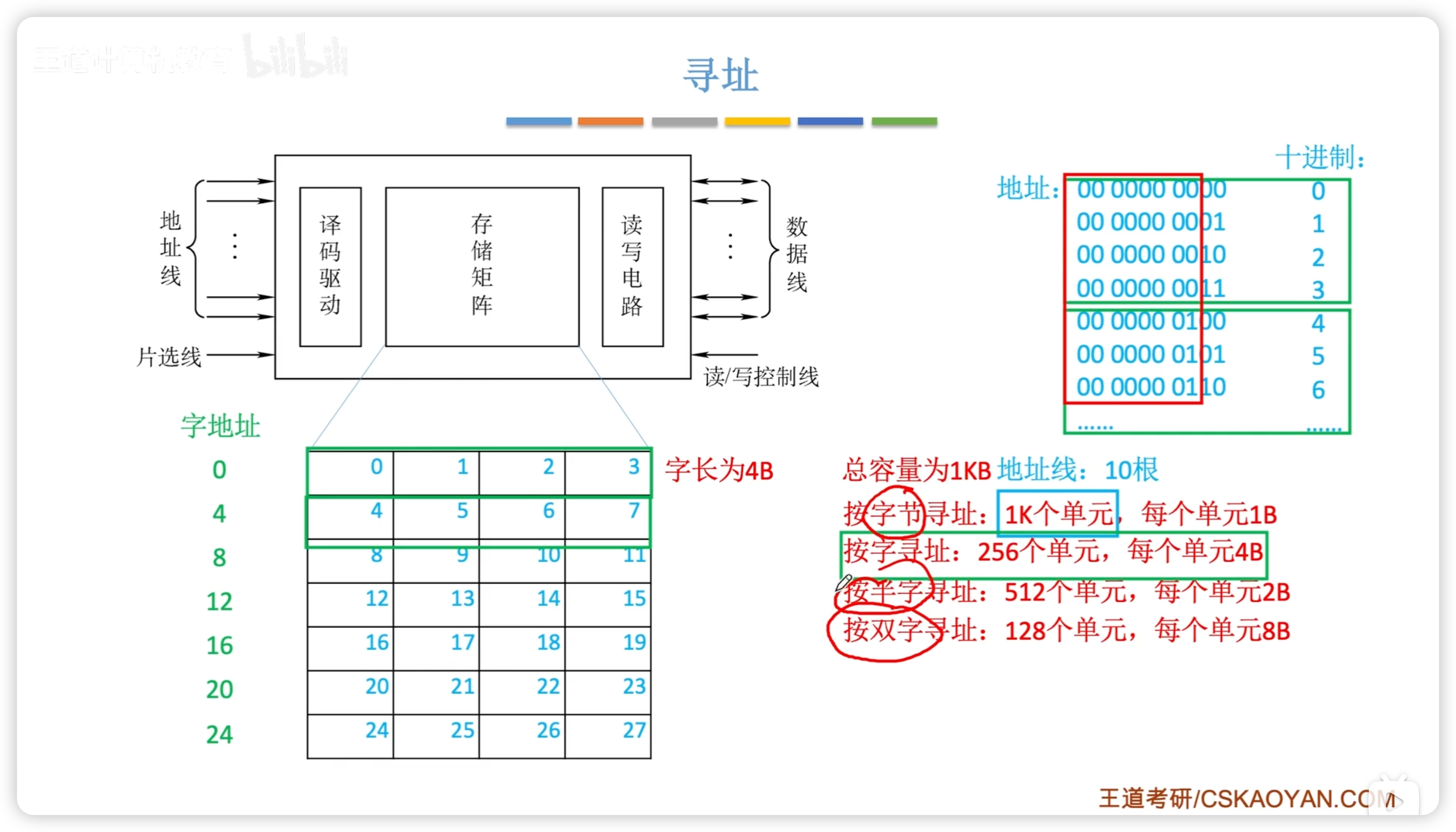
3.2.3 尋址
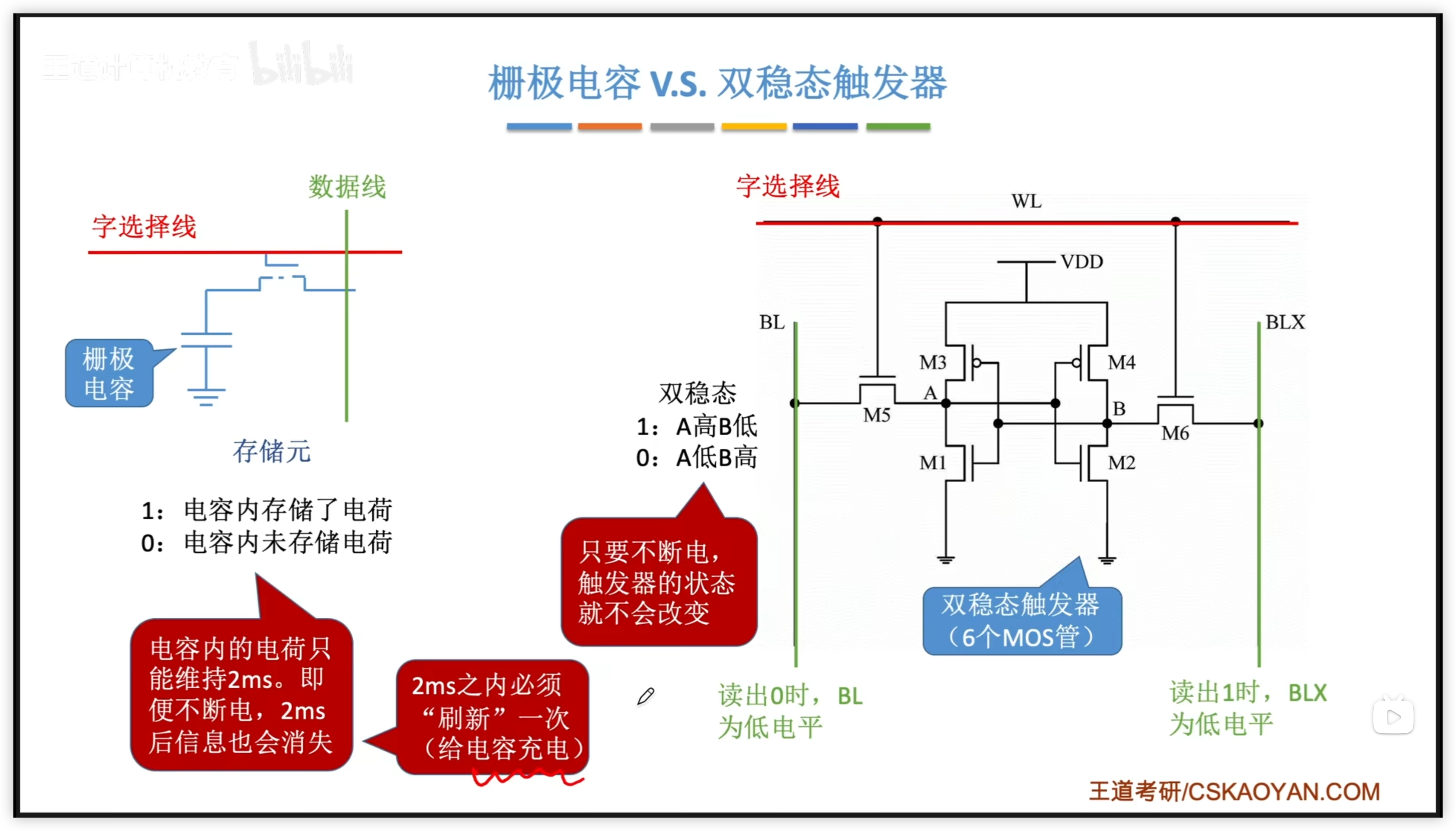
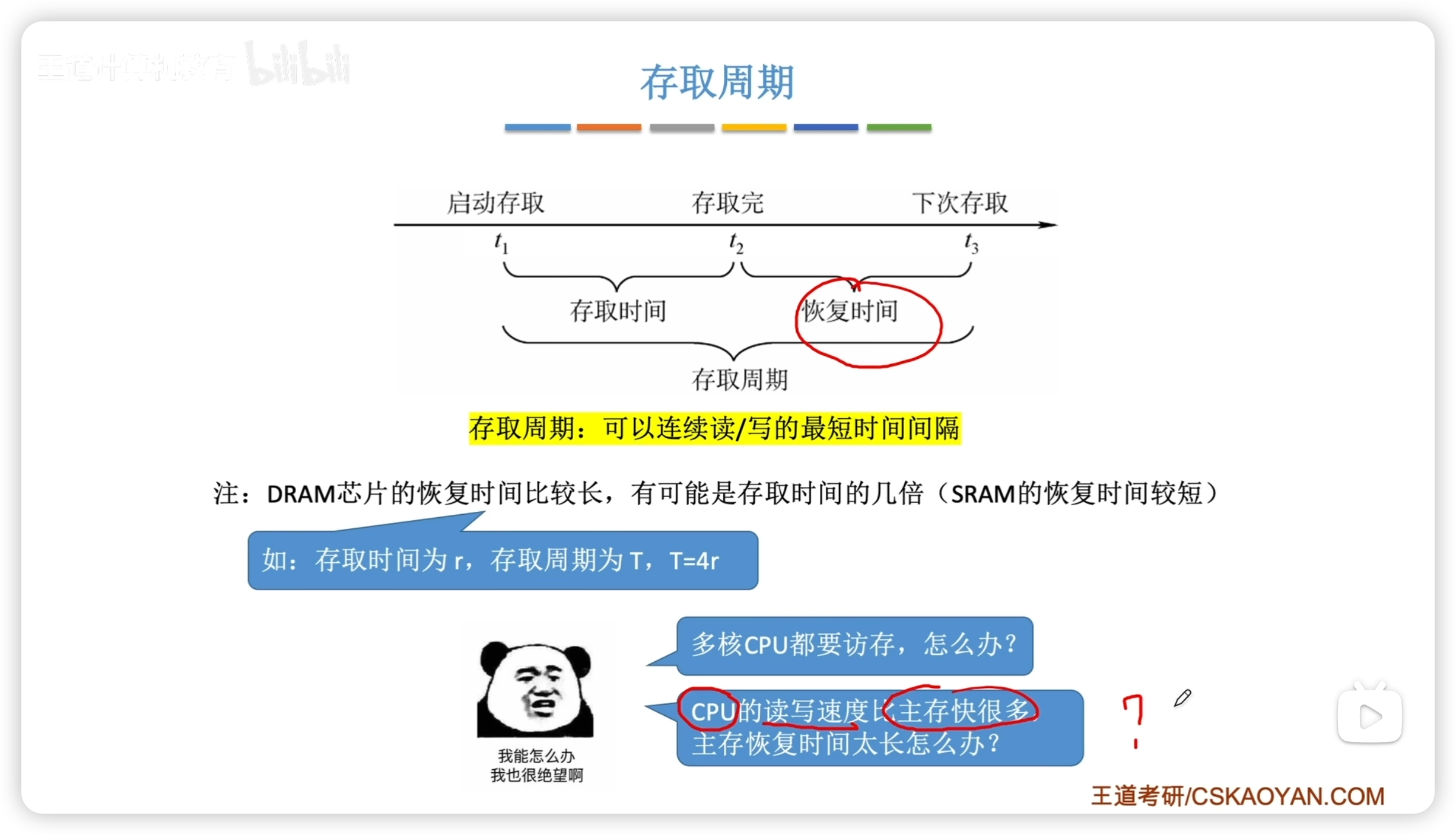
3.2.4 DRAM 與 SRAM
RAM 主要有 DRAM、SRAM:
- Static and Dynamic
- 上一節的是 DRAM
DRAM芯片:使用柵極電容存儲信息,常用作主存 SRAM芯片:使用雙穩態觸發器存儲信息,常用作 Cache
- 核心區別:存儲元不一樣
| 類型特點 | DRAM(動態RAM) | SRAM(靜態RAM) |
|---|---|---|
| 存儲信息 | 電容 | 觸發器 |
| 破壞性讀出 | 是 | 非 |
| 讀出後需要重寫?(再生) | 需要 | 不用 |
| 運行速度 | 慢 | 快 |
| 集成度 | 高 | 低 |
| 發熱量 | 小 | 大 |
| 存儲成本 | 低 | 高 |
| 易失/非易失性存儲器? | 易失(斷電後信息消失) | 易失(斷電後信息消失) |
| 需要刷新 | 需要 | 不需要 |
| 送行列地址 | 分兩次送 | 同時送 |
- DRAM 分兩次送地址是由於地址線複用,使地址線、地址引腳減半
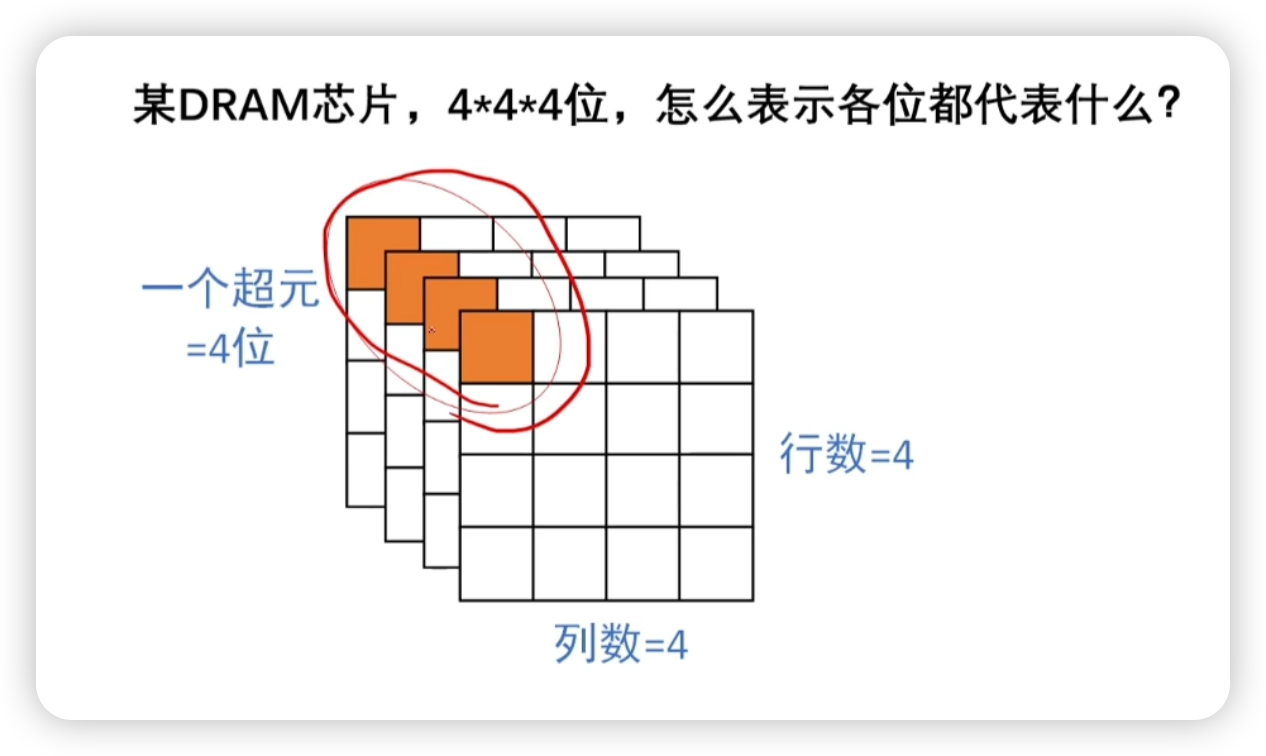
DRAM 芯片的行列計算
- 重要補充,網課這塊不紮實
假定有一個 位的 DRAM 芯片,它實際上是一個存儲陣列
- 芯片中每個存儲單元包含 位
- 行數 和列數 滿足
- 由於按行刷新,所以滿足
- 儘量使行列數相同
- 或者有些題會直接給出 位的形式
DRAM 刷新
為什麼 DRAM 需要刷新?
如何刷新:
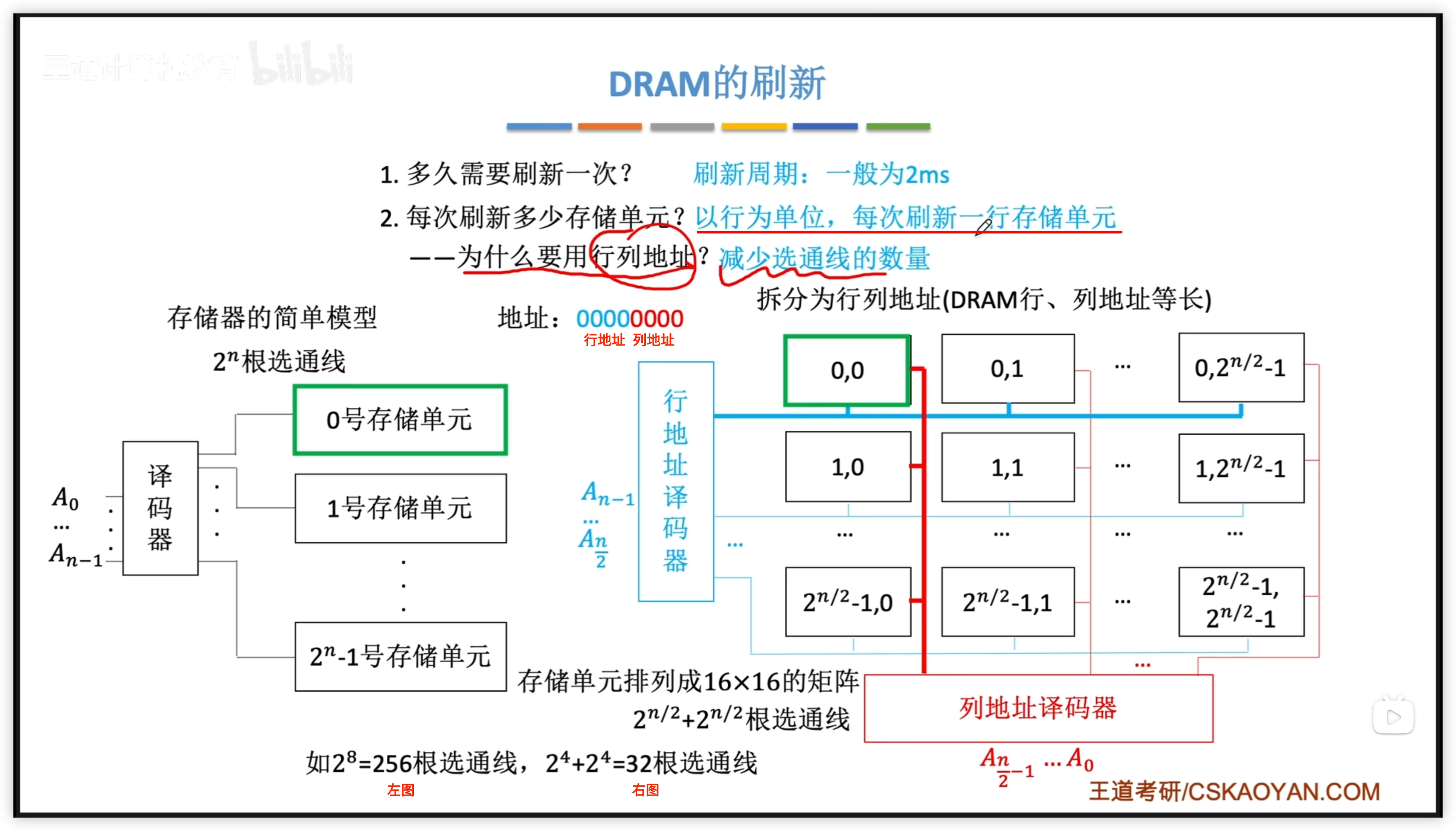
三種刷新方式:
- 分散刷新:刷新太頻繁
- 集中刷新:有死區
- 異步刷新:死區小
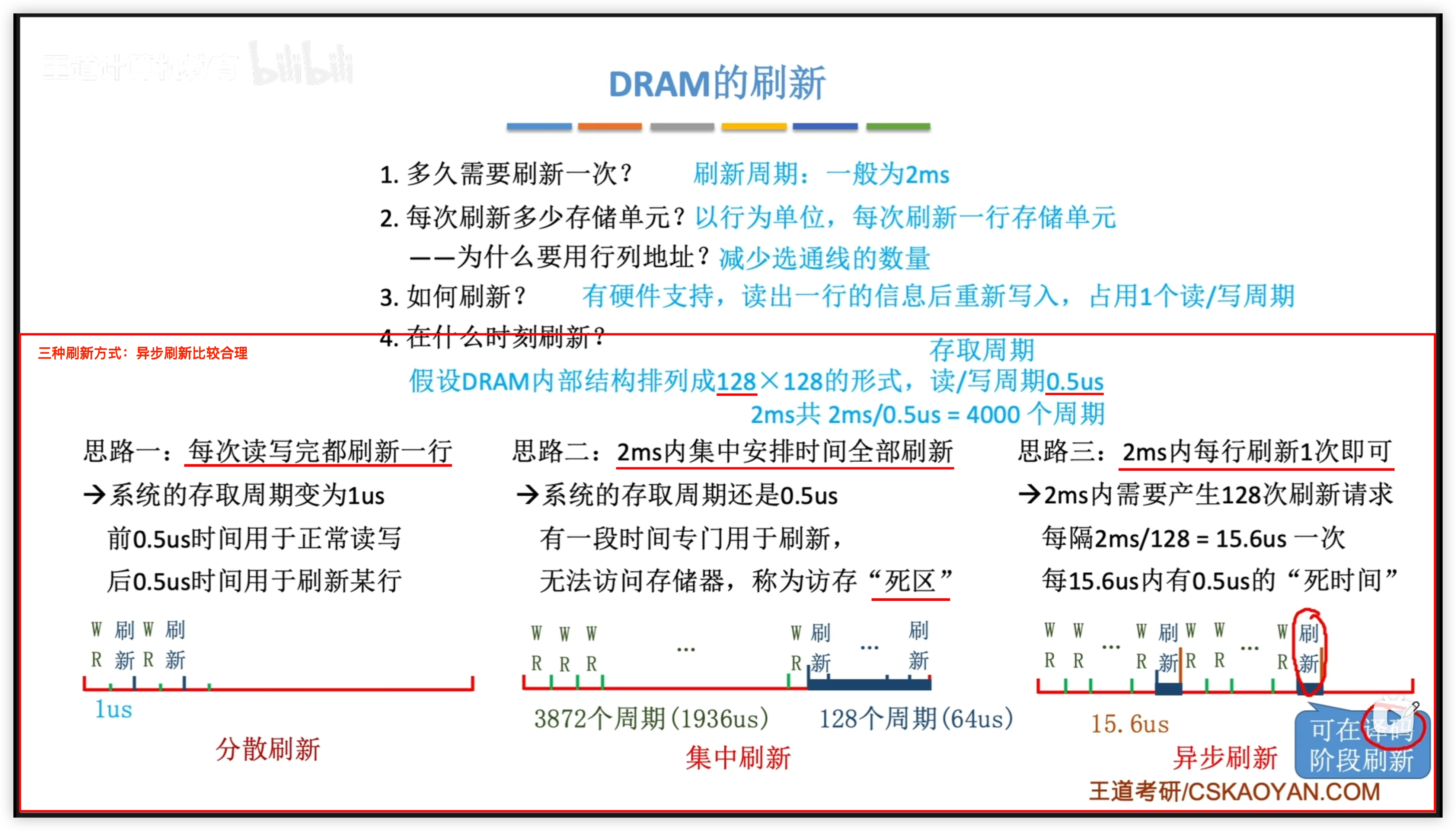
刷新由存儲器獨立完成,無需 CPU 介入。
現在的主存已經拋棄了 DRAM,主要使用 SDRAM,例如 ddr4。
SDRAM
- SDRAM(Synchronous DRAM)
SDRAM 的工作方式與傳統的 DRAM 有很大不同。
- 傳統 DRAM 與CPU 之間採用異步方式交換數據,CPU 發出地址和控制信號後,經過一段延遲時間,數據才讀出或寫入。
- 在這段時間裡,CPU 不斷採樣 DRAM 的完成信號,在沒有完成之前,CPU 插入等待狀態而不能做其他工作。
- SDRAM 採用同步方式
行緩衝寄存器
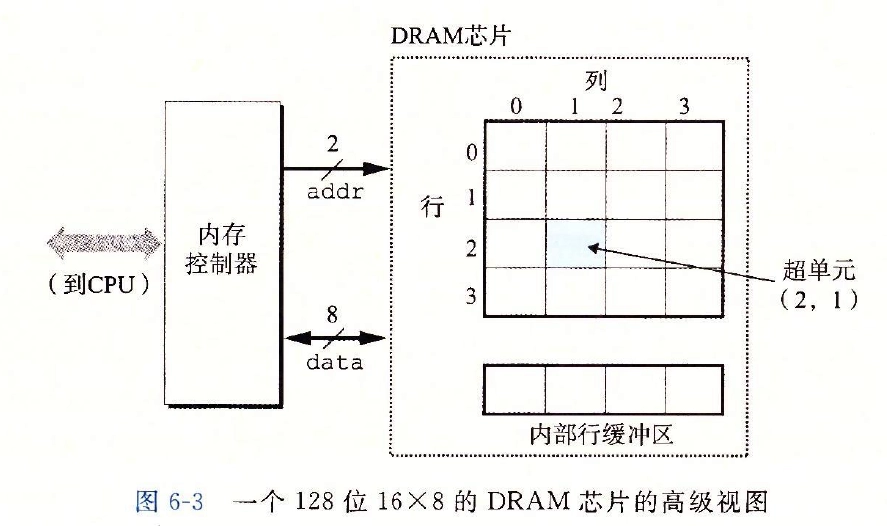
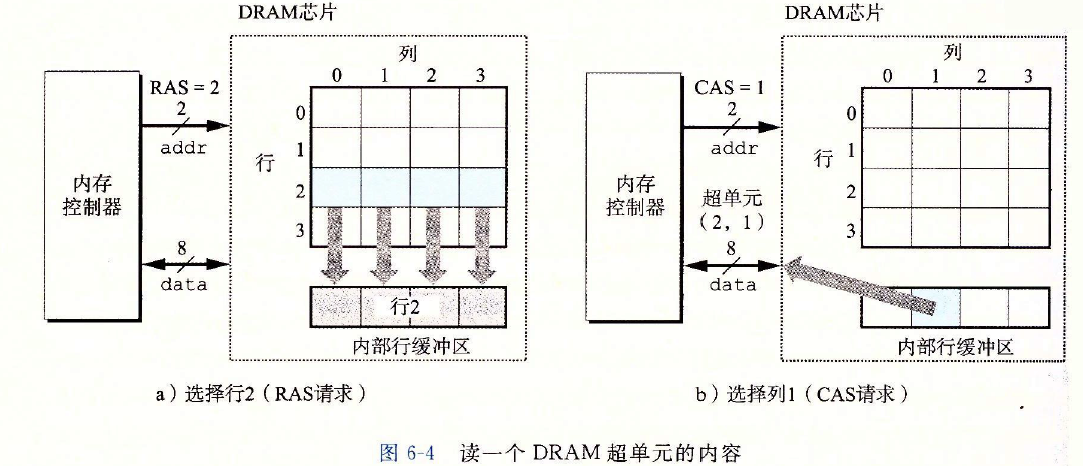
例如,要從圖 6-3中 的DRAM中讀出超單元(2,1),內存控制器發送行地址2,如下圖a所示。
DRAM 的響應是將行 2 的整個內容都複製到一個內部行緩衝區。接下來,內存控制器發送列地址1,如下圖b所示。DRAM的響應是從行緩衝區複製出超單元(2,1)中的8位,並把它們發送到內存控制器。
超單元:多位就是超單元
3.2.5 ROM
各種 ROM:
- MROM(Mask Read Only Memory):
- 廠家按客戶需求在芯片生產時寫入信息,不可重寫,可靠性高、靈活性差、生產週期長,適合批量定製。
- PROM(Programmable Read Only Memory):
- 用戶可用專門寫入器寫入信息,寫一次後不可更改。
- EPROM(Erasable Programmable Read Only Memory):
- 允許用戶寫入信息,之後可擦除數據並多次重寫;
- 支持隨機存取
- UVEPROM:用紫外線照射8 - 20分鐘擦除所有信息
- EEPROM(也記為E^2PROM)可用“電擦除”方式擦除特定的字。
- Flash Memory(閃速存儲器、閃存):
- U盤、SD卡屬於閃存,由EEPROM發展而來,斷電能保存信息且可多次快速擦除重寫
- 每個存儲元只需單個MOS管,位密度比RAM高,閃存寫速度比讀速度慢;
- 手機輔存使用Flash芯片,不過相比SSD使用的芯片,集成度低、功耗高、價格便宜。
- SSD(Solid State Drives):
- 由控制單元 + 存儲單元(Flash芯片)構成,與閃存核心區別在控制單元,存儲介質類似,可多次快速擦除重寫,速度快、功耗低、價格高,
- 常用於個人電腦手機
計算機內的 RAM 和 ROM:
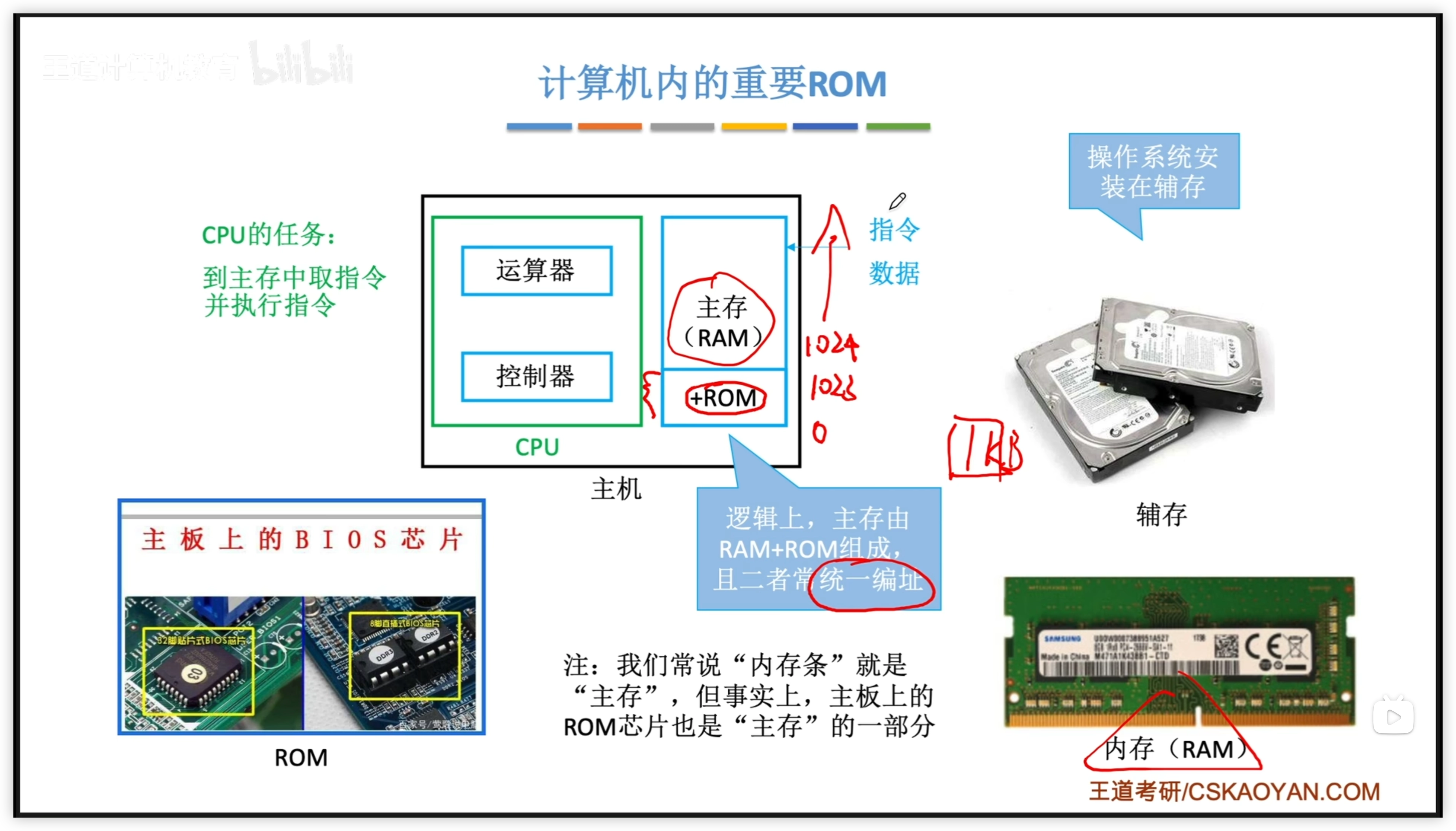
- 操作系統在輔存(ROM)
- BIOS 屬於 ROM
- RAM 和 ROM 一般統一編址,如圖所示
3.2.6 雙端口 RAM
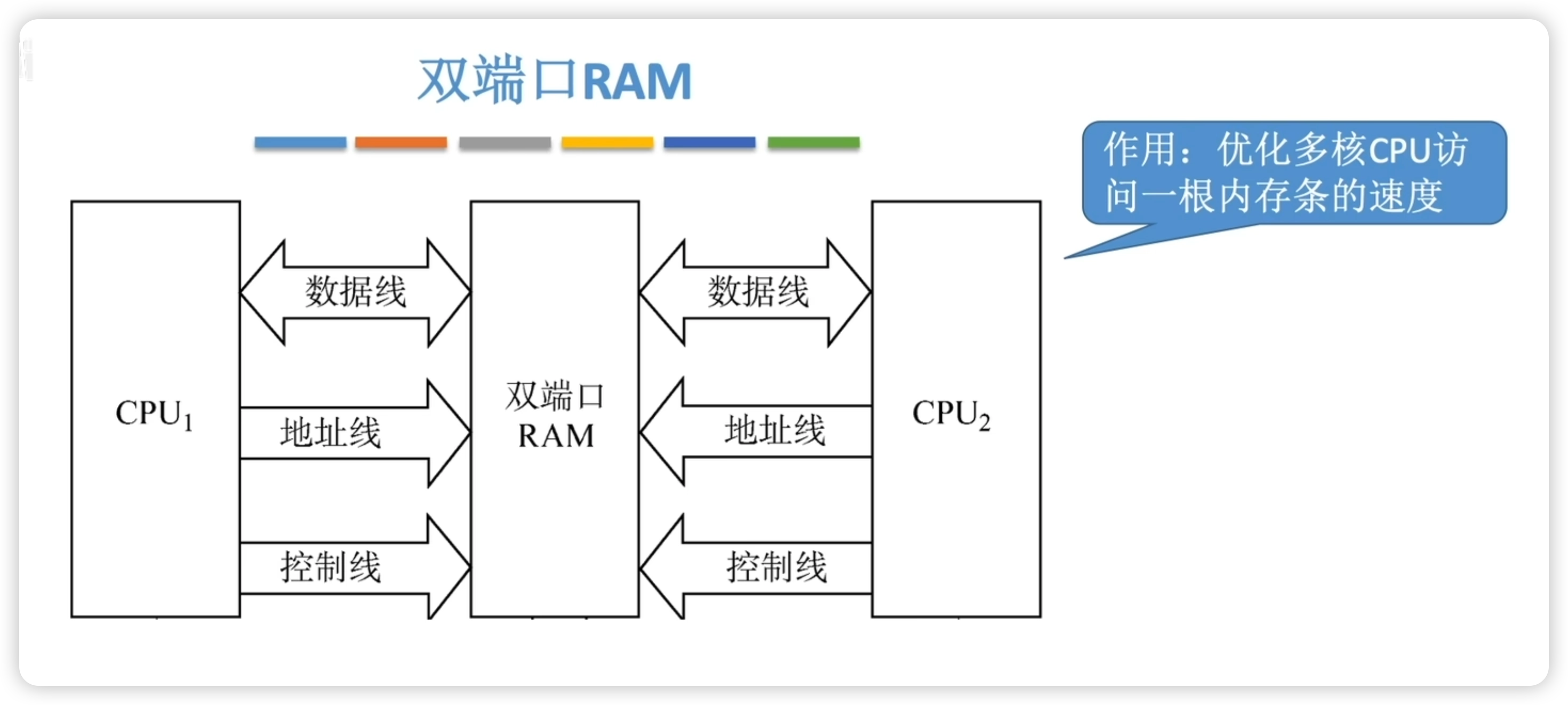
- 作用:優化多核CPU訪問一根內存條的速度。
- 硬件要求:需要有兩組完全獨立的數據線、地址線、控制線,CPU、RAM中也要有更復雜的控制電路。
兩個端口對同一主存操作的4種情況:
- 兩個端口同時對不同的地址單元存取數據。
- 兩個端口同時對同一地址單元讀出數據。
- 兩個端口同時對同一地址單元寫入數據,會出現寫入錯誤。
- 兩個端口同時對同一地址單元,一個寫入數據,另一個讀出數據,會出現讀出錯誤。
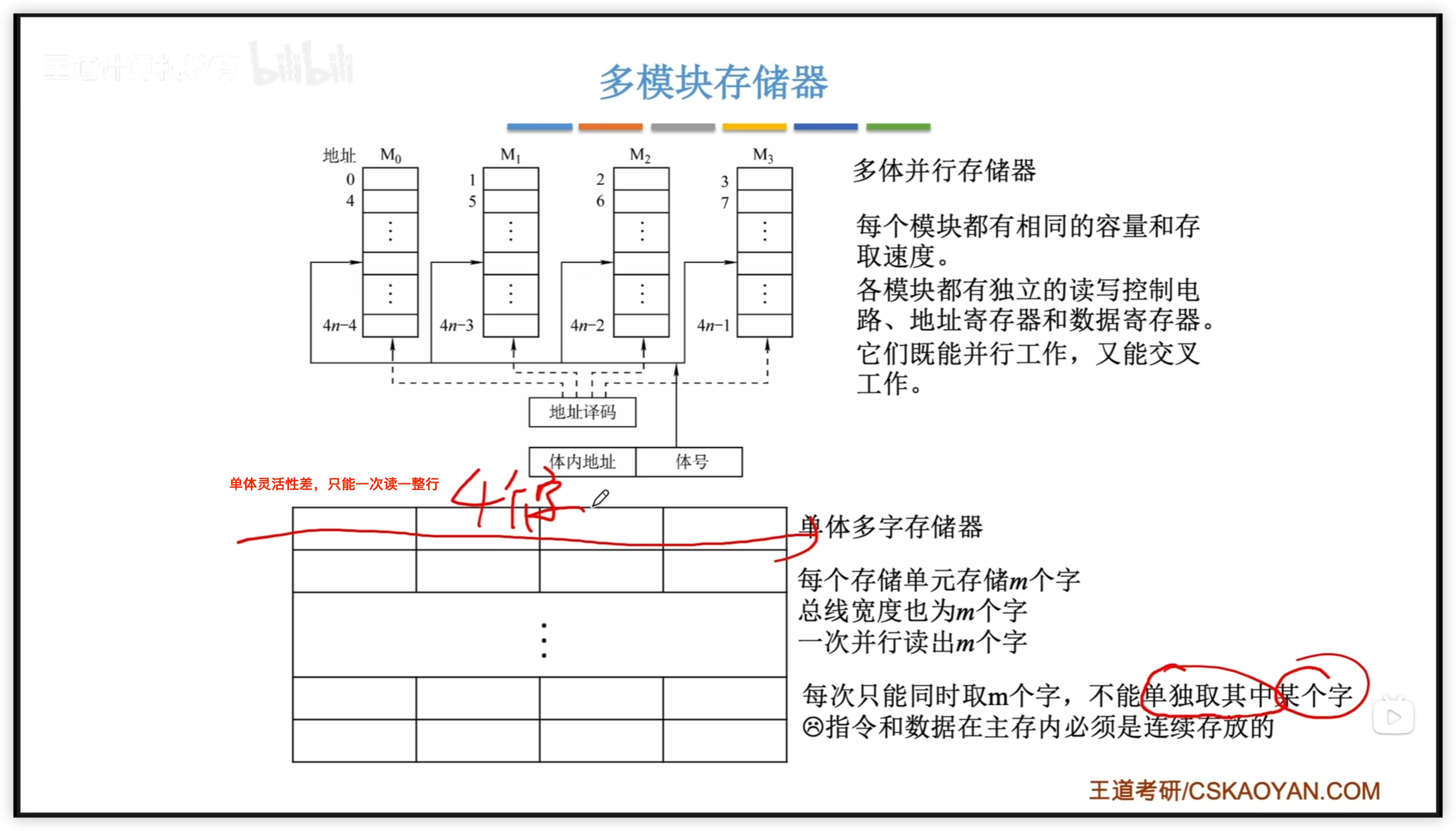
3.2.7 多模塊存儲器
多模塊存儲器主要有:多體並行存儲器 和 單體多字存儲器。
重要概念:
- 多模塊交叉編址
- 多模塊交叉編址是將一個大的存儲空間分成多個小的存儲模塊,並將這些模塊按照一定的規則進行編址,使得在訪問連續的存儲單元時,可以訪問到不同的模塊,從而實現並行訪問。
- 輪流啟動
- 在輪流啟動方式下,系統會按照一定的時間間隔(一個存儲器週期)依次啟動各個存儲模塊,進行讀寫操作。這種方式適用於每個存儲模塊一次讀寫的位數(一個存儲字)正好等於系統總線數據線位數的情況。
- 同時啟動
- 在同時啟動方式下,所有存儲模塊會同時啟動,進行讀寫操作。這種方式適用於所有存儲模塊一次並行讀寫的總位數正好等於系統總線數據線位數的情況。
- 2022真題:存儲器總線寬度 恰好等於 所有模塊的總位數,可以判斷採用了多模塊交叉編址 且 採用了同時啟動的方式。
- 在同時啟動方式下,所有存儲模塊會同時啟動,進行讀寫操作。這種方式適用於所有存儲模塊一次並行讀寫的總位數正好等於系統總線數據線位數的情況。
多體並行存儲器
高位 / 低位交叉編址:
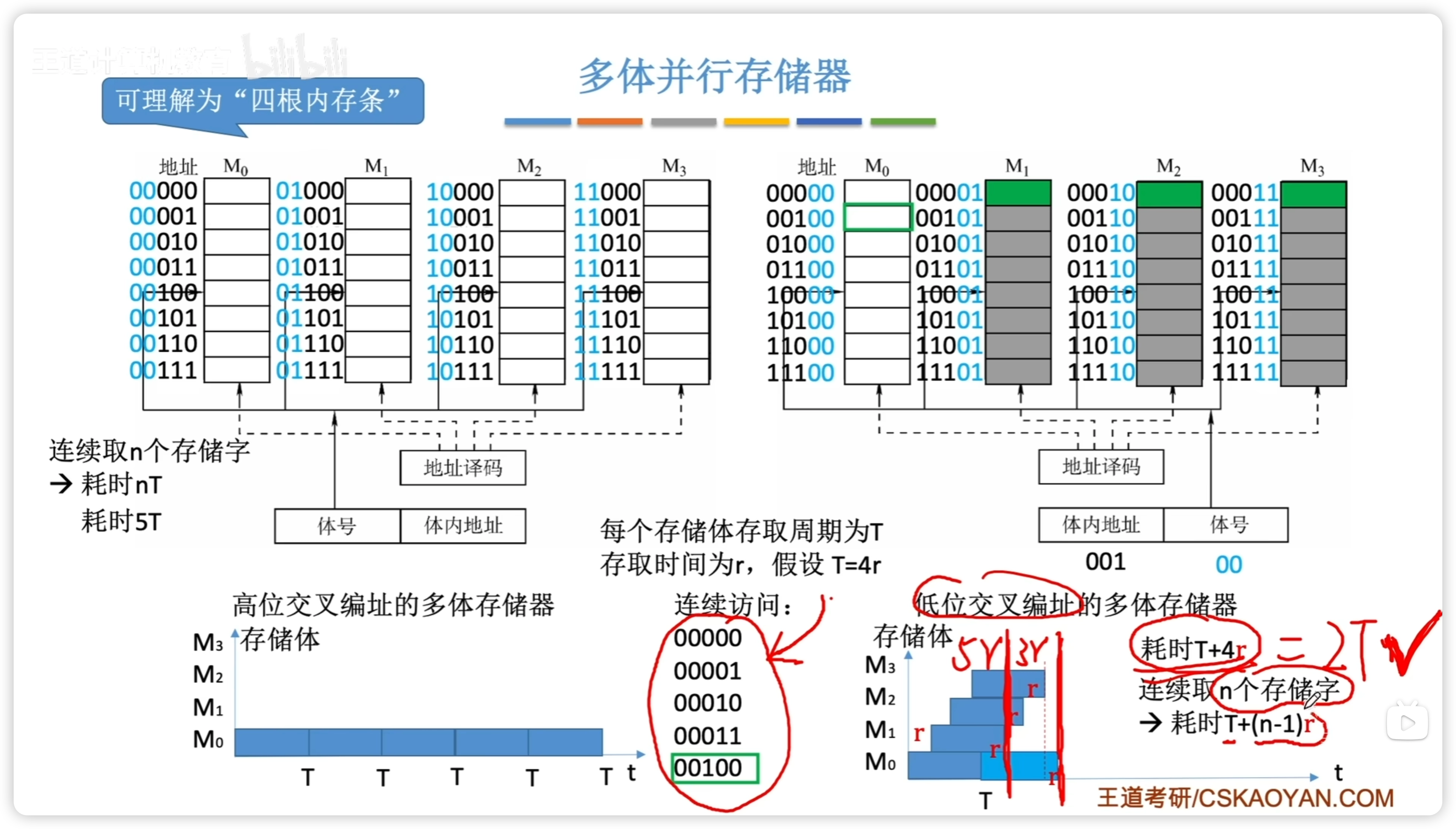
- 存取週期 分為
高位交叉由於連續訪問的地址都在同一條內存,所以每次存取完都需要等待
- 理論上多個存儲體可以被並行訪問,但是由於通常會連續訪問,因此高位交叉實際效果相當於單純的擴容,所以一般不用高位
低位交叉的等待和存取在不同內存條,所以不衝突,可以實現並行訪問
流水線方式:
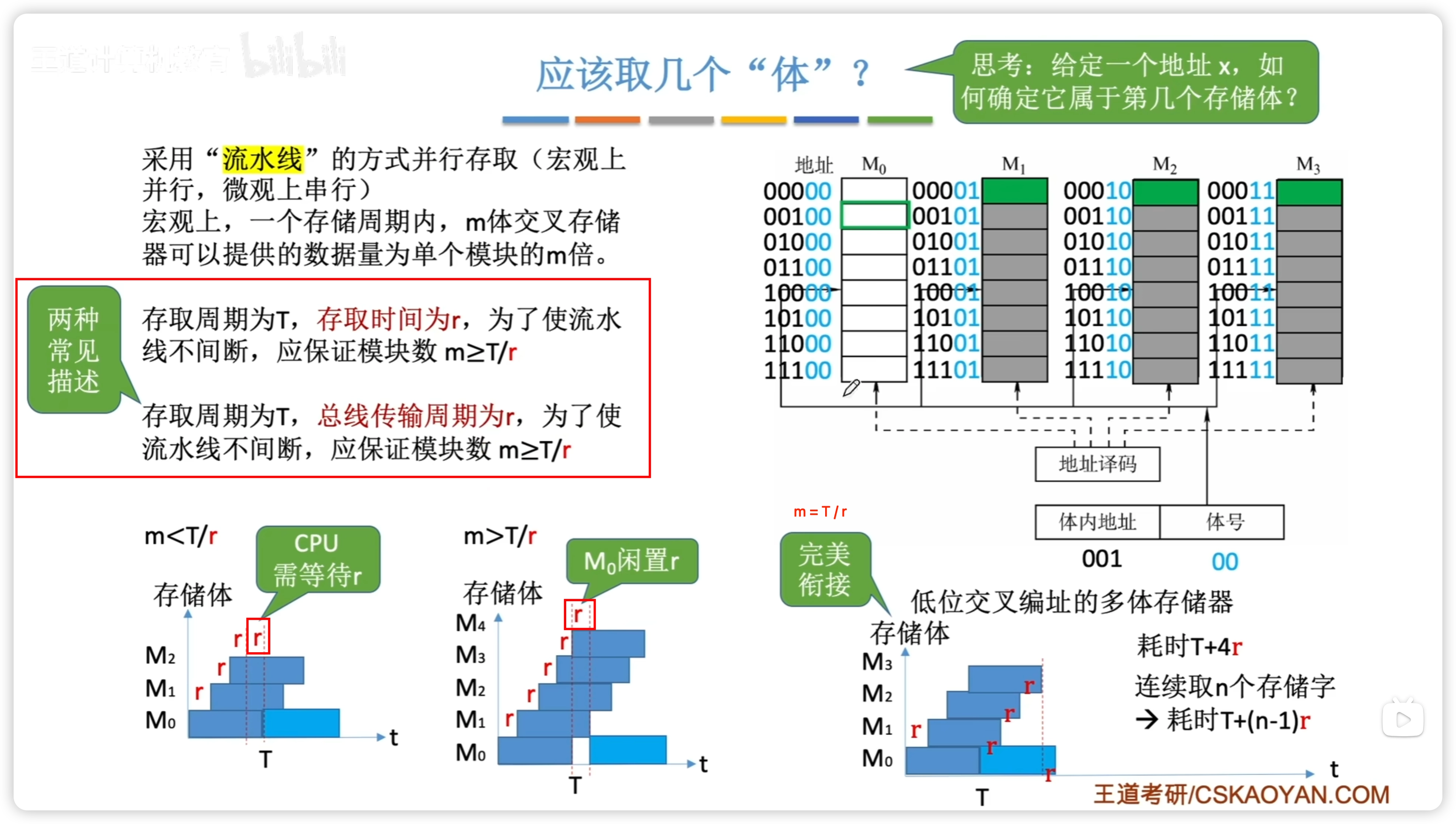
- 注意,存取時間 = 總線傳輸週期
注意,題目中提到交叉編址,一般是指低位交叉,因為高位交叉又稱連續編址。
單體多字存儲器
- 每個存儲單元存儲 m 個字
- 總線寬度也是 m 個字
- 只能一次並行讀取 m 個字,靈活性差
- 指令和數據在主存必須連續存放
3.3 主存儲器與CPU的連接
存儲器的輸入輸出信號:
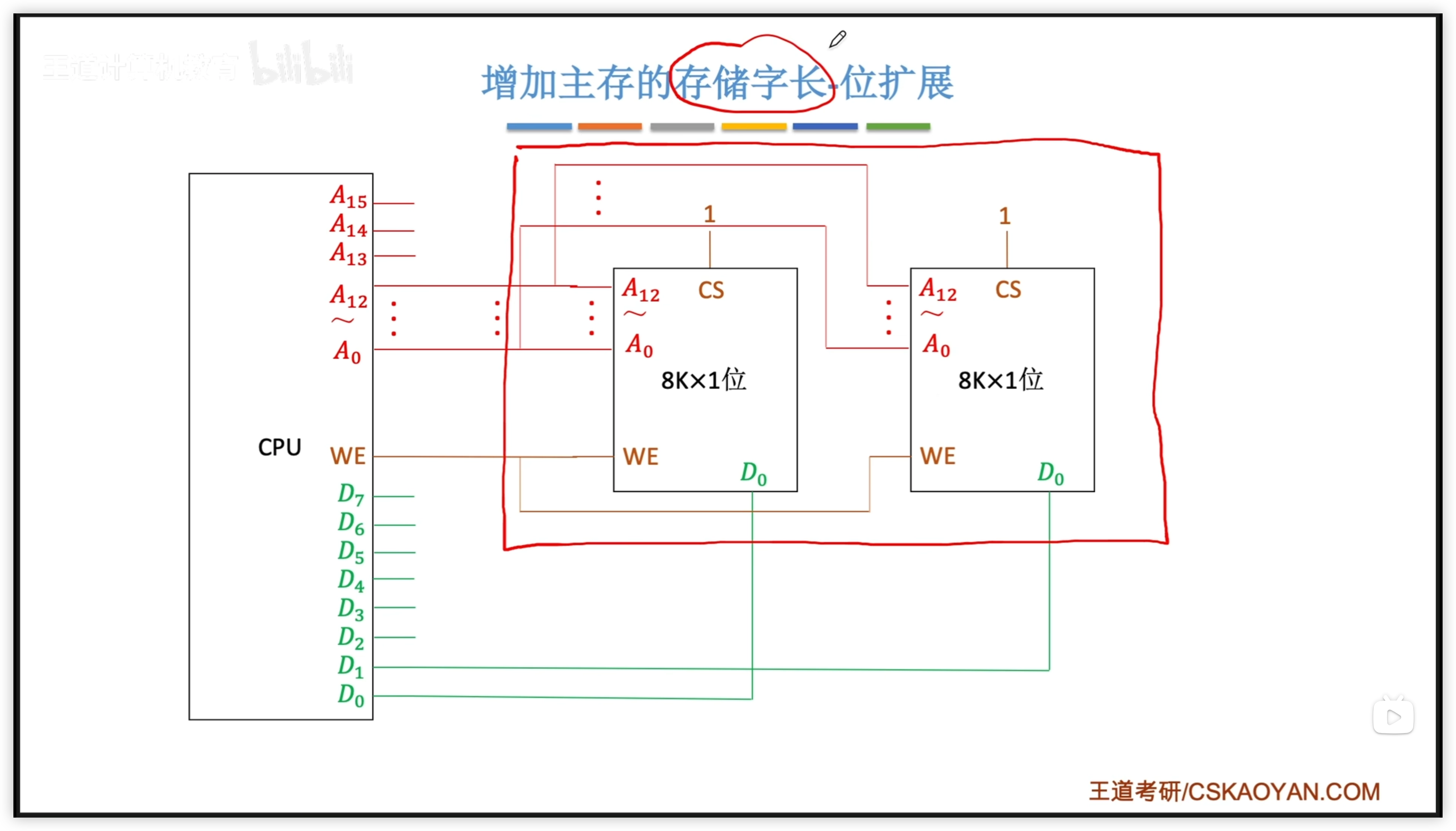
3.3.1 位擴展
兩塊存儲芯片:
擴展到 n 塊:
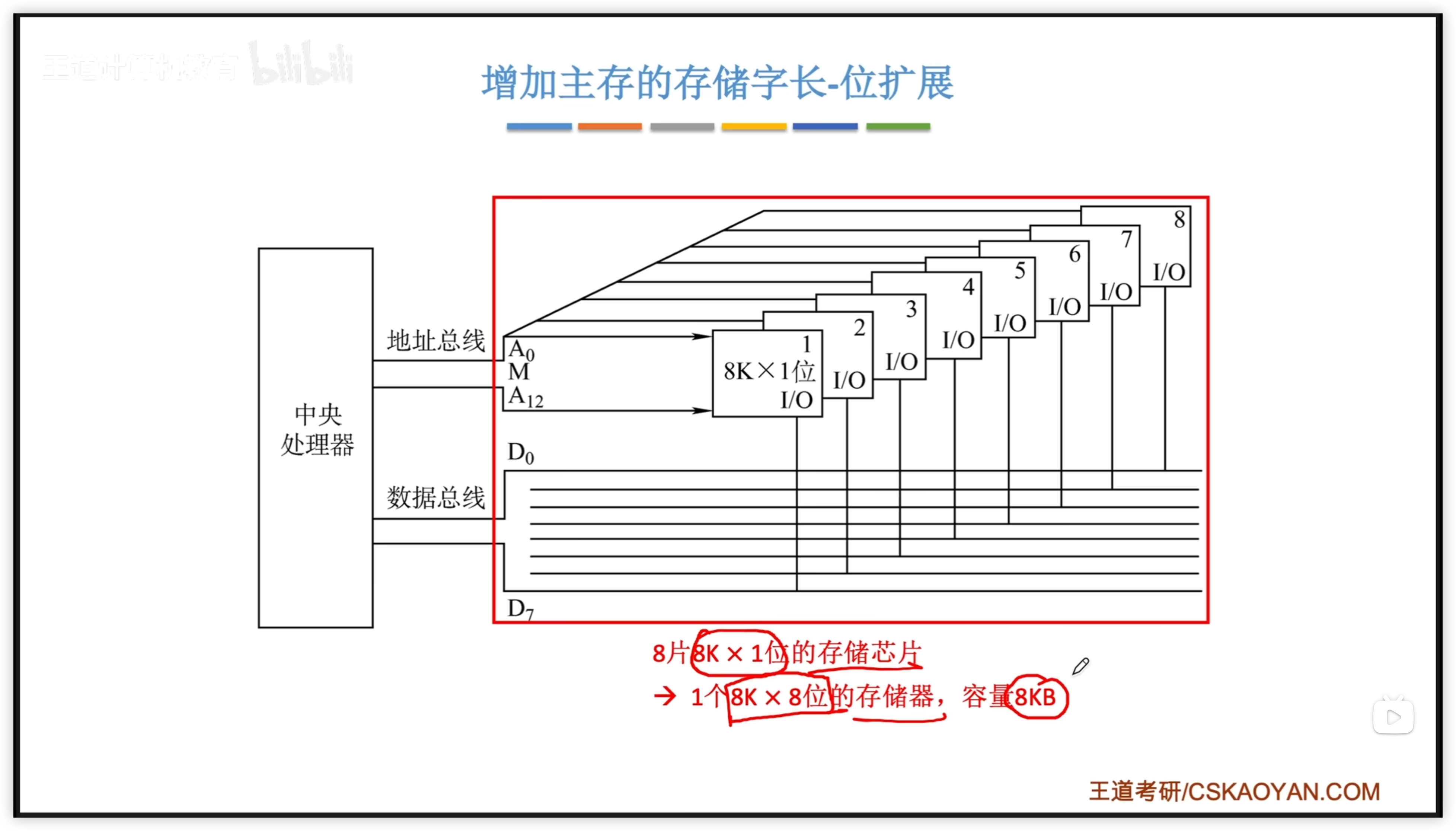
3.3.2 字擴展
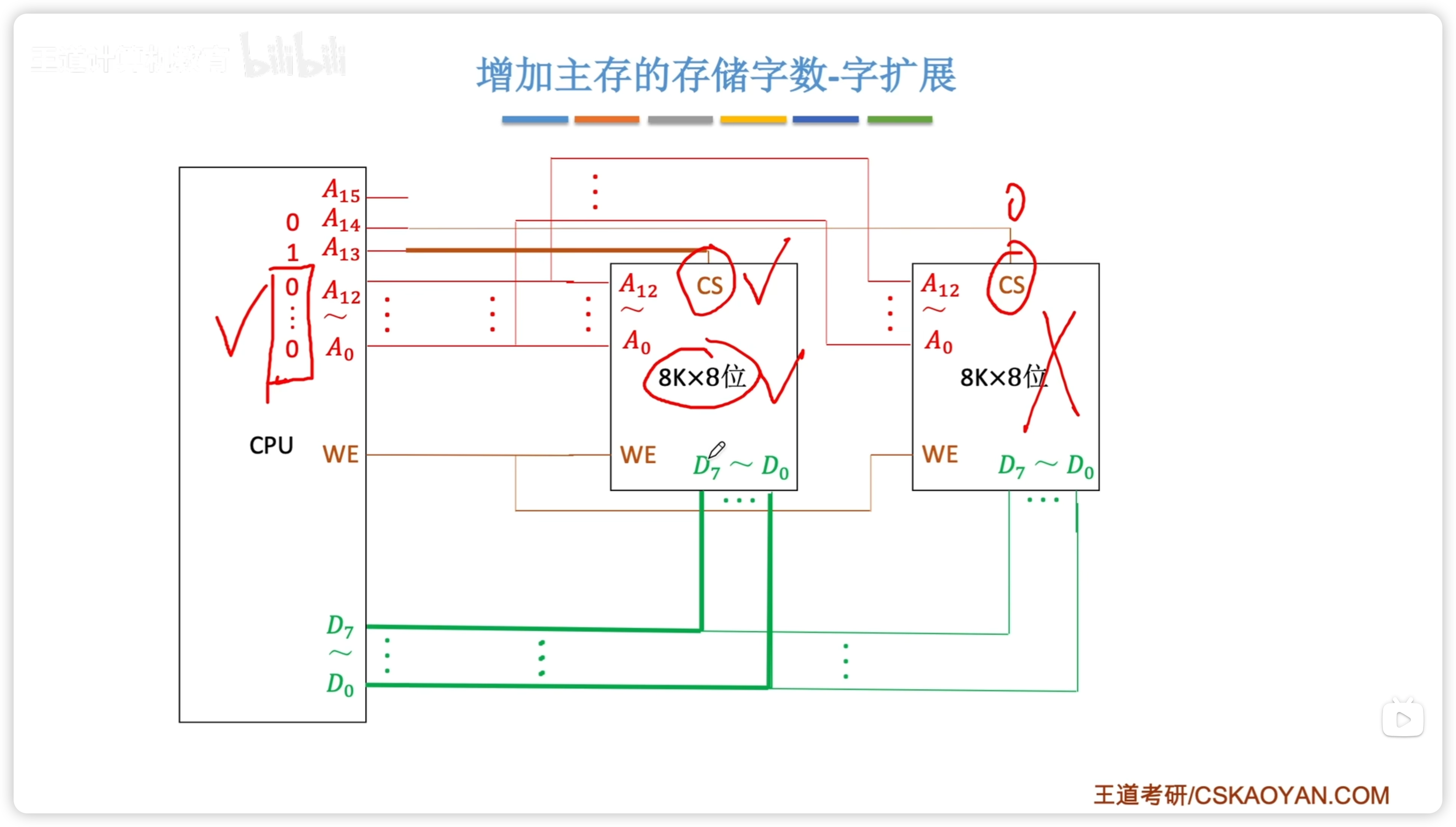
- 用 A13、14 兩位作為片選信號,選擇讀取指定的芯片
使用1-2 譯碼器改進:
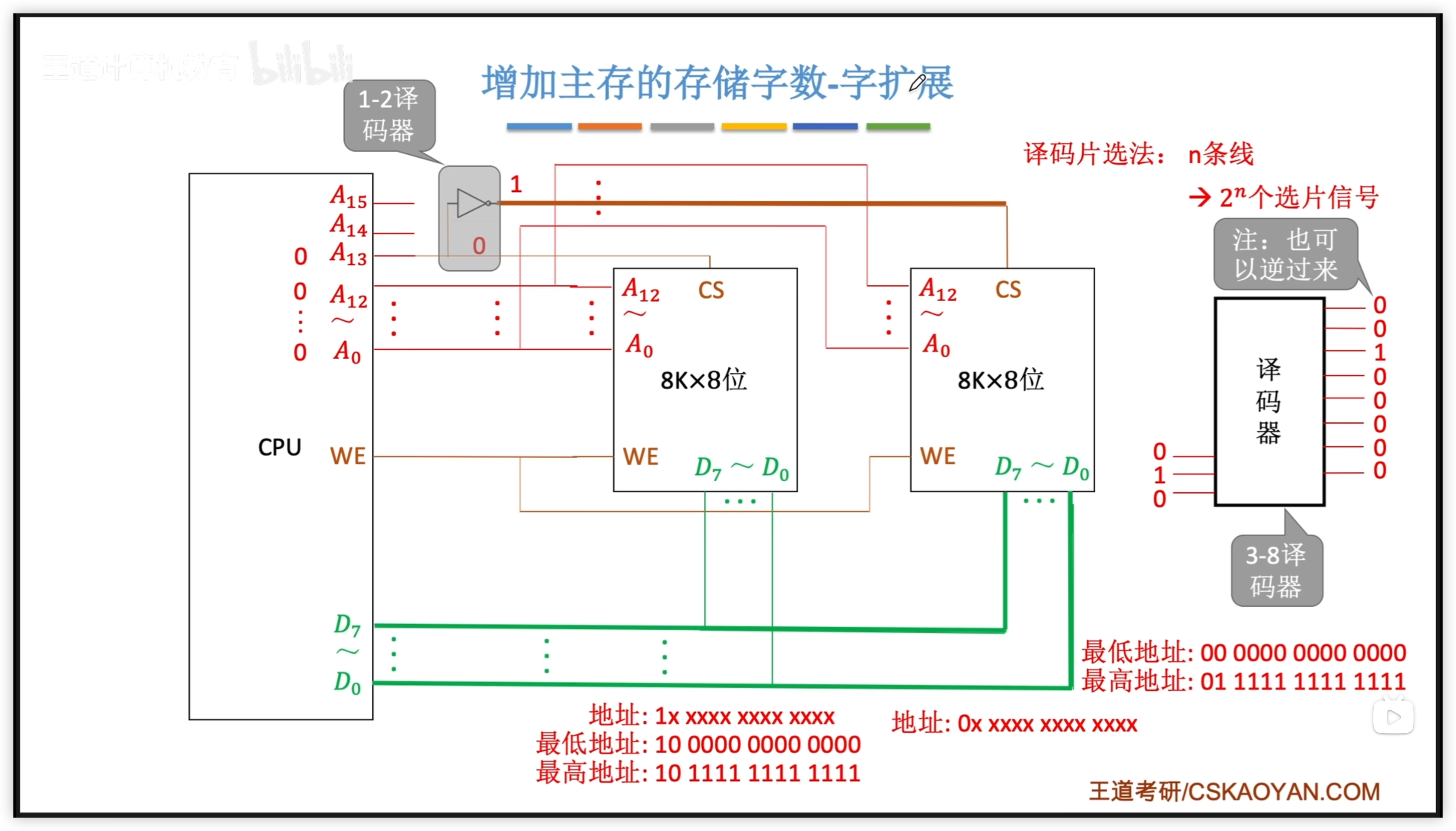
- 原來需要佔用 2 位作為片選信號,現在只需要 1 位(A13)
- 在地址中只佔用 1 位(最高位)
- 譯碼片選法的核心就是
- 注意:
- 圖中 1-2 譯碼器的輸入有一個非門,為了避免產生相同信號(導致同時讀)
- 圖中可以看到地址除最高位外,還有 13 位,對應 A0 ~ A12 這 13 位地址
3-8 譯碼器:
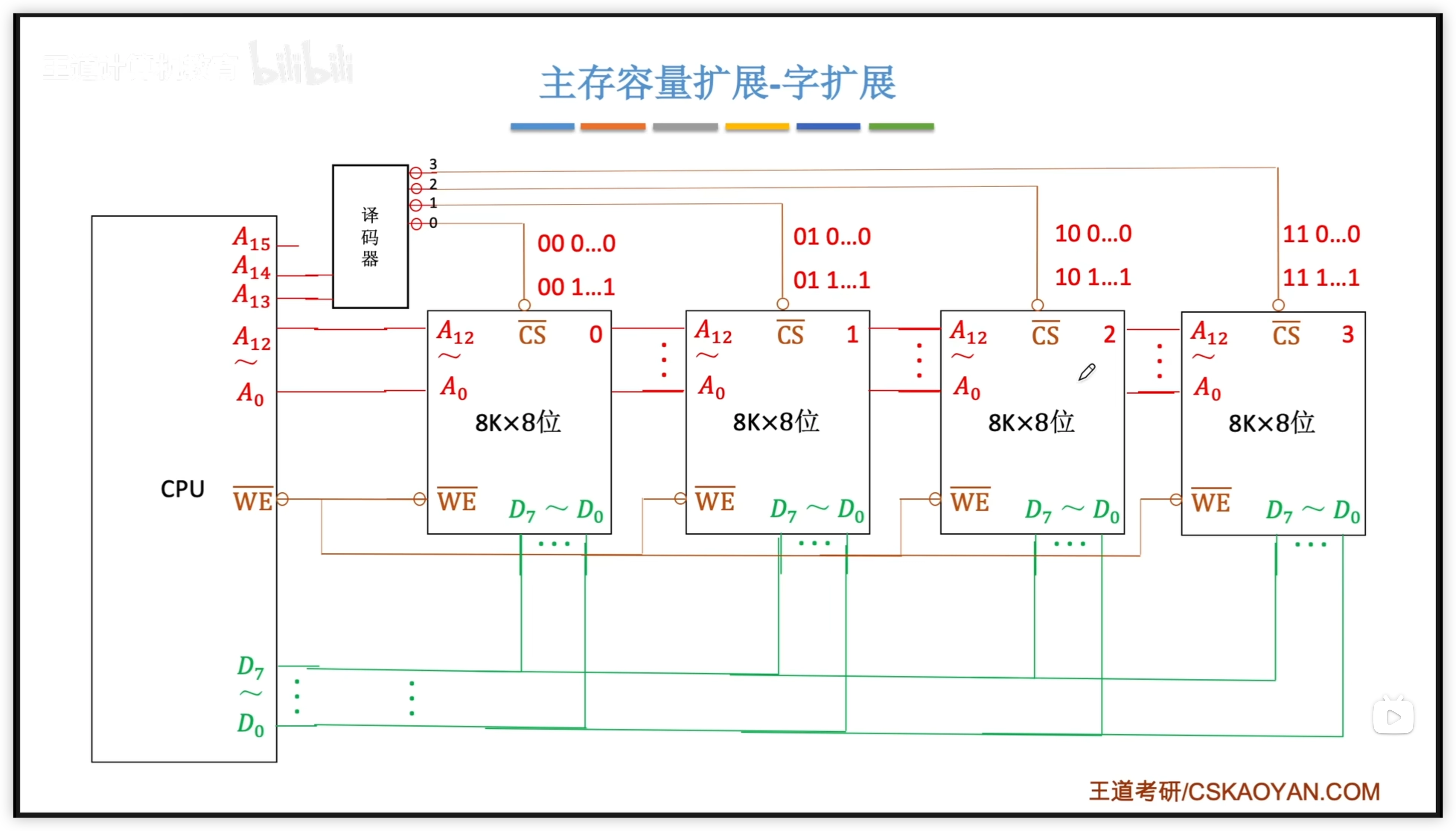
| 線選法 | 譯碼片選法 | |
|---|---|---|
| 選片信號 | n 條線 n個選片信號 | n條線 個選片信號 |
| 電路複雜度 | 電路簡單 | 電路複雜 |
| 地址空間 | 地址空間不連續 | 地址空間連續 |
3.3.3 字位同時擴展
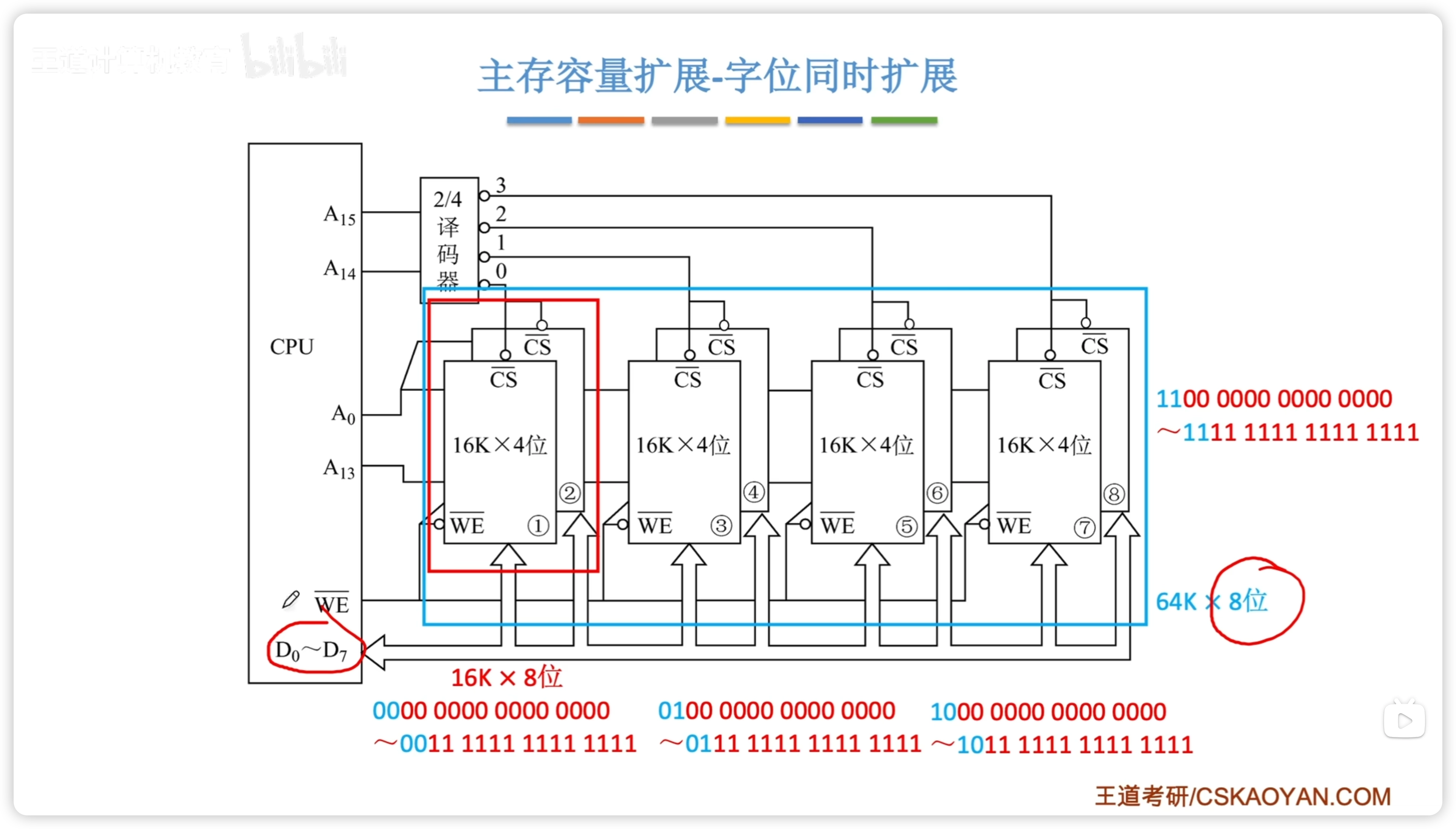
2個四位存儲器芯片疊一起 作為 位擴展,四組疊疊樂 形成 字擴展。
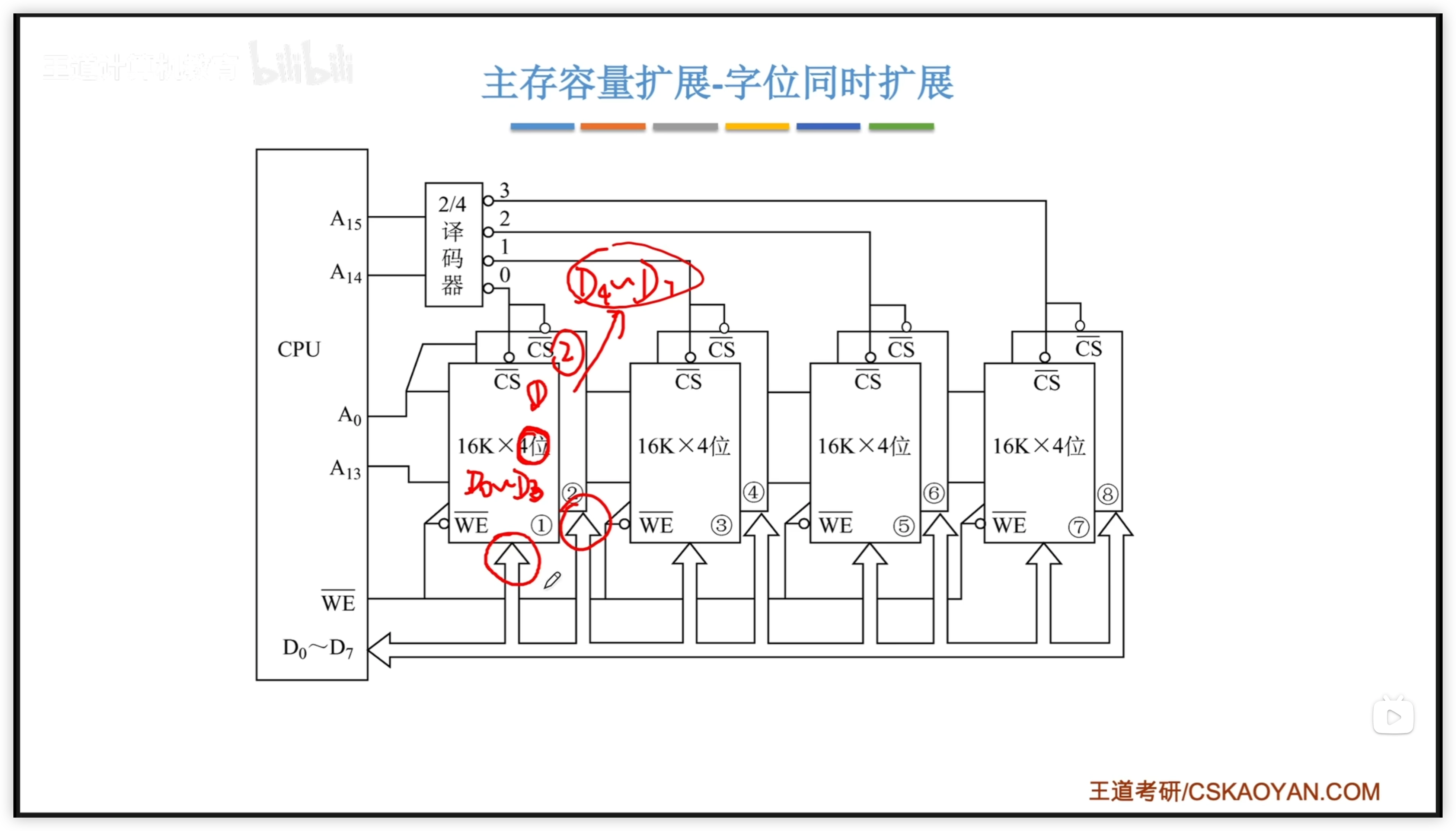
地址如下:
3.4 外部存儲器
3.4.1 磁盤的組成
磁頭、柱面、扇區:

3.4.2 磁盤的性能指標
3.4.2.1 磁盤的容量
- 一個磁盤所能存儲的字節總數稱為磁盤容量。磁盤容量有非格式化容量和格式化容量之分。
- 非格式化容量是指磁記錄表面可以利用的磁化單元總數。
- 格式化容量是指按照某種特定的記錄格式所能存儲信息的總量。
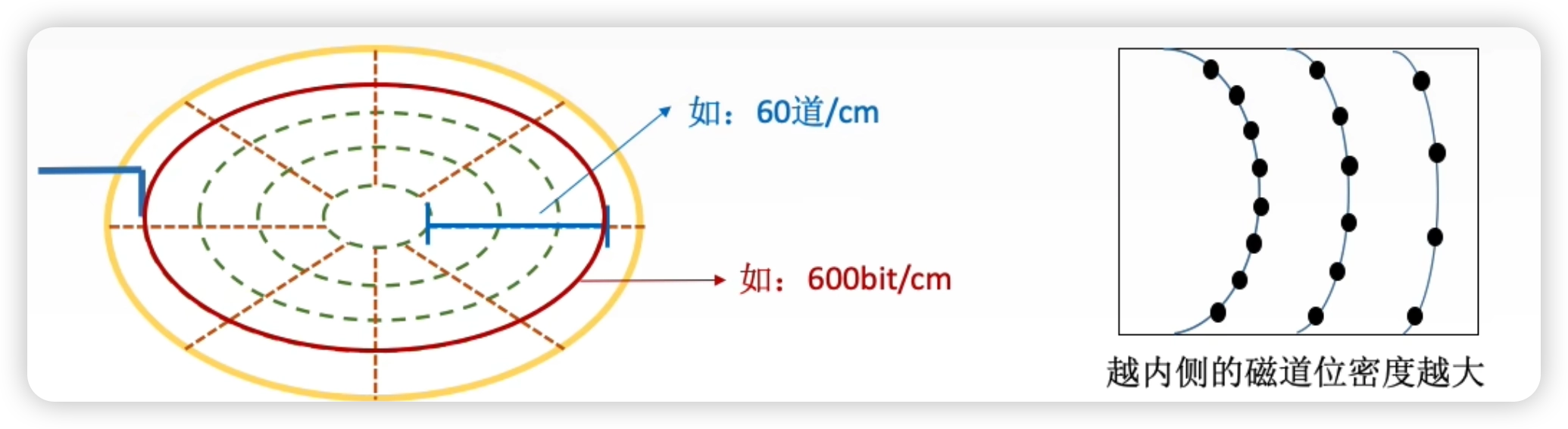
記錄密度
記錄密度是指盤片單位面積上記錄的二進制的信息量,通常以道密度、位密度和麵密度表示。
- 道密度是沿磁盤半徑方向單位長度上的磁道數;
- 位密度是磁道單位長度上能記錄的二進制代碼位數;
- 越內側的磁道,位密度越大
- 面密度是 位密度 和 道密度 的乘積。
- 注意:磁盤所有磁道記錄的信息量一定是相等的,並不是圓越大信息越多,故每個磁道的位密度都不同。
平均存取時間
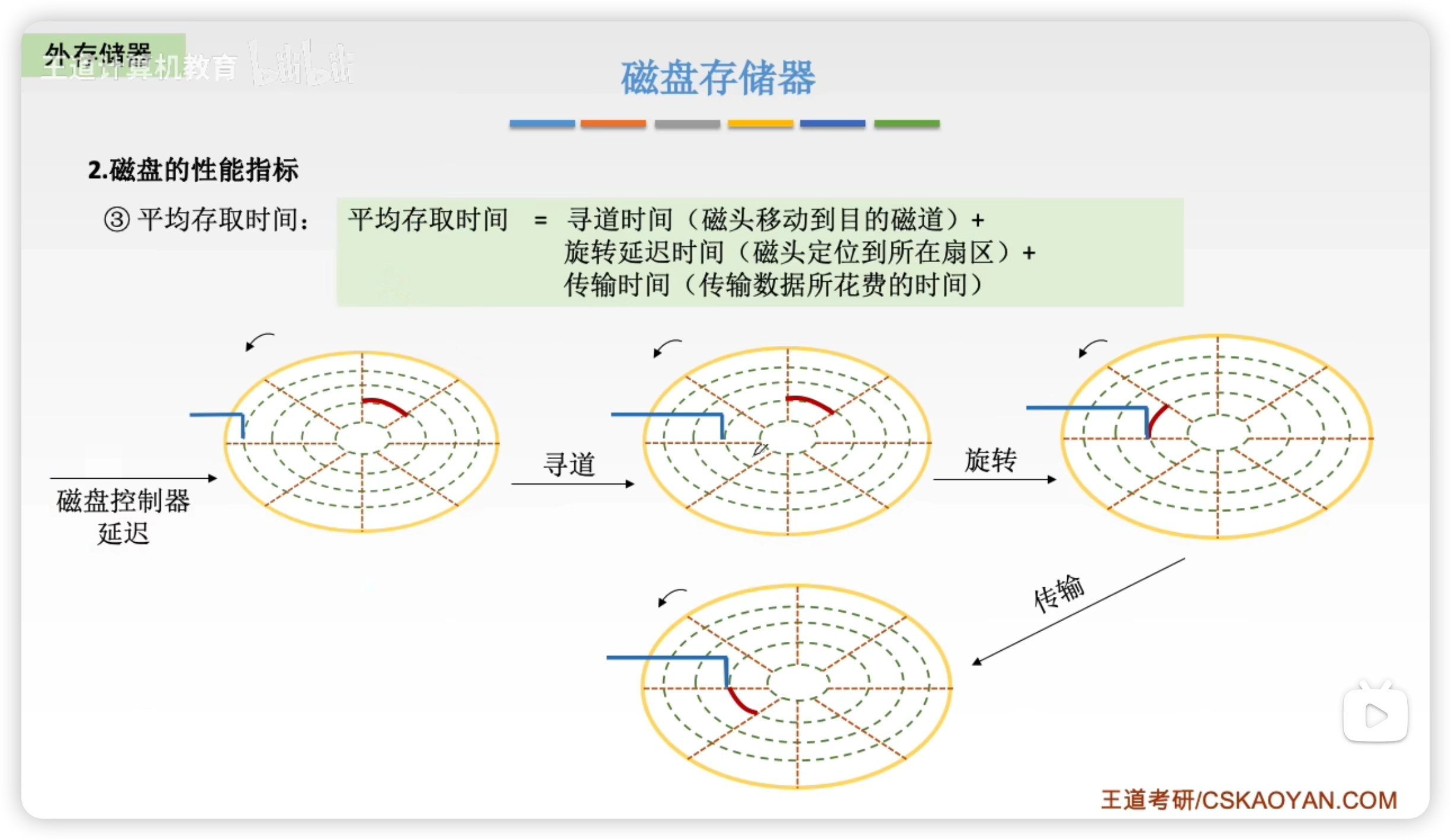
注意:
- 傳輸時間可以根據轉速計算,約等於掃過一個扇區的時間,即
數據傳輸率
磁盤存儲器在單位時間內向主機傳送數據的字節數,稱為數據傳輸率。
假設磁盤轉數為 (轉/秒),每條磁道容量為 個字節,則數據傳輸率為
3.4.3 磁盤地址
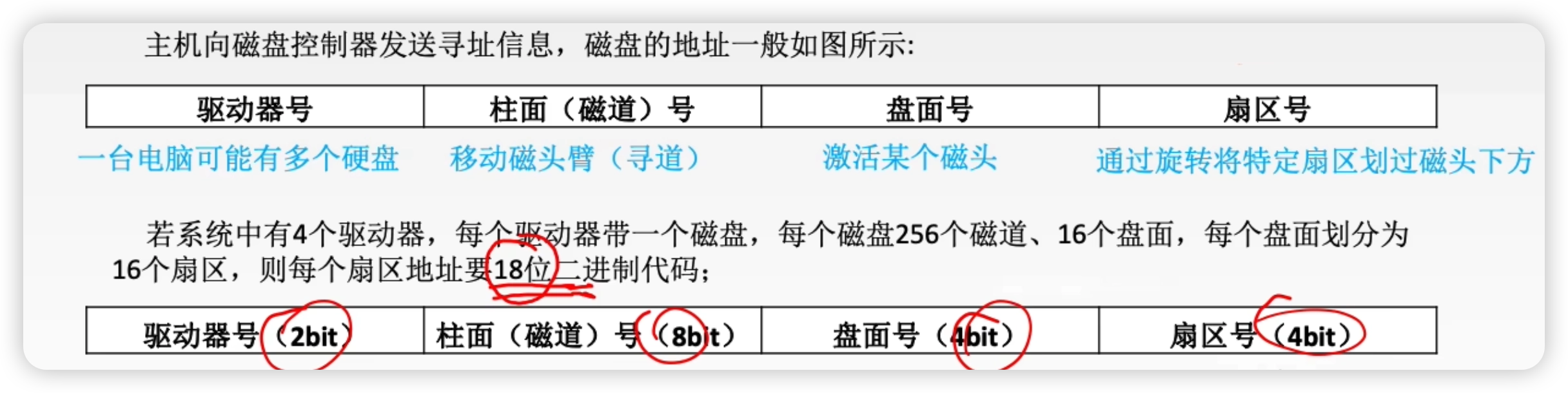
3.4.4 磁盤工作過程
硬盤的主要操作是尋址、讀盤、寫盤。每個操作都對應一個控制字,硬盤工作時,第一步是取控制字,第二步是執行控制字。
硬盤屬於機械式部件,其讀寫操作是串行的,不可能在同一時刻既讀又寫,也不可能在同一時刻讀兩組數據或寫兩組數據。
改進:磁盤陣列
和低位交叉的思想類似,實現並行訪問
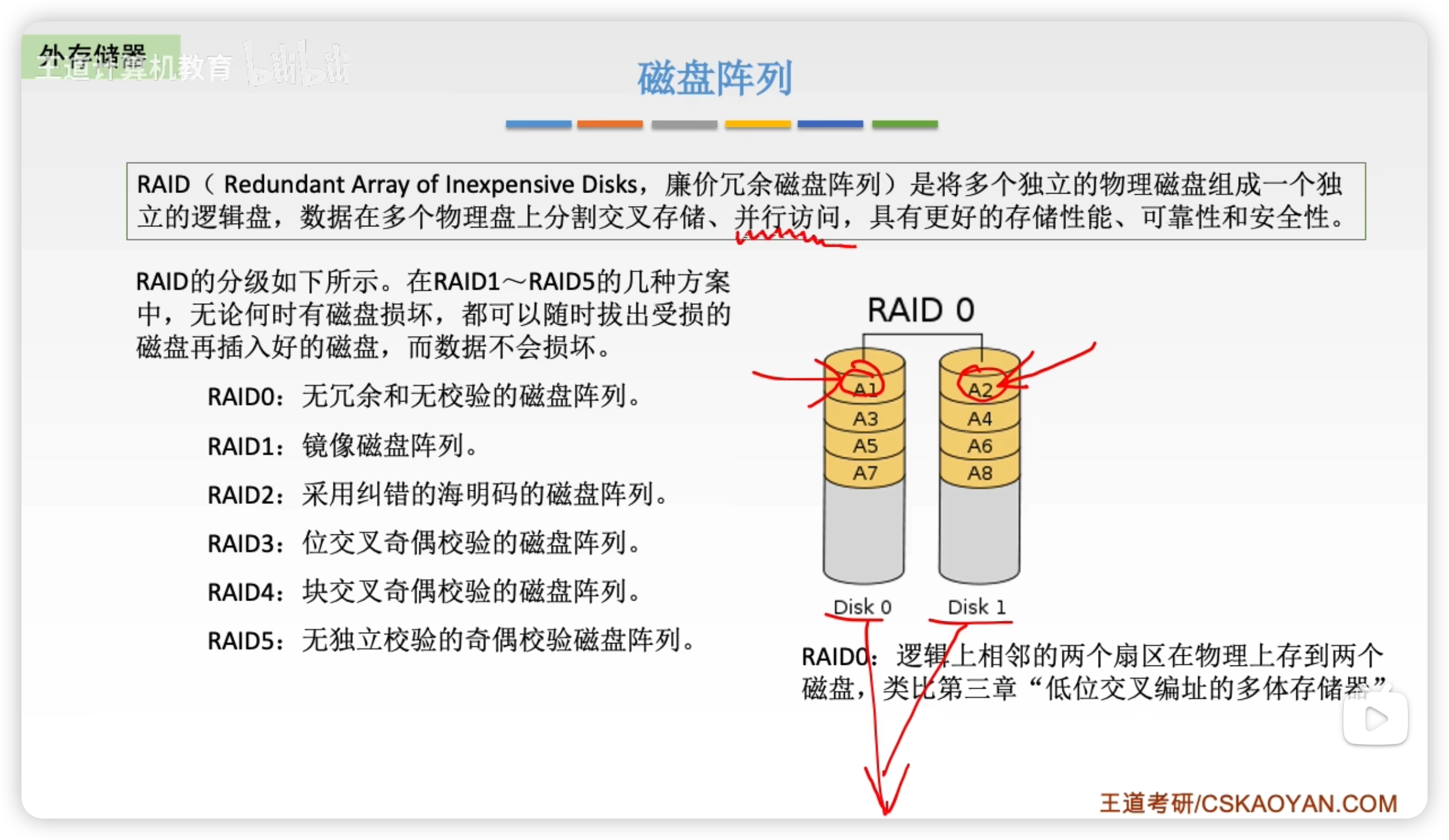
- RAID0 把連續多個數據塊交替地存放在不同物理磁盤的扇區中,幾個磁盤交叉並行讀寫,不僅擴大了存儲容量,而且提高了磁盤數據存取速度
- 但 RAID0 沒有容錯能力。
- RAID1 是為了提高可靠性,使兩個磁盤同時進行讀寫,互為備份,提供了容錯。
- 但是兩個磁盤完全一致,意味著總容量減少一半,成本大。
- 之後 RAID 通過數據校驗,保證安全性,且級數越大,冗餘信息越少,成本越低。
3.4.5 固態硬盤
SSD 基於閃存技術(Flash Memory),屬於電可擦除ROM(即EEPROM)。
組成:
- 有閃存翻譯層(負責翻譯邏輯塊號,找到對應頁)
- 存儲介質為多個閃存芯片
- 每個芯片含多個塊,每個塊含多個頁。
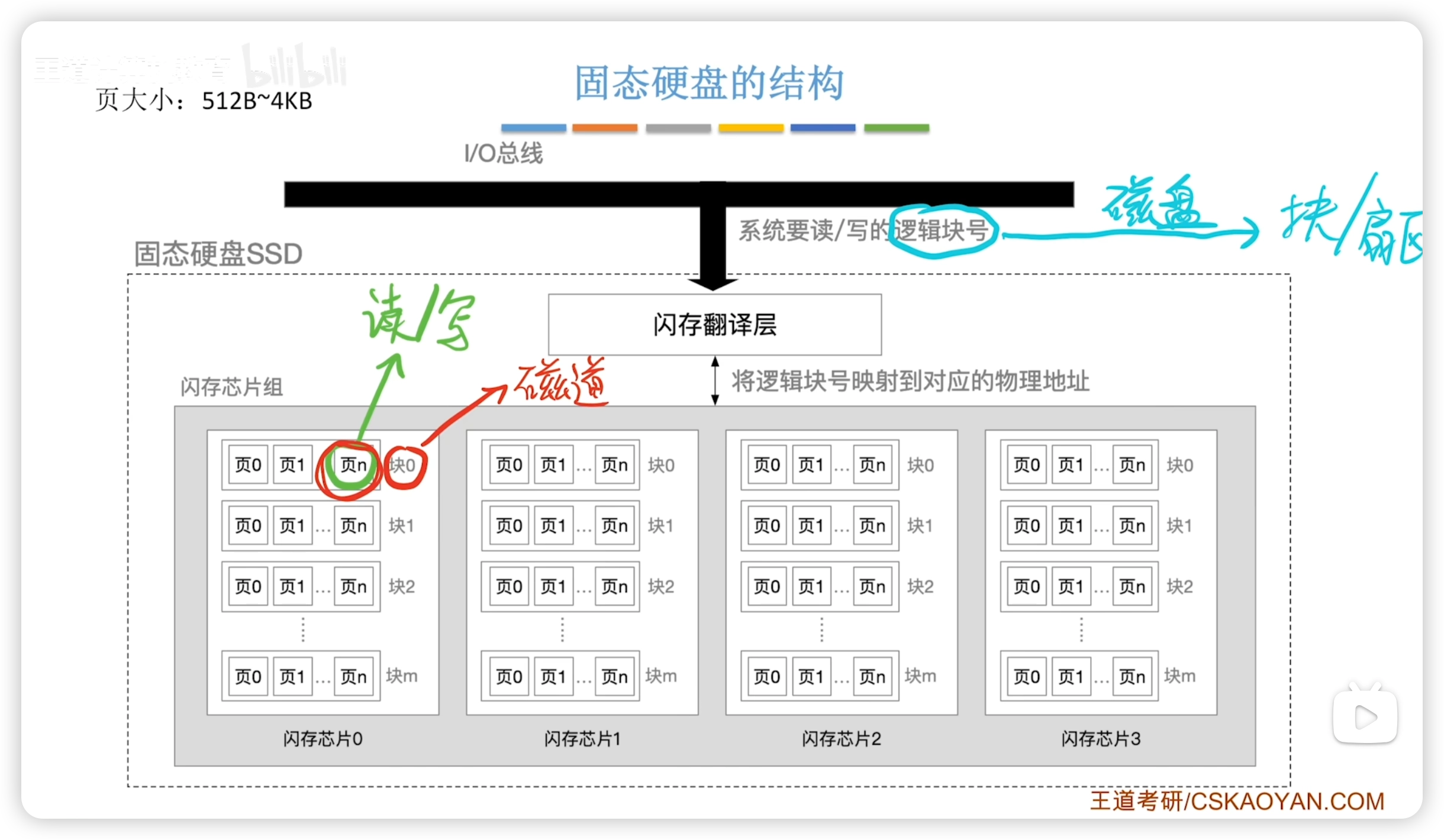
SSD 的讀寫是以頁為單位的,而磁盤是以 扇區為單位。
- SSD 的若干頁組成的一個塊,相當於磁盤中的一個磁道
讀寫性能特性:
- 以頁為單位讀/寫(相當於磁盤“扇區”);
- 以塊為單位擦除,擦乾淨的塊中每頁可寫一次、讀無限次;
- 支持隨機訪問,能通過電路由邏輯地址迅速定位物理地址;
- 讀快、寫慢
- 如果寫的頁若有數據,由於寫入需要擦除一整塊的數據,所以需將塊內其他頁複製到新擦除塊後,再寫入新頁
- 同時,閃存翻譯層會把地址映射到新的塊
與機械硬盤相比的特點:
- 讀寫速度快、隨機訪問性能高,靠電路控制訪問位置
- 機械硬盤靠移動磁臂和旋轉磁盤,有尋道時間和旋轉延遲
- 安靜無噪音、耐摔抗震、能耗低但造價更貴
- SSD的“塊”擦除次數過多可能損壞,機械硬盤扇區不會因寫次數多損壞。
磨損均衡技術:
- 思想是將“擦除”平均分佈在各塊以提升使用壽命
- 動態磨損均衡是寫入數據時優先選累計擦除次數少的新閃存塊
- 靜態磨損均衡是SSD監測並自動進行數據分配、遷移,讓老閃存塊承擔以讀為主的存儲任務,較新閃存塊承擔更多寫任務。
3.5 高速緩衝存儲器 Cache
3.5.1 Cache 基本原理
局部性原理
時間局部性:一個內存位置被重複引用 空間局部性:一個內存位置被引用後,其附近的位置也很快被引用
由於存在空間局部性,所以 Cache 是一種高效的設置。
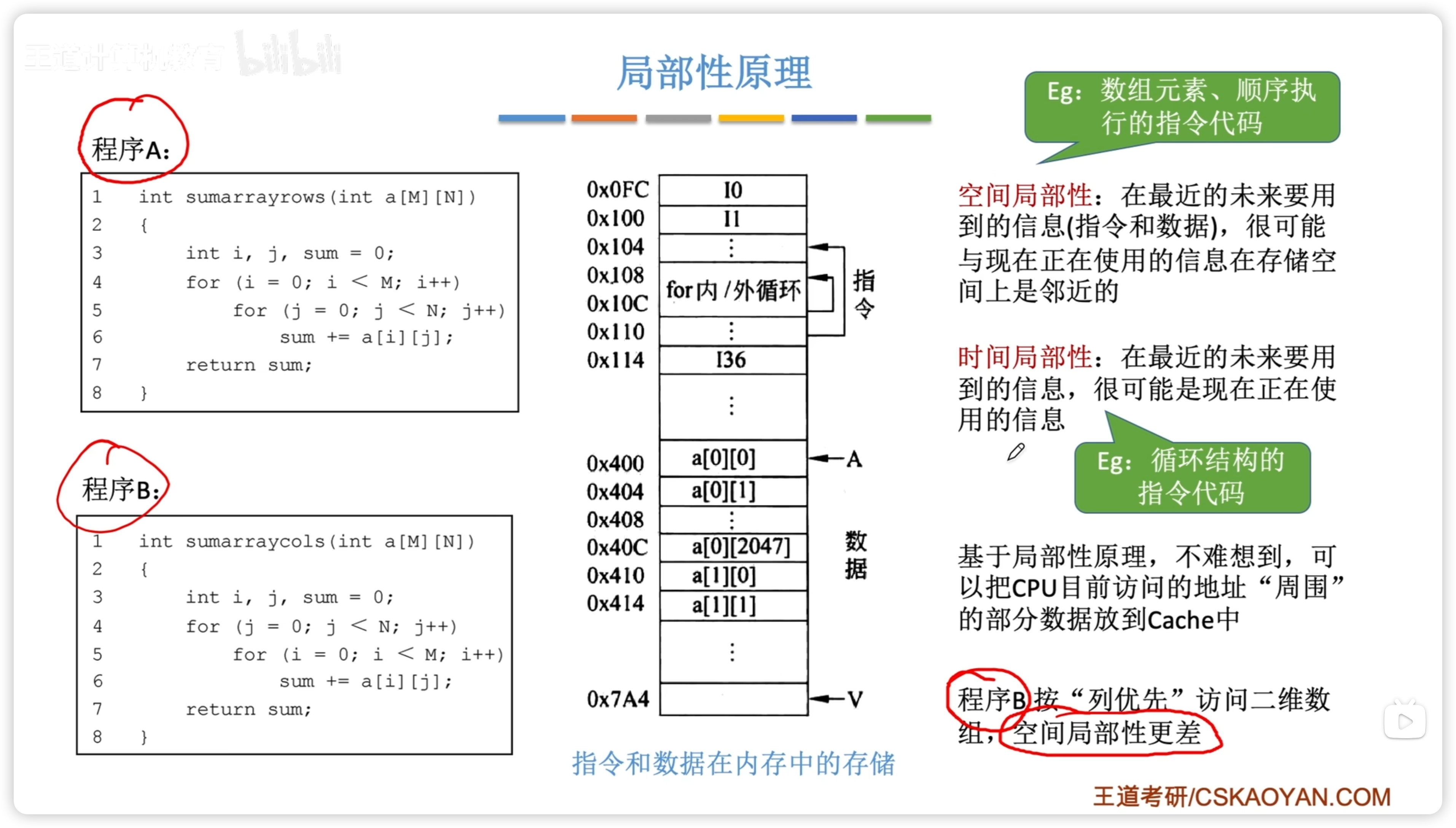
對於連續排列的數組數據,按列優先訪問的形式 B(會跳著訪問),顯然空間局部性更差。
而正常連續訪問的方式 A 的訪問時間會短,因為周圍數據都在 Cache 中。
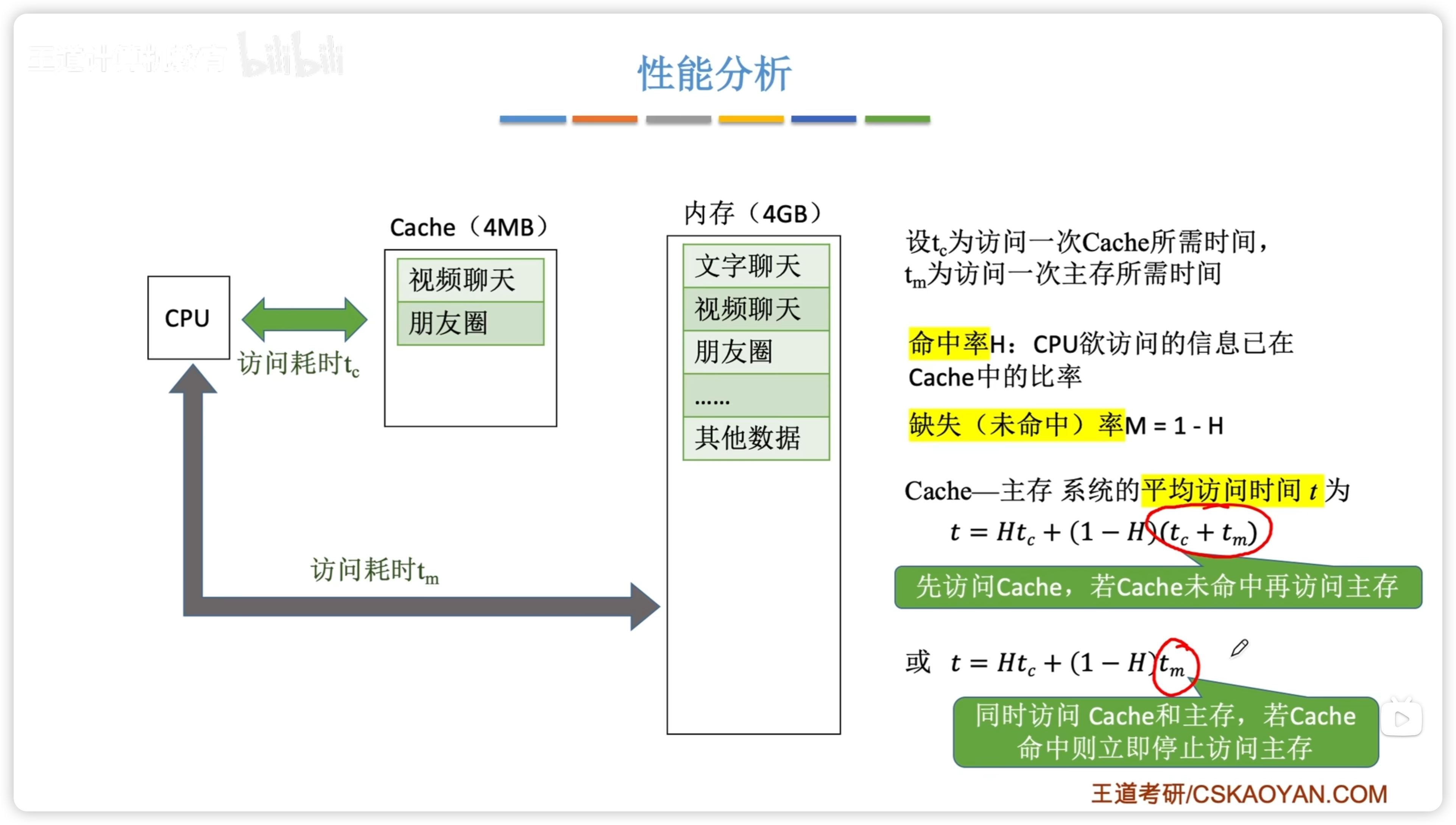
性能分析
- Cache 和 主存同時訪問
- Cache 未命中之後,再訪問主存
按塊交換
- 將主存的存儲空間“分塊”,e.g. 每1KB為一塊。
- 主存與 Cache 之間以塊為單位進行數據交換。
- Cache塊大小與主存塊大小相同
- 但是數量不同,故主存塊號和 Cache塊號(行號)的位數不同
- 注意,CPU 與 Cache或主存 之間以字為單位傳送信息
- Cache塊大小與主存塊大小相同
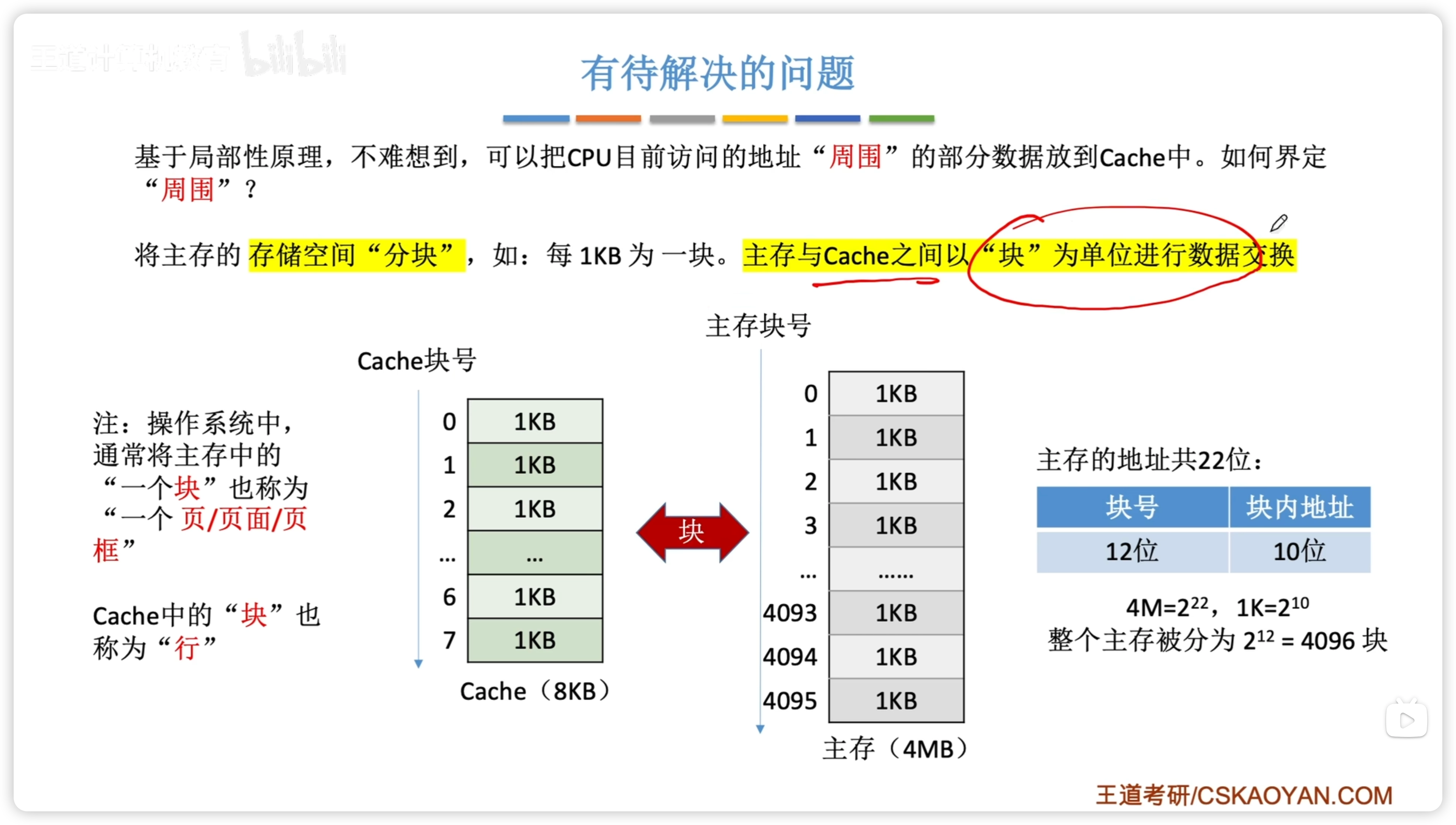
自然地,主存地址由塊號 + 塊內地址組成。
- 主存地址就是主存物理地址
Cache 行
- 計算題:Cache 容量、地址映射表大小
一個 Cache 行分為: 控制算法位 + 數據部分
- 控制算法位:有效位 + 替換算法位 + 髒位 + 標記位(tag)
- 地址映射表就是指所有行的控制算法位
- 髒位也叫一致性維護位
- 不同的映射算法,標記位長度也不同
Cache 衝突:兩個主存單元映射到同一個 Cache 行
- 對於組相聯,同一組號即算衝突
3.5.2 Cache 與主存的映射
三種映射方式:
- 全相聯映射:任意位置
- 直接映射:每個主存塊有一個特定的位置
- 組相聯映射:每個主存塊可以放到一個特定的組
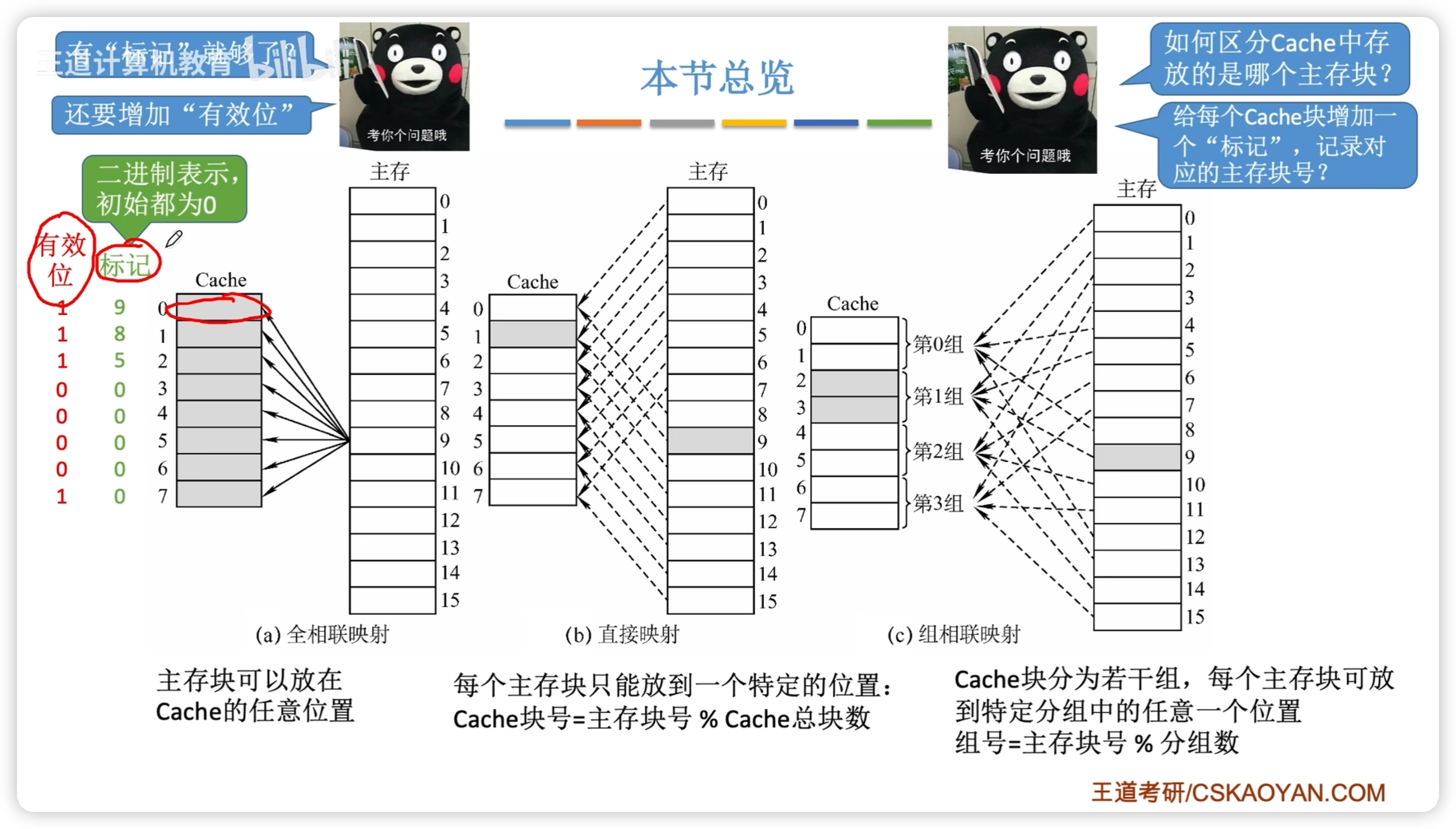
注意,不僅需要標記位,還需要有效位。
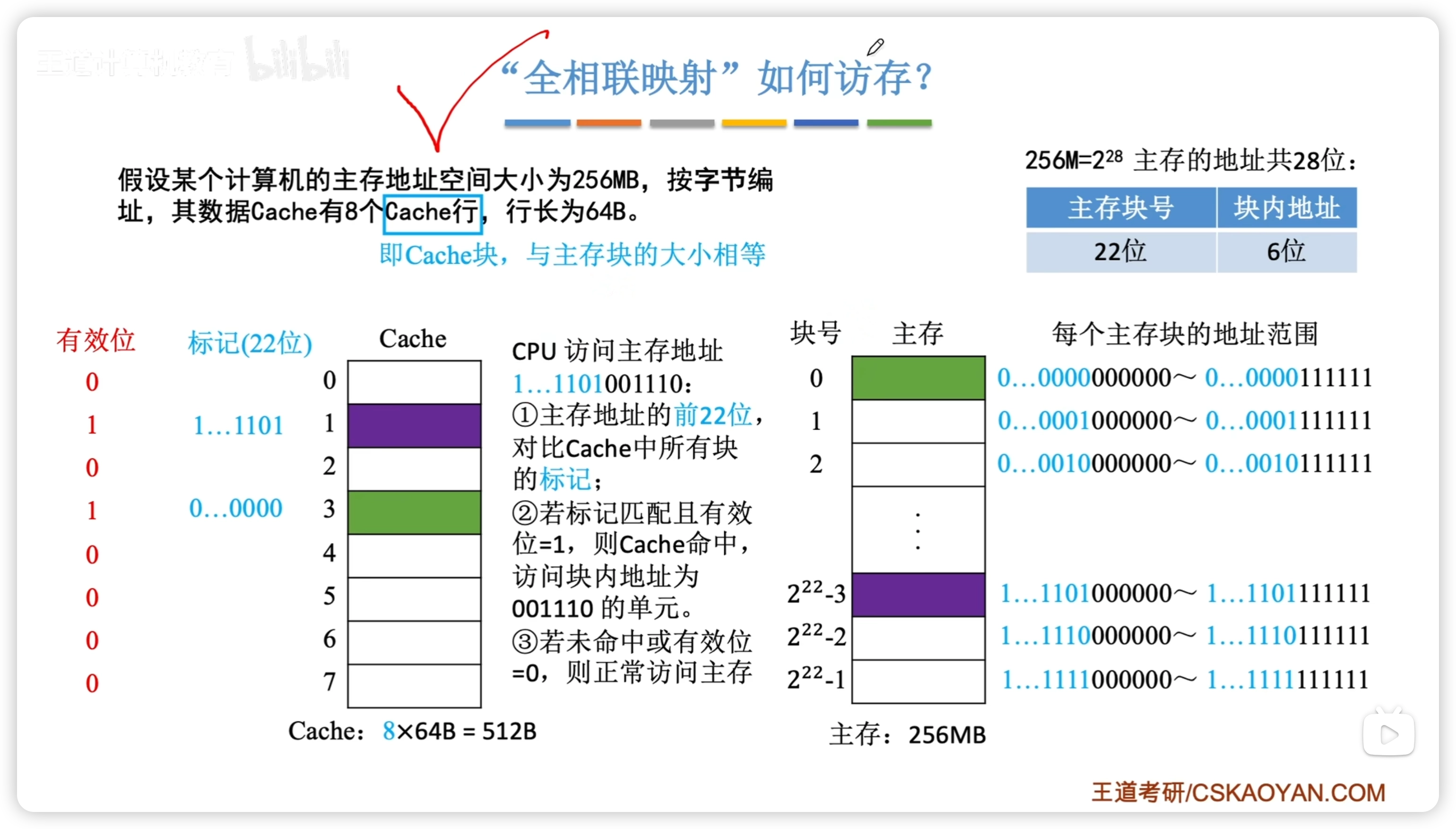
全相聯映射
- 主存地址的前22位對比 Cache 中的所有塊的標記 1. 主存塊號(高22位)在 Cache 中 且有效位 = 1,則 Cache 命中。2. 未命中則正常訪問主存
直接映射
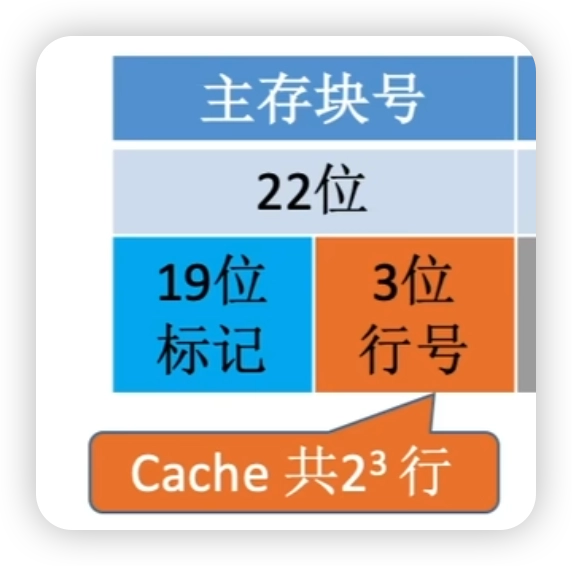
- 根據主存塊號的後3位確定 Cache 行
- 若主存塊號的前19位與Cache標記匹配 且 有效位 = 1,則 Cache 命中
- 若未命中或有效位=0,則正常訪問主存
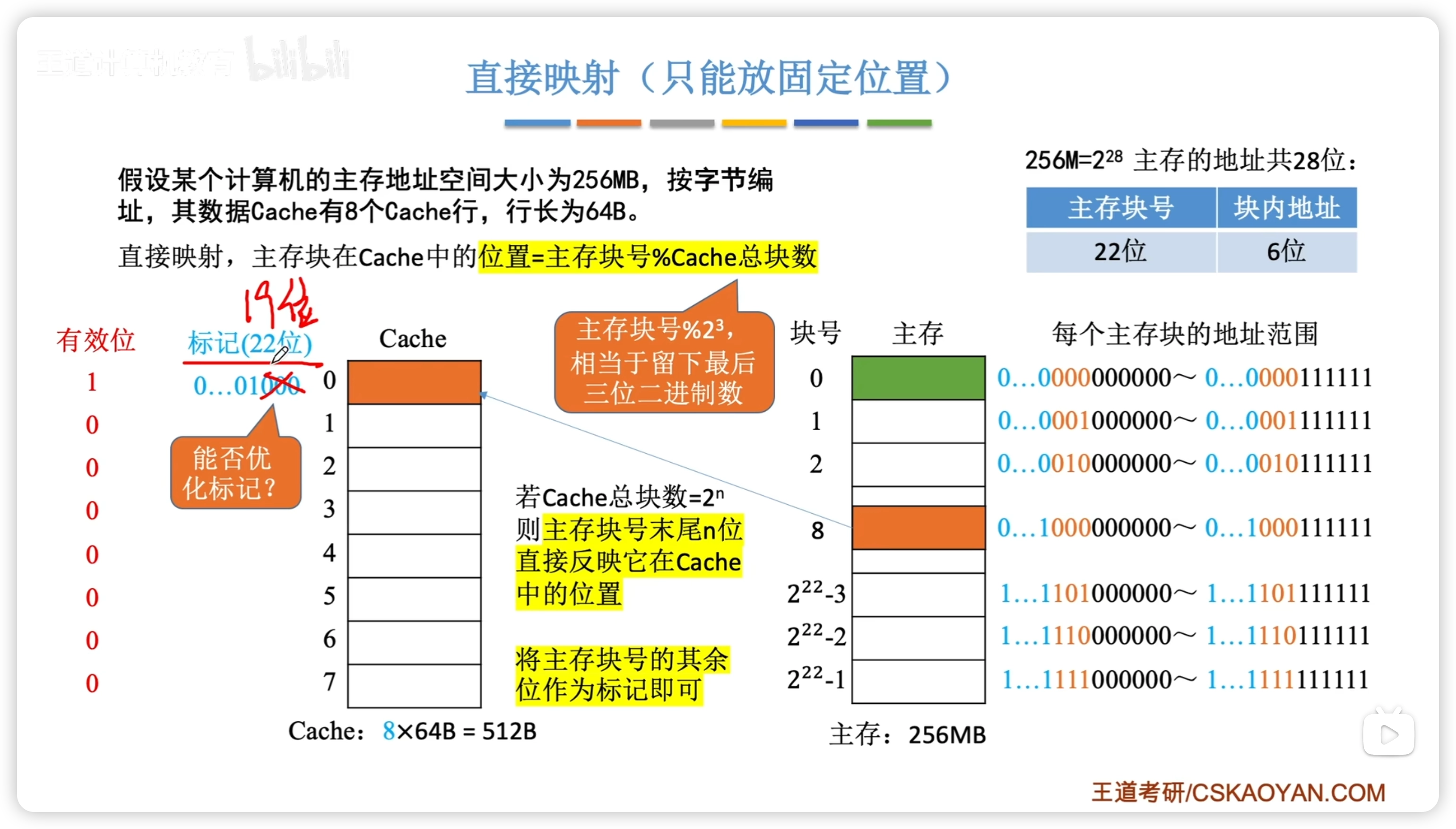
- 缺點:不同主存塊對應同一 Cache 位置時,浪費其餘空閒空間
- 由於塊在 Cache 中的位置恰對應主存塊號的低3位,所以標記位只用存19位。- 主存塊號 = 標記位 + Cache行號
組相聯映射
- 根據主存塊號的後2位確定所屬分組號
- 若主存塊號的前20位與分組內的某個標記匹配且有效位 = 1, 則 Cache 命中
- 若未命中或有效位=0,則正常訪問主存
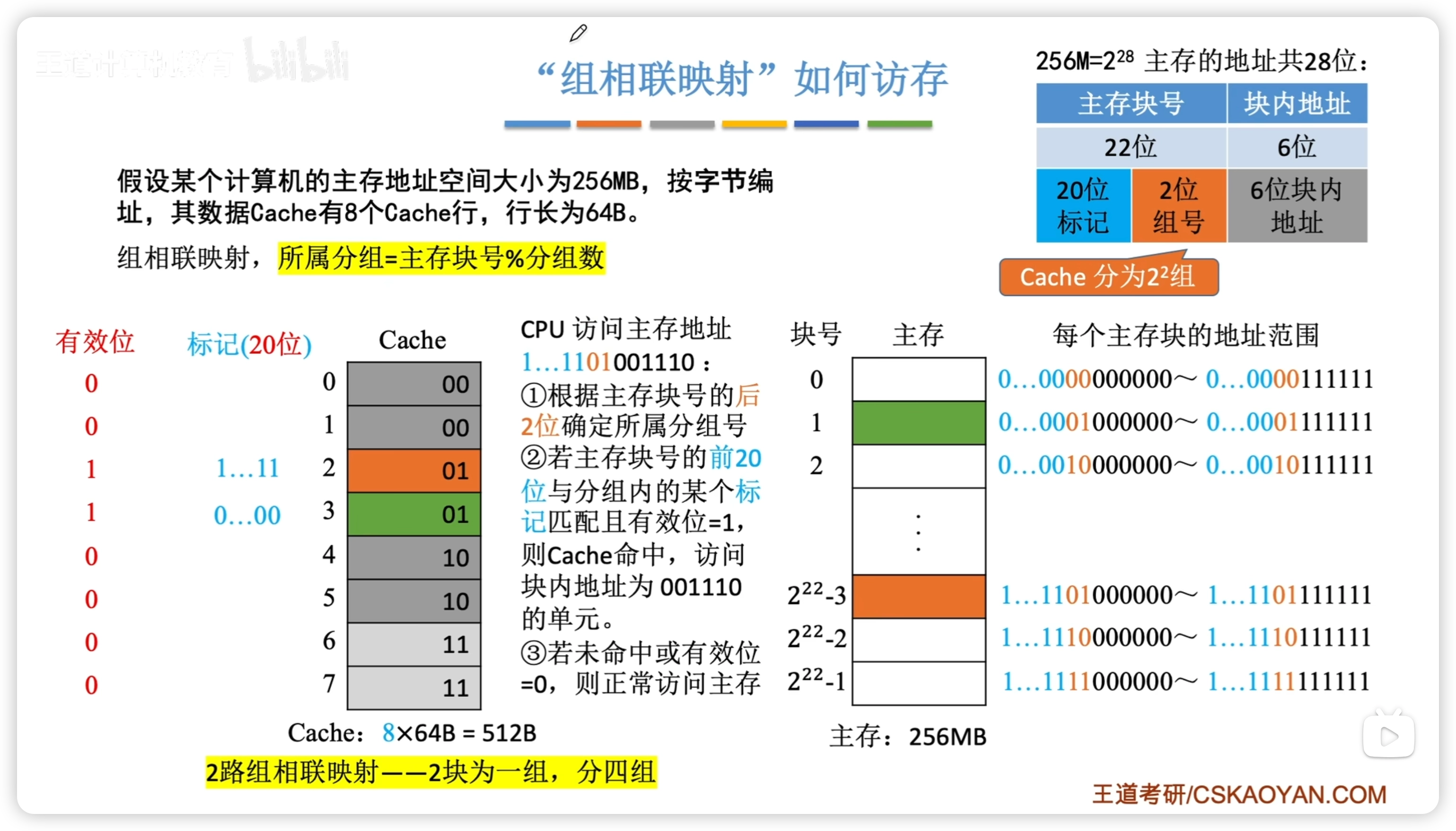
- 2路組相聯映射:2塊一組
- 組相聯綜合性能最好
- 主存塊號 = 標記位 + Cache組號
3.5.3 Cache 替換算法
- 隨機算法
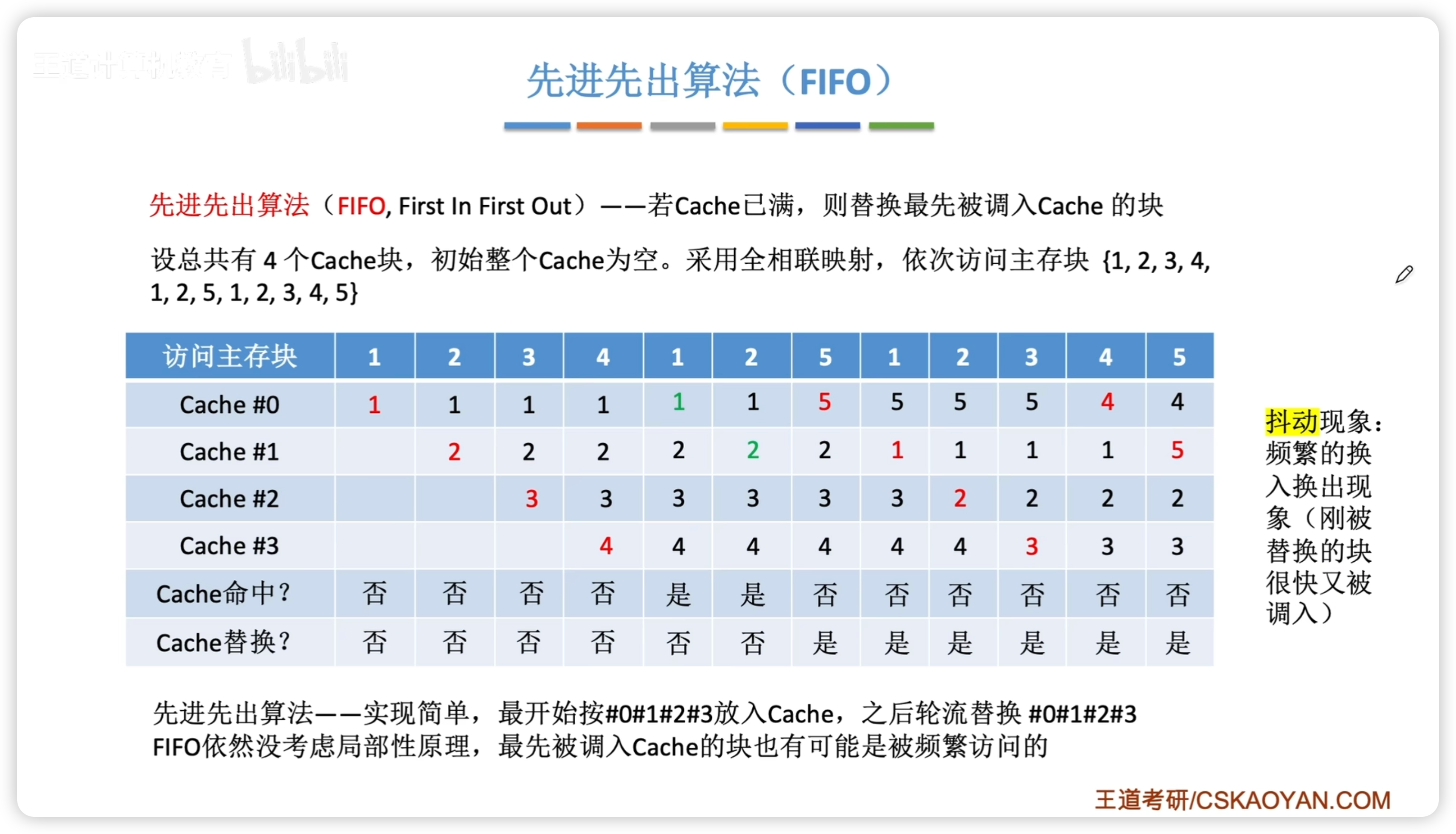
- 先進先出 FIFO
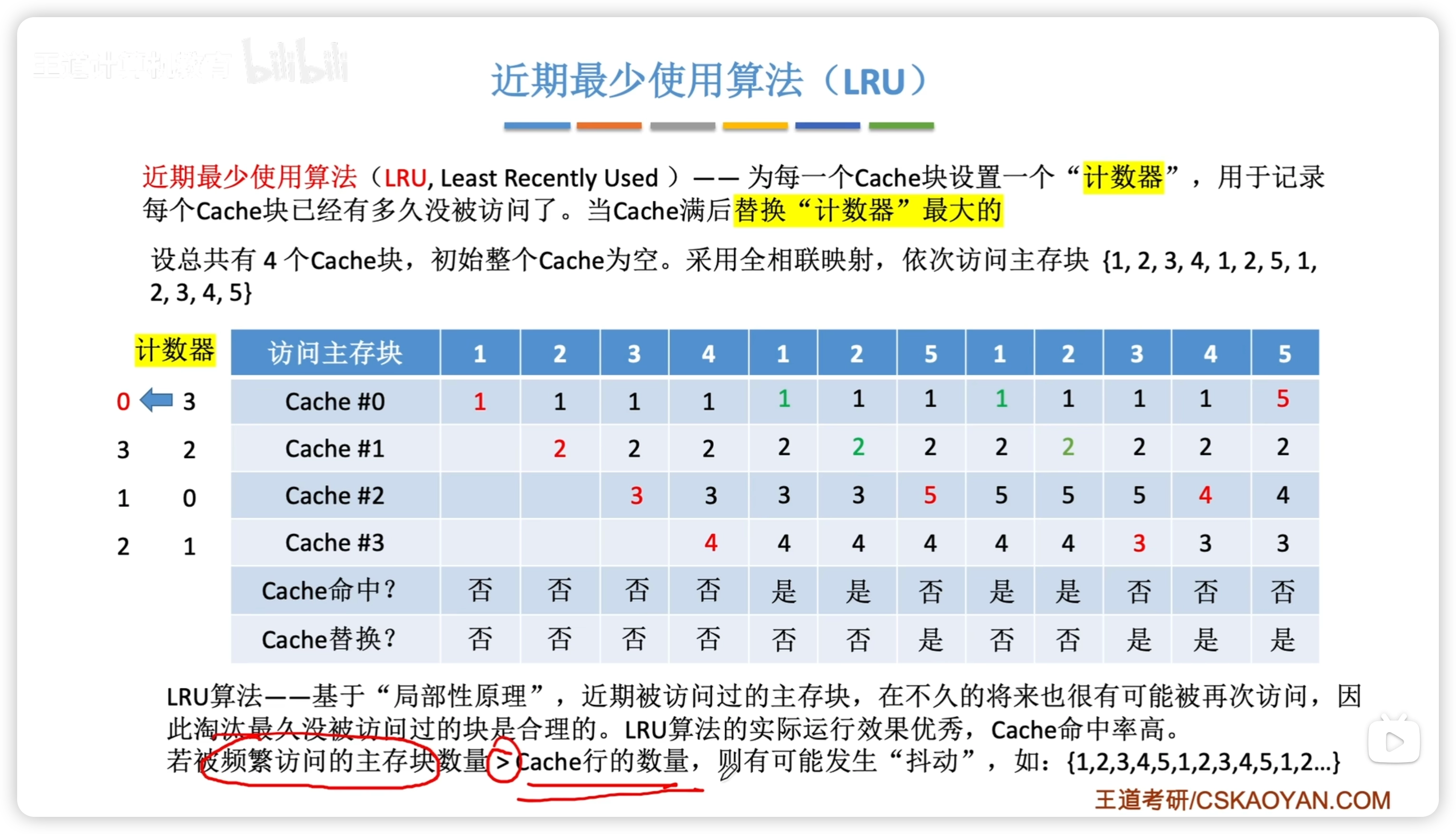
- 近期最少使用 LRU 1. Least Recently Used 2. 基於局部性原理,性能最好 3. 規則 1. 命中時,所命中的行的計數器清零,比其低的計數器加 1,其餘不變 2. 未命中且有空閒行時,新裝入行的計數器置 0,其餘非空閒行全加 1 3. 未命中且無空閒行時,計數值最大的行被淘汰,新裝行的計數器置 0,其餘全加 1
- 最不經常使用 1. Least Frequently Used 2. 規則 1. 新調入的塊計數器置 0,之後每被訪問一次計數器 + 1 2. 需要替換時,選擇計數器最小的一行
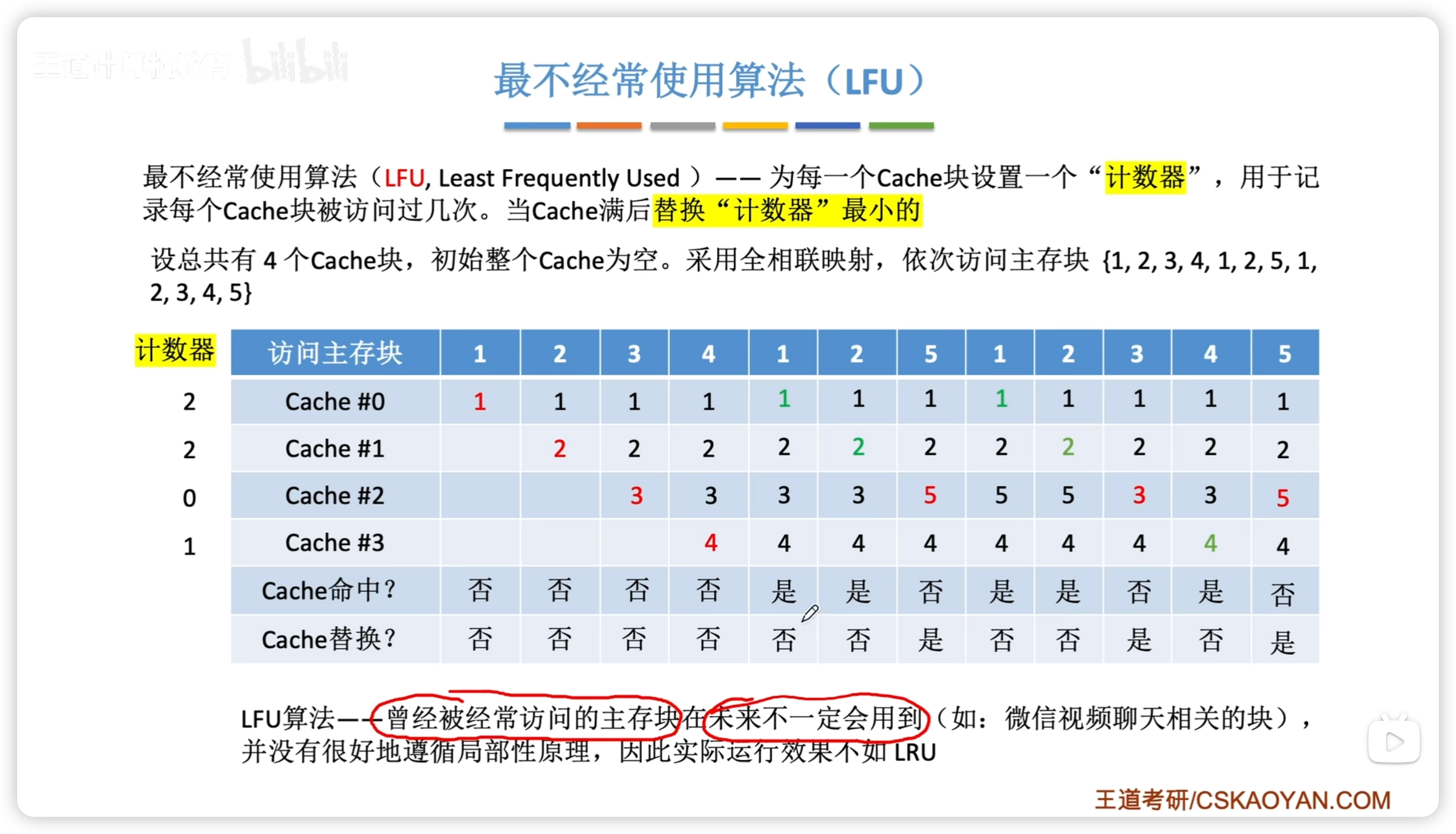
實際做題中,不用模擬計數器,替換的時候按照策略很容易判斷哪個該替換。
3.5.4 Cache 寫策略
CPU 對 Cache 的寫操作可能導致 Cache 與主存的數據不一致,為了解決這個一致性問題,引入了以下的寫策略。
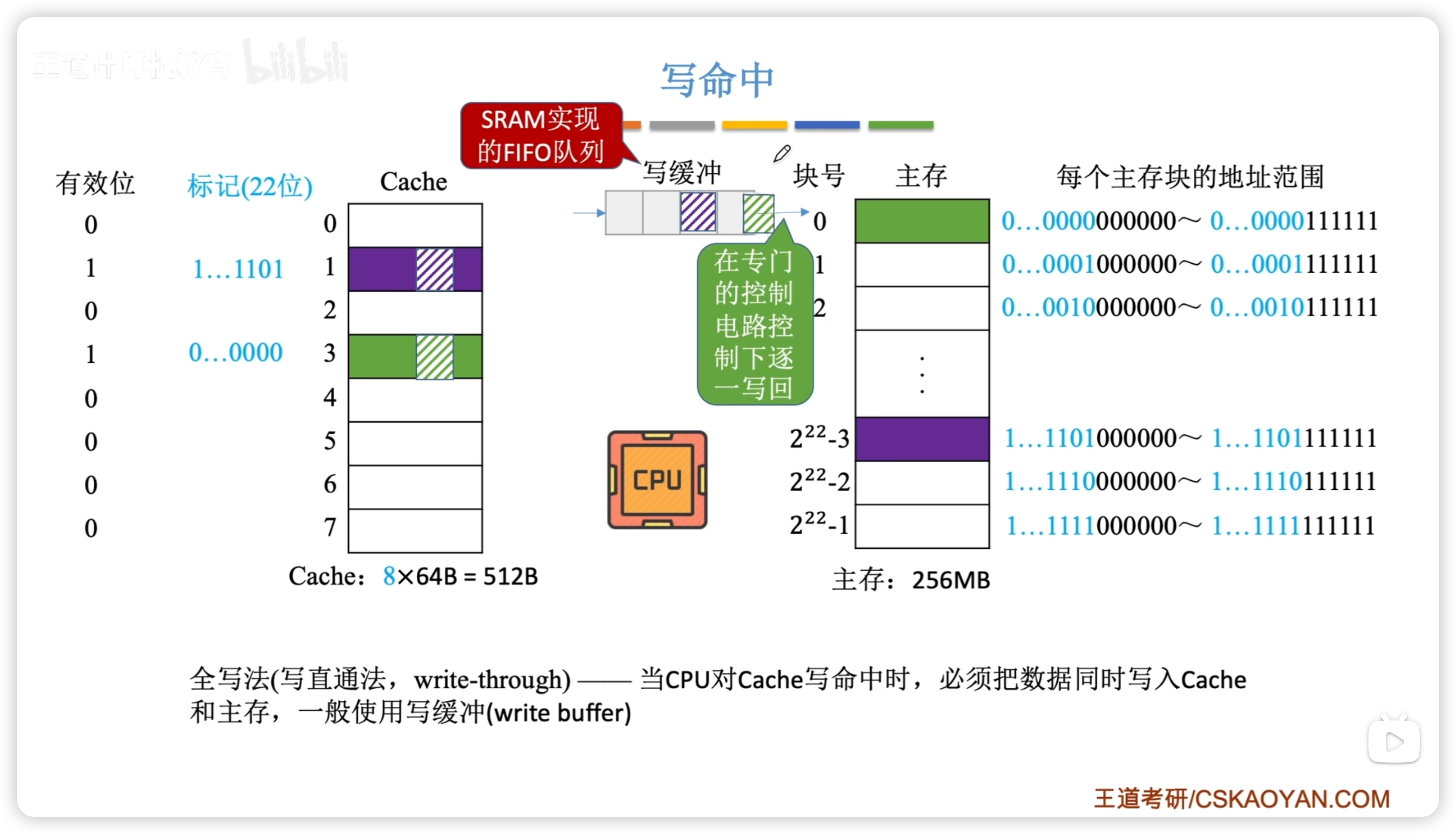
寫命中
- 寫回法
- write-back,適合訪問密集
- 當 CPU 對 Cache 寫命中時,只修改 Cache 的內容,而不立即寫入主存,只有當此塊被換出時才寫回主存
- 用髒位標記 Cache 塊是否被修改,修改過的才需要寫回
- 全寫法1. 寫直通法,write-through,適合安全性高2. 當CPU對Cache寫命中時,必須把數據同時寫入Cache和主存 1. 一般使用寫緩衝(write buffer)訪存次數增加,速度變慢,但更能保證數據一致性 1. 使用寫緩衝,CPU 寫的速度很快,若寫操作不頻繁,則效果很好。若寫操作很頻繁, 可能會因溈寫緩衝飽和而發生阻塞
寫未命中
- 寫分配法
- write-allocate
- 當CPU對Cache寫不命中時,把主存中的塊調入Cache, 在Cache中修改。
- 搭配寫回法使用
- 非寫分配法
- not-write-allocate
- 當CPU對Cache寫不命中時只寫入主存,不調入Cache。
- 搭配全寫法使用
3.5.5 其他
3.5.5.1 多級 Cache
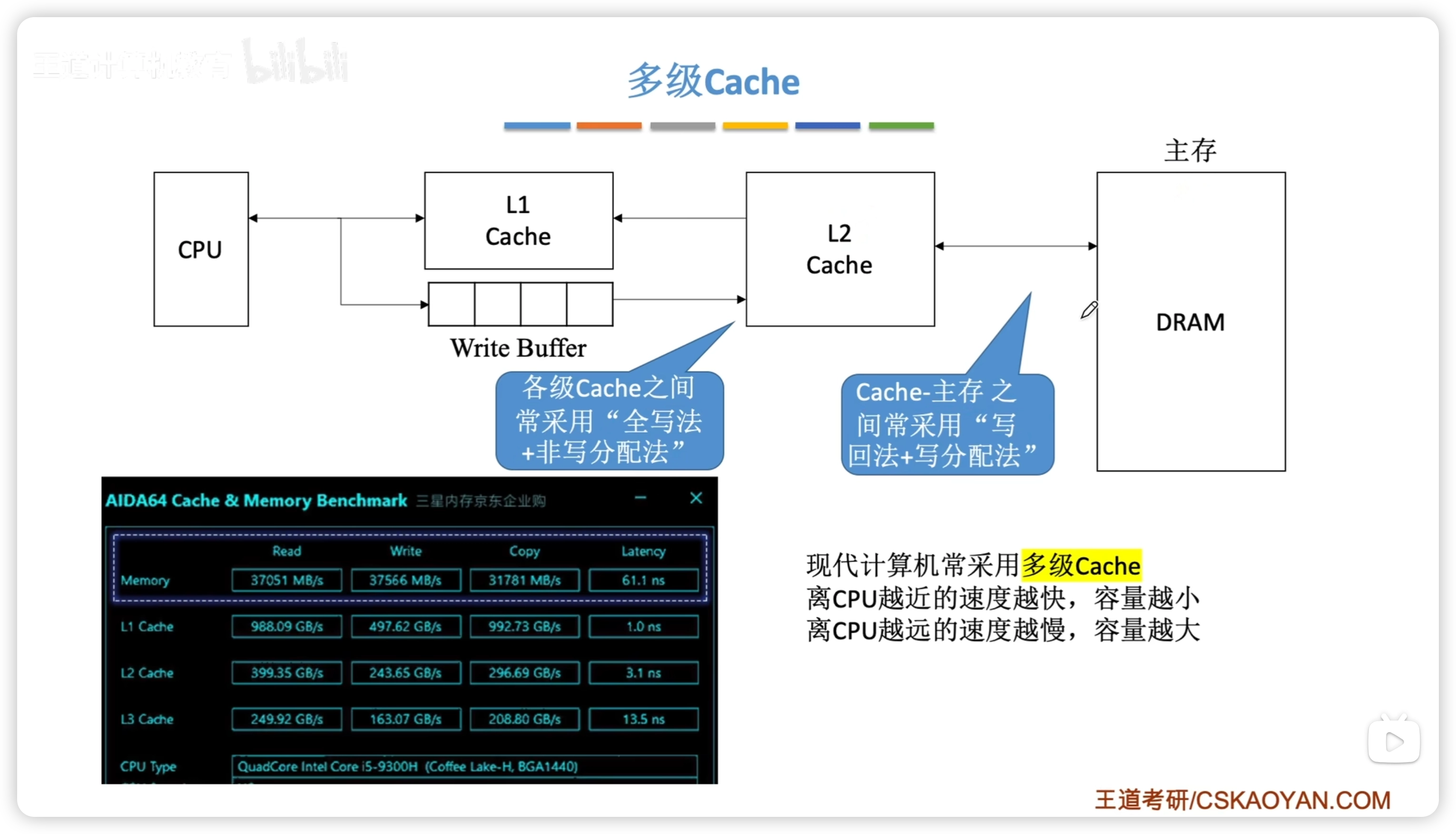
Cache 比較器
- 幾路組相聯需要幾個比較器
- 比較器位數 = 標記位位數
3.6 虛擬存儲器
- 主存和輔存的關係可類比 Cache 和主存
主存和輔存構成了虛擬存儲器,虛擬存儲器具有主存的速度和輔存的容量。
- 虛地址
- 邏輯地址
- 用戶編程允許涉及的地址
- 實地址
- 物理地址
- 對應主存地址空間
CPU 使用虛地址時,先判斷這個虛地址是否在主存中
- 已在主存中,則通過地址變換,直接訪問實際物理地址
- 不在主存中,則把包含這個地址的一頁/段調入主存,再訪問
- 主存已滿,則採用替換算法
對於虛擬存儲器,訪問輔存的代價很大,所以
- 採用寫回法,不用每次訪問輔存
- 採用全相聯映射
3.6.1 頁式虛擬存儲器
- 以頁為基本單位
- 主存空間的頁稱作物理頁、實頁
- 虛擬空間的頁稱作虛擬頁、虛頁
頁表實現了虛擬地址到物理地址的轉換。
快表 TLB
快表就是頁表的 Cache,存放經常訪問的頁。
4 指令系統
4.1 指令基礎
4.1.1 ISA
指令系統是指令集體系結構(ISA) 中最核心的部分。
ISA 規定的內容主要包括:
- 指令格式,指令尋址方式,操作類型,以及每種操作對應的操作數的相應規定
- 操作數的類型,操作數尋址方式,以及是按大端方式還是按小端方式存放
- 程序可訪問的通用寄存器編號、個數和位數,存儲空間的大小和編址方式
- 指令執行過程的控制方式等,包括程序計數器、條件碼定義等
4.1.2 指令基本格式
- 指令 = 操作碼 + 地址碼
- 指令一般是字節大小的整數倍!
指令系統主要有以下四種常見的分類。
按地址碼分類
零地址

一地址

二三地址

四地址

按指令長度分類
- 指令字長:一條指令的總長度(可能會變)
- 機器字長:CPU進行一次整數運算所能處理的二進制數據的位數(通常和ALU直接相關)
- 存儲字長:一個存儲單元中的二進制代碼位數(通常和MDR位數相同)
半字長指令、單字長指令、雙字長指令:指令長度是機器字長的多少倍。
指令字長會影響取指令所需時間。例如,如果機器字長=存儲字長=16bit,則取一條雙字長指令需要兩次訪存。
指令字結構:
- 定長指令字結構:指令系統中所有指令的長度都相等。
- 變長指令字結構:指令系統中各種指令的長度不等。
按操作碼長度分類
- 定長操作碼
- 指令系統中所有指令的操作碼長度都相同。
- 特點:n位 條指令。
- 優點:控制器的譯碼電路設計簡單。
- 缺點:靈活性較低。
- 可變長操作碼
- 指令系統中各指令的操作碼長度可變。
- 特點:不同指令的操作碼長度不同。
- 優點:靈活性較高。
- 缺點:控制器的譯碼電路設計複雜。
擴展操作碼指令格式
定長指令字結構 + 可變長操作碼 擴展操作碼指令格式
這種格式結合了定長和變長操作碼的優點,既保持了一定的靈活性,又簡化了譯碼電路的設計。
按操作類型分類
- 數據傳送類
- 進行主存與CPU之間的數據傳送
- LOAD:作用是把存儲器中的數據放到寄存器中。
- STORE:作用是把寄存器中的數據放到存儲器中。
- 進行主存與CPU之間的數據傳送
- 運算類
- 算術邏輯操作
- 算術運算:包括加、減、乘、除、增1、減1、求補、浮點運算等
- 邏輯運算:包括與、或、非、異或、位操作、位測試、位清除、位求反等
- 移位操作
- 包括算術移位、邏輯移位、循環移位(帶進位和不帶進位)。
- 算術邏輯操作
- 程序控制類
- 轉移操作,改變程序執行的順序
- 無條件轉移:JMP
- 條件轉移:
- JZ:結果為0時轉移
- JO:結果溢出時轉移
- JC:結果有進位時轉移
- 調用和返回:CALL和RETURN
- 循環
- 陷阱(Trap)與陷阱指令
- 轉移操作,改變程序執行的順序
- 輸入輸出類(I/O)
- 輸入輸出操作:進行CPU和I/O設備之間的數據傳送
- CPU寄存器與IO端口之間的數據傳送(端口即IO接口中的寄存器)。
- 輸入輸出操作:進行CPU和I/O設備之間的數據傳送
4.1.3 擴展操作碼
- 不允許短碼是長碼的前綴
- 設計思路:從地址碼最多的開始分配
e.g. 15 15 15 16
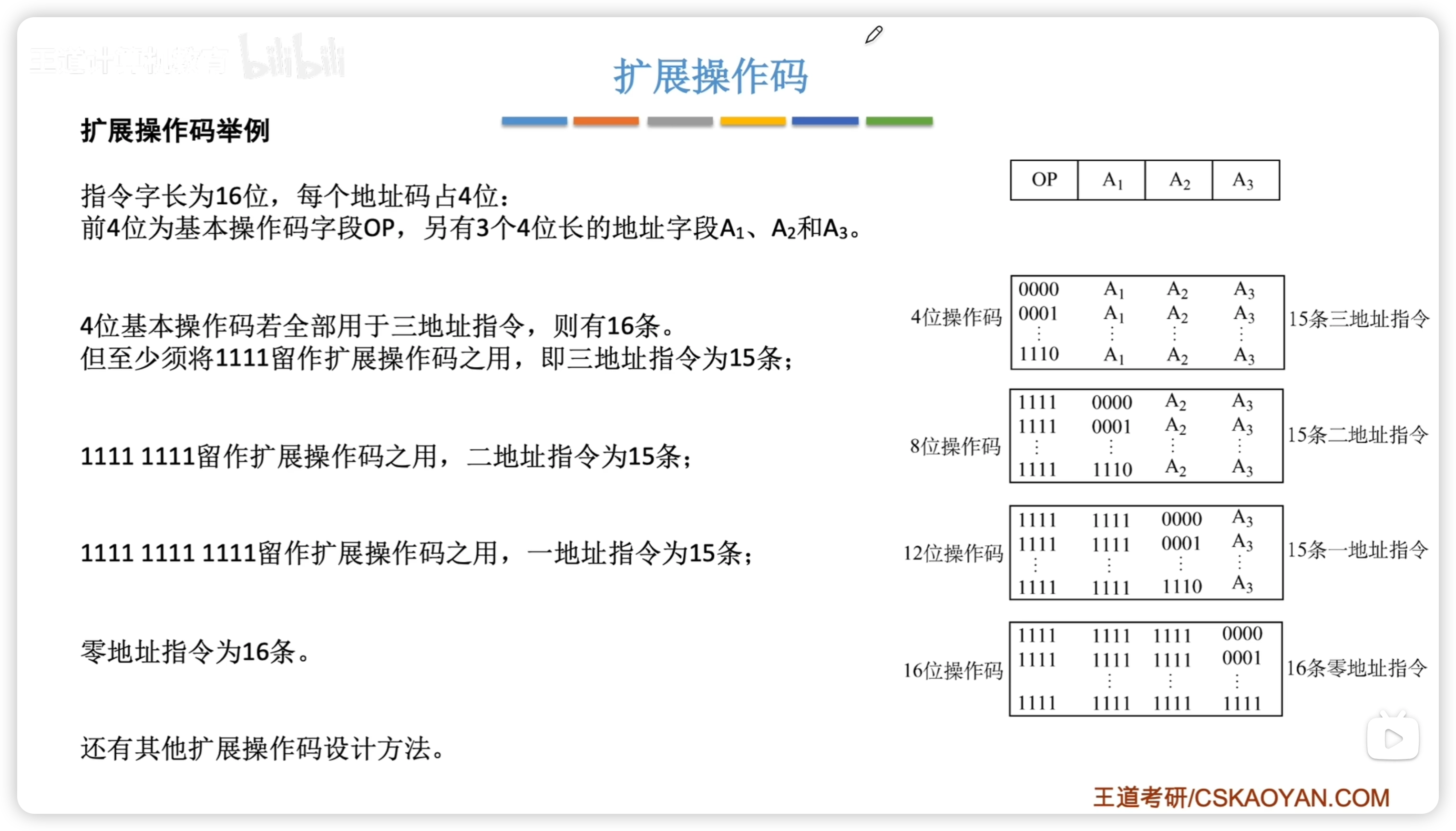
e.g. 15 12 62 32


4.2 尋址方式
尋址分為兩大類:
- 指令尋址:找下一條指令
- 數據尋址:找本條指令的數據
4.2.1 指令尋址
4.2.1.1 PC
程序計數器 PC 指明下一條要執行的指令的存放地址
- PC 是當程序執行完一步,自動執行下一句指令的物理硬件
- PC + 1 發生在取指令後
PC 在 x86中也叫作 IP(Instruction Pointer)
位數計算:
- 若機器按字尋址,PC 給出下一條指令字的訪存地址 (指令在內存中的地址),因此 PC 的位數取決於存儲器的字數
- 若存儲器有 個字,則 PC 至少要 16 位。
- 若機器按字尋址,指令寄存器 IR 用於接收取得的指令,因此 IR 的位數取決於指令字長
順序 跳躍
指令尋址主要有以下兩種情況:
- 順序尋址
- 通過程序計數器 PC + 1,自動形成下一條指令的地址
- “1” 理解為指令字長,實際加的值會因指令長度、編址方式而不同
- 比如變長指令,需要先讀取操作碼,判斷指令長度,得到“1”是多少
- 現代計算機通常是按字節編址,若指令字長 16 位,(PC) + 2
- 通過程序計數器 PC + 1,自動形成下一條指令的地址
- 跳躍尋址
- 通過轉移類指令(如相對尋址)實現,可用來實現程序的條件或無條件轉移
- 跳躍:
- 指下條指令的地址不由 PC 自動給出,而由本條指令給出下條指令地址的計算方式
- 跳躍:
- 跳躍分為:
- 絕對轉移,地址碼直接指出轉移目標地址
- 相對轉移,地址碼指出轉移目的地址相對於當前 PC 值的偏移量
- 跳躍的結果是當前指令修改 PC 值,下一條指令仍然通過 PC 給出,CPU 總是根據 PC 的內容去主存取指令
- 通過轉移類指令(如相對尋址)實現,可用來實現程序的條件或無條件轉移
4.2.2 數據尋址
確定本條指令的地址碼指明的真實地址
- 表示的是操作數的地址
地址碼的組成
地址碼按照不同的解讀方式,分為 10 種,每種有不同的尋址特徵。
- 下圖是一地址指令,多地址同理
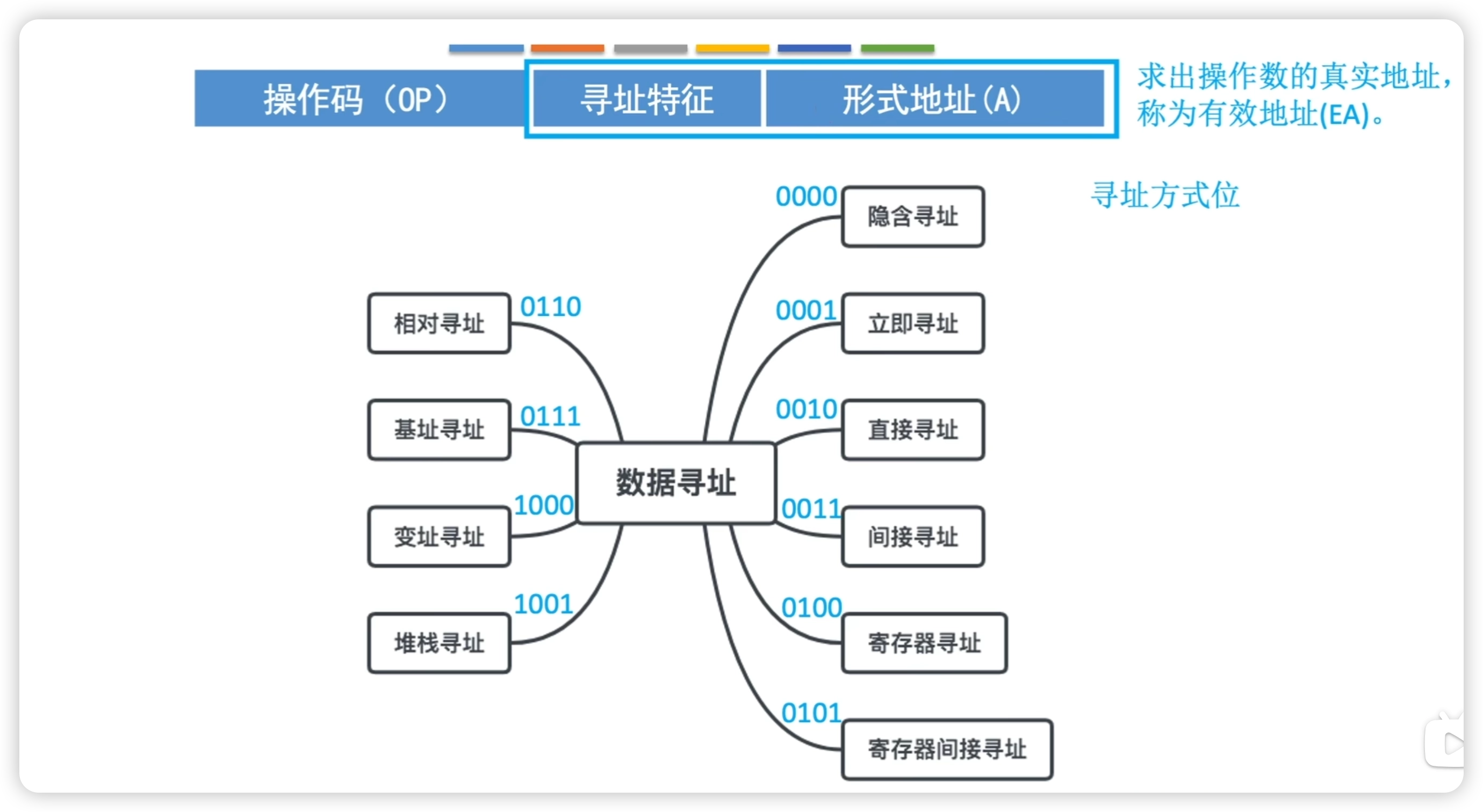
地址碼 = 尋址特徵 + 形式地址
- 尋址特徵:指明屬於那種尋址方式(其位數決定了尋址方式的種類)
- 形式地址 A:不代表操作數的真實地址,需要根據尋址特徵的要求轉換為對應存儲器的地址
- 有效地址 EA:通過尋址特徵和形式地址計算出操作數在存儲器中的真實地址
A 既可以是寄存器編號,又可以是內存地址;(A) 表示地址為 A 的單元的內容
直接尋址
形式地址
A = 真实地址有效地址
EA = A優點:簡單,不需要計算操作數的地址,指令在執行階段僅需訪存 1 次
缺點:A 的位數限制了該指令操作數的尋址範圍,操作數的地址不易修改
間接尋址
- 形式地址
A = 操作数有效地址所在的主存单元的地址 - 有效地址
EA = (A) - 尋址過程:去該主存單元取操作數的地址,再去找操作數

是否是多次間接尋址看操作數的內容第一位是否是1
注意,這是區分間接尋址和多次間接尋址的方式;而寄存器尋址和寄存器間接尋址是直接通過尋址特徵區分的。
優點:可擴大尋址範圍,便於編制程序(方便完成子程序的返回)
缺點:指令在執行階段要多次訪存(1 次間址 2 次訪存),執行速度較慢
寄存器尋址
形式地址
A = 操作数所在寄存器的编号有效地址 EA =
尋址過程:訪問該寄存器,取出操作數

優點:
- 指令在執行階段不用訪存,只訪問寄存器,執行速度快
- 指令字長較短
- 因為寄存器數量遠小於內存單元數,地址碼位數較少
缺點:
- 寄存器價格昂貴
- CPU 的寄存器數量有限
寄存器間接尋址
形式地址
A = 操作数所在的寄存器的地址有效地址:EA =
尋址過程:根據該地址去寄存器中找到操作數的有效地址

優點:相比間接尋址,既擴大了尋址範圍,又減少了訪存次數(執行階段僅訪存 1 次)
缺點:相比寄存器訪存,執行階段需要訪存(操作數在主存中)
隱含尋址
不直接給出操作數的地址,而是在指令中就隱含操作數的地址。
- 有效地址:程序指定
- 尋址過程:
- 形式地址 A 取出對應的一個操作數
- 另一個操作數通過隱含尋址方式的指令設置,隱含在 ACC 中

- 優點:有利於縮短指令字長
- 缺點:需增加存儲操作數或隱含地址的硬件
立即尋址
- 與直接尋址區分
操作數本身直接存放在形式地址中
- 有效地址: A 就是操作數,也稱立即數
- 尋址過程:
- 尋址特徵為
#,代表立即尋址的意思 - 形式地址寫的是操作數 3 的補碼(011)
- 尋址特徵為

- 優點:不訪存,指令執行速度最快
- 缺點:A 的位數限制了立即數的範圍
基址尋址
- 以下三種都是偏移尋址:基址、變址、相對
- 三者的形式地址 A 都表示偏移量
- 三者的區別在於偏移的起點(基地址)
基地址是基址寄存器(Base address Register)的內容
- 有效地址
EA = (BR) + A - 尋址過程:程序運行前,CPU 將 BR 的值修改為程序的起始地址(存放在操作系統 PCB 中 )

- 基址寄存器:
- OS中的重定位寄存器 = 基址寄存器
- 基址寄存器可以是一個專用寄存器,也可以是指定的某個通用寄存器
- 面向操作系統,內容由操作系統或管理程序確定,用於解決程序邏輯空間與存儲器物理空間的無關性
- 程序執行過程中,基址寄存器內容不變(作為基地址),形式地址可變(作為偏移量)
- 採用通用寄存器時,可由用戶決定哪個寄存器,但其內容仍由操作系統確定
- 需要額外佔用若干bit指明需要哪個通用寄存器
- 優點:
- 可以擴大尋址範圍(基址寄存器的位數大於 A 的位數)
- 用戶不用操心程序的內存位置,只管寫程序即可
- 有利於多道程序設計
- 多道程序設計:在一臺計算機的內存中,同時裝入多道程序(多個作業)
- 可用於編制浮動程序
- 有利於多道程序設計
- 缺點:偏移量(A)的位數較短
變址尋址
與基址類似,區別是:
- 變址寄存器的內容可以被用戶修改
- 形式地址作為基地址,而變址寄存器的內容作為偏移量
有效地址
EA = A + (IX)優點:
- 可以擴大尋址範圍
- 變址寄存器的位數大於 A 的位數
- 適合循環程序
- 在數組處理過程中,可設定 A 為數組的首地址,不斷改變 IX 的內容,便可很容易形成數組中任意一個數據的地址
- 偏移量的位數足以表示整個存儲空間
- 可以擴大尋址範圍
基址 + 變址 的複合尋址:
- 先基址尋址:
EA = (BR) + A - 再變址尋址:
EA = A + (IX) - 最終有效地址:
EA = ((BR) + A) + (IX)
相對尋址
基地址是 PC 的內容
- 有效地址:EA = (PC) + A
- A 可正可負,補碼錶示
- A 的位數決定操作數的尋址範圍

- 優點:
- 操作數的地址不是固定的,隨 PC 值的變化而變化,與指令地址之間總是相差一個固定的偏移量,因此便於程序浮動
- e.g. 一段for循環代碼移動位置

- e.g. 一段for循環代碼移動位置
- 廣泛應用於轉移指令
- 操作數的地址不是固定的,隨 PC 值的變化而變化,與指令地址之間總是相差一個固定的偏移量,因此便於程序浮動
堆棧尋址
操作數存放在堆棧中,隱含使用堆棧指針 SP 作為操作數地址
- SP:Stack Pointer 是一個寄存器
e.g. 一次加法操作的堆棧尋址

- 有效地址:99入棧 / 出棧時 EA 的確定方式不同
- 堆棧:
- 後進先出的一塊存儲區
- 該存儲區中被讀 / 寫單元的地址是用堆棧指針 SP 給出
- 硬件自動完成 SP 的加減操作

- 硬堆棧:寄存器堆棧,成本較高,不需要訪存,不適合做大容量堆棧
- 軟堆棧:從主存中劃出一段區域,執行階段訪存 1 次,通常採用軟堆棧
總結
- 速度方面:立即尋址 > 寄存器尋址 > 直接尋址 > 寄存器間接尋址 > 間接尋址

注意,以上的訪存次數是指指令執行期間,不包括取指令。
4.2.3 補充:硬件的比較跳轉

4.3 機器代碼
- 彙編基礎:第二章 寄存器
寄存器:

4.3.1 數據傳送類
MOV dst, src:傳送數據(寄存器/內存/立即數之間)PUSH src:把操作數壓棧(SP/ESP 減小,內容寫入棧頂)POP dst:把棧頂彈出到寄存器/內存(SP/ESP 增大)XCHG dst, src:交換兩個操作數的值LEA reg, mem:取內存操作數的有效地址加載到寄存器(常用來計算地址偏移)
4.3.2 算術運算類
ADD dst, src:加法SUB dst, src:減法INC dst:加 1increaseDEC dst:減 1decreaseMUL src:無符號乘法(默認和 AX/EAX 相乘)IMUL src:有符號乘法
DIV src:無符號除法(默認被除數在 AX 或 DX:AX 中)IDIV src:有符號除法- EDX = EAX / src,商存入 EAX,餘數存入 EDX
NEG dst:取負數CMP dst, src:比較(本質是SUB,結果不保存,只改標誌位)
4.3.3 邏輯運算類
AND dst, src:按位與OR dst, src:按位或XOR dst, src:按位異或- Exclusive OR
NOT dst:按位取反TEST dst, src:按位與,隻影響標誌位,不保存結果
4.3.4 移位/循環移位類
SHL dst, n:邏輯左移- Shift Left
- 將 dst 左移 n 位,放回 dst
SHR dst, n:邏輯右移(高位補 0)SAL dst, n:算術左移SAR dst, n:算術右移(高位補符號位)ROL dst, n:循環左移ROR dst, n:循環右移RCL dst, n:帶進位循環左移RCR dst, n:帶進位循環右移
4.3.5 轉移控制類
4.3.5.1 無條件轉移
JMP label:無條件跳轉
條件轉移(重點)
根據 標誌寄存器(ZF, CF, SF, OF 等) 跳轉:
JE/JZ label:等於 / 為零時跳轉JNE/JNZ label:不等於 / 非零時跳轉JC:進位時跳轉JNC:無進位時跳轉JS:負數(符號位=1)時跳轉JNS:非負時跳轉JG/JNLE:大於(有符號)- Jump when Greater than
JGE:大於等於- Jump when Greater than or Equal to
JL/JNGE:小於(有符號)JLE:小於等於- Jump when Less than or Equal to
JA:大於(無符號)JB:小於(無符號)
e.g. 一個 if 判斷

e.g. 循環

LOOP:等價於 自減 + 比較 + 跳轉- 指定 ECX 作為

4.3.6 子程序調用與返回
CALL label:調用子程序(把返回地址壓棧,然後跳轉)RET:從子程序返回(把返回地址彈棧,跳回調用點)INT n:軟中斷IRET:中斷返回
當前函數的棧幀位於棧頂:
- 棧頂是低地址,棧從高往低增長
- x86 系統中,默認以4字節為棧的操作單位

call ret 具體過程:
- call
- 把 IP(原函數下一條指令位置)壓棧
- 設置新 IP
- 顯式:這一步可以用 ENTER 命令替代
- push 原函數的 EBP
- 設置新函數棧底
- leave
- 效果是讓 EBP 和 ESP 指向上一層函數的棧底和頂

- 效果是讓 EBP 和 ESP 指向上一層函數的棧底和頂
- ret 1. 把 IP 舊值出棧

4.3.7 棧幀內部詳解

區域內部實現從低往高增長:
- 局部變量區:越先定義的變量,越靠近棧頂,自頂向底是從低往高
- 調用參數區:越靠前的參數,越靠近棧頂
e.g. 彙編代碼過程

4.3.8 其他
- 非重點
- 字符串處理
MOVS:內存塊傳送LODS:裝載字符串元素STOS:存儲字符串元素SCAS:掃描字符串CMPS:比較字符串
- 標誌寄存器相關
CLC:清進位標誌 CF=0STC:置進位標誌 CF=1CLD:清方向標誌(DF=0,字符串操作自增)STD:置方向標誌(DF=1,字符串操作自減)
4.3.9 補充 AT&T 格式
- 一般不考

4.4 CISC 和 RISC
4.4.1 複雜指令系統計算機(CISC)
- Complex Instruction Set Computer
- 設計思路:一條指令完成一個複雜的基本功能
- 代表:x86 架構,主要用於筆記本、臺式機等
- 指令系統:複雜龐大
- 指令數目:一般大於 200 條
- 指令字長:不固定,指令格式多,尋址方式多
- 可訪存指令:不加限制
- 各種指令執行時間:相差較大,大多數指令需要多個時鐘週期才能完成
- 各種指令使用頻度:相差很大
- 通用寄存器數量:較少
- 目標代碼:難以用優化編譯生成高效的目標代碼程序
- 控制方式:絕大多數為微程序控制
- 指令流水線:可通過一定方式實現
- 兼容性:可兼容很多不同的高級語言和軟件
4.4.2 精簡指令系統計算機(RISC)
- Reduced Instruction Set Computer
- 設計思路:一條指令完成一個基本“動作”,多條指令組合完成一個複雜的基本功能
- 代表:
- ARM 架構,手機、平板等
- MIPS 架構,五段式流水線
- 指令系統:簡單精簡
- 指令數目:一般小於 100 條
- 指令字長:定長,指令種類少,尋址方式種類少
- 可訪存指令:只有 Load / Store 指令
- 各種指令執行時間:絕大多數在一個週期內完成
- 各種指令使用頻度:都比較常用
- 通用寄存器數量:多
- 目標代碼:採用優化的編譯程序,生成代碼較為高效
- 控制方式:絕大多數為組合邏輯控制,硬佈線
- 指令流水線:必須實現
- 兼容性:較差
和 CISC 相比,RISC 的優點體現在:
- RISC 更能充分利用 VLSI(超大規模集成電路)芯片的面積
- RISC 更能提高運算速度
- RISC 便於設計,可降低成本,提高可靠性
- RISC 有利於編譯程序代碼優化
5 中央處理器 CPU
5.1 CPU概述
5.1.1 CPU 的功能
- 指令控制:
- 完成取指令、分析指令和執行指令的操作,即程序的順序控制
- 操作控制:
- 管理併產生由內存取出的每條指令的操作信號
- 把各種操作信號送往相應的部件,從而控制這些部件按指令的要求進行動作
- 時間控制:
- 嚴格控制各種操作信號的出現時間、持續時間及出現的時間順序
- 數據加工:
- 對數據進行算術和邏輯運算
- 中斷處理:
- 對計算機運行過程中出現的異常情況和特殊請求進行處理
5.1.2 CPU 的基本結構
CPU = 运算器 + 控制器- 運算器:對數據進行加工
- 控制器:負責協調並控制計算機各部件執行程序的指令
- 又可以細分為
ALU + CU + 寄存器 + 中断系统
CPU = 数据通路 + 控制部件

- 結合後面幾個小節理解
5.1.3 CPU 寄存器
- 2010真題
按彙編語言(或機器語言)程序是否可以訪問分類。
用戶可見的寄存器:
- 可對這類寄存器編程
- 使用這類寄存器可減少對主存儲器的訪問次數
- 通用寄存器(含基址 / 變址)、程序狀態字寄存器PSW、狀態 / 標誌寄存器、程序計數器PC、累加寄存器ACC
用戶不可見的寄存器:
- 對用戶透明(透明是指不可見),不可編程
- 被控制部件使用,以控制 CPU 的操作
- 存儲器地址寄存器MAR、存儲器數據寄存器MDR、指令寄存器IR、暫存寄存器、移位寄存器
5.1.4 運算器
運算器是計算機對數據進行加工處理的中心,接收從控制器送來的命令並執行相應的動作,對數據進行加工和處理。
運算器組成
- 算術邏輯單元(ALU)
- 進行算術 / 邏輯運算
- 通用寄存器組(GPRS)
- 如 AX,BX,CX,DX,SP
- 用於存放操作數和各種地址信息,所以其位數與機器字長相等
- SP 是堆棧指針,用於指示棧頂的地址
- 暫存寄存器
- 暫存從數據總線或通用寄存器讀來的操作數

- 對應用程序員透明
- 暫存從數據總線或通用寄存器讀來的操作數
- 累加寄存器(ACC)
- 是一個通用寄存器
- 暫放 ALU 運算的結果信息,可作為加法運算的輸入端
- 程序狀態字寄存器(PSW)
- PSW 存放程序狀態字(標誌位的組合),用於保存系統的運行狀態
- PSW 包括狀態標誌和控制標誌
- 溢出標誌 OF,符號標誌 SF,零標誌 ZF,進位標誌 CF
- 中斷標誌,陷阱標誌
- 移位寄存器(SR)
- 對操作數或運算結果進行移位運算
- 計數器
- 控制乘除運算的操作步數
5.1.5 控制器
控制器負責協調並控制計算機各部件工作。
控制器的基本功能:
- 取指令
- 分析指令
- 操作碼譯碼(分析本條指令要完成什麼操作),產生操作數的有效地址
- 執行指令
- 根據分析指令得到的“操作命令”和“操作數地址”,形成操作信號控制序列
- 中斷處理
- 管理總線及輸入輸出;處理異常情況(如掉電)和特殊請求(如打印機請求打印一行字符)
控制器組成
- 程序計數器(PC)
- 用於指出下一條指令在主存中的存放地址(PC 總是存放指令地址)
- PC 有自增功能
- 機器指令中不能顯式地使用PC
- PC 的值會根據 CPU 在執行指令過程中自增或轉移到程序的某處 (跳轉指令)
PC 的位数 = 主存储器(按照指令编址)的地址位数,因為 PC 就是存地址的- 注意,不一定按字節編址,地址就是取字節地址;如果指令按字邊界對齊,則指令取字地址,這樣位數更短,2016真題。
- 指令寄存器(IR)
- 用於保存當前正在執行的那條指令
IR 的位数 = 指令字长(大於等於)
- 指令譯碼器(ID)
- 僅對操作碼字段進行譯碼,以確定指令的操作功能
- 存儲器地址寄存器(MAR)
- 存放要訪問的主存儲器單元的地址
MAR 的位数 = 主存储器地址线位数
- 存儲器數據寄存器(MDR)
- 存放向主存儲器寫入的信息或從主存儲器讀出的信息
MDR 的位数 = 存储字长
- 微操作信號發生器
- 根據 IR 的內容 (指令),PSW 的內容 (狀態信息) 和時序信號產生控制計算機系統所需的各種控制信號
- 有組合邏輯型和存儲邏輯型
- 2022真題:控制信號由什麼部件產生?答:CU
- CU是更籠統的一個概念
- 時序系統
- 用於產生各種時序信號,都由統一時鐘 CLOCK 分頻得到
5.1.6 數據通路概述
- 詳見後文
專用數據通路方式
根據指令執行過程中的數據和地址的流動方向安排連線線路
- 使用多路選擇器控制一路的輸出
- 使用三態門控制輸出
- 優點:性能較高,基本不存在數據衝突現象
- 缺點:結構複雜,硬件量大,不易實現
CPU 內部單總線方式
將所有寄存器的輸入端和控制端都連接到一條公共通路
- 優點:結構簡單,容易實現
- 缺點:
- 傳輸存在較多衝突現象,性能較低
- 需要暫存寄存器
5.2 指令執行
5.2.1 指令週期
指令週期 = 取指週期 + 執行週期

週期概念辨析
幾個週期的關係:
- 若干 CPU 時鐘週期 / 節拍 / CLK / T週期 組成 一個機器週期
- 若干機器週期 組成 一個指令週期

常見指令的指令週期:

- 可能額外含有間址和中斷
指令週期流程

- 用觸發器區分是哪個週期
- FE Fetch、IND Indirect、EX Execute、INT Interrupt
- 四種週期都有訪存操作
5.2.2 指令週期的數據流
數據流:根據指令要求一次訪問的數據序列
- 指令執行不同階段,訪問的數據序列不同
- 不同的指令,數據流也不同
取指週期
根據 PC 中的內容從主存中取出指令代碼並放在 IR 中
數據流向:
- PC to MAR( to 地址總線 to 主存)
- MAR 送到 主存是MAR寄存器的固有功能,一旦地址存入MAR,其輸出便持續有效並連接到地址總線上,通常不需要一個獨立的“MARout”控制信號
- CU 發出讀命令 to 控制總線 to 主存
- 主存 to 數據總線 MDR to IR
- CU 發出控制信號 to PC + 1

間址週期
取操作數的有效地址
以一次間址為例,將指令中的地址碼送到 MAR 並送至地址總線,此後 CU 向存儲器發出讀命令,以獲取有效地址並存至 MDR。
數據流向:
- Ad(IR / MDR) to MAR to 地址總線 to 主存
- IR、MDR都有地址碼,考試寫 IR
- CU 發出讀命令 to 控制總線 to 內存
- 用形式地址去讀有效地址
- 主存 to 數據總線 to MDR
- 成功讀出有效地址,並存放在MDR
- 有效地址 to 指令的地址碼字段

執行週期
取操作數,並根據 IR 中的指令字的操作碼通過 ALU 操作產出執行結果
數據流向:不同指令操作不同,無統一的數據流向
中斷週期
處理中斷請求
假設程序斷點存入堆棧中,並用 SP 指示棧頂指針,而且進棧操作是先修改指針,後存入數據;出棧操作是先刪除數據,後修改指針。
數據流向:
- CU 控制 SP - 1,修改後的 SP to MAR to 地址總線 to 主存
- 進棧需要先修改棧頂指針
- CU 發出寫命令 to 控制總線 to 主存
- PC to MDR to 數據總線 to 主存
- 保存斷點(PC)到棧頂(SP)
- CU 修改 PC 為中斷服務程序的入口

5.2.3 指令的執行方案
5.2.3.1 單週期處理器
每條指令都在一個時鐘週期內完成,CPI = 1。
指令週期取決於執行時間最長的指令的執行時間。
特點:
- 串行,相同執行時間
- 部件冗餘大,時間利用率低
- 指令執行時,控制信號不變
- 單總線結構一個時鐘只能完成一個操作,故不可以用單總線結構
多週期處理器
每條指令在多個時鐘週期完成,每條的週期數可以不同,但是一定大於1(CPI > 1)。
- 特點:串行,不同執行時間
- 注意,多週期和單週期的時鐘週期的長度可能不同
流水線處理器
在每一個時鐘週期啟動一條指令,儘量讓多條指令同時運行,但各自處在不同的執行步驟中。
儘量讓多條指令同時運行,但各自處在不同的執行步驟中。
- 特點:並行
5.3 數據通路
總線概念辨析:
- 內部總線
- CPU內部連接CPU的各個核心部件
- 系統總線
- CPU與計算機其他主要部件(如內存、I/O設備)之間的數據傳輸
數據通路的兩類元件:
- 操作元件
- 組合邏輯元件
- ALU、MUX、譯碼器、加法器、三態門等
- 狀態元件
- 時序邏輯元件
- 各類寄存器、存儲器,包括通用寄存器組、PC、狀態/移位/暫存/鎖存寄存器
5.3.1 數據通路的基本結構
5.3.1.1 單總線結構
- CPU 內部單總線
將所用寄存器的輸入端與輸出端連接到一條公共通路上
- 結構比較簡單
- 同一時間只能有一個輸出,可以有多個輸入(兩個部件之間交換)
- 數據傳輸存在較多的衝突現象,性能較低
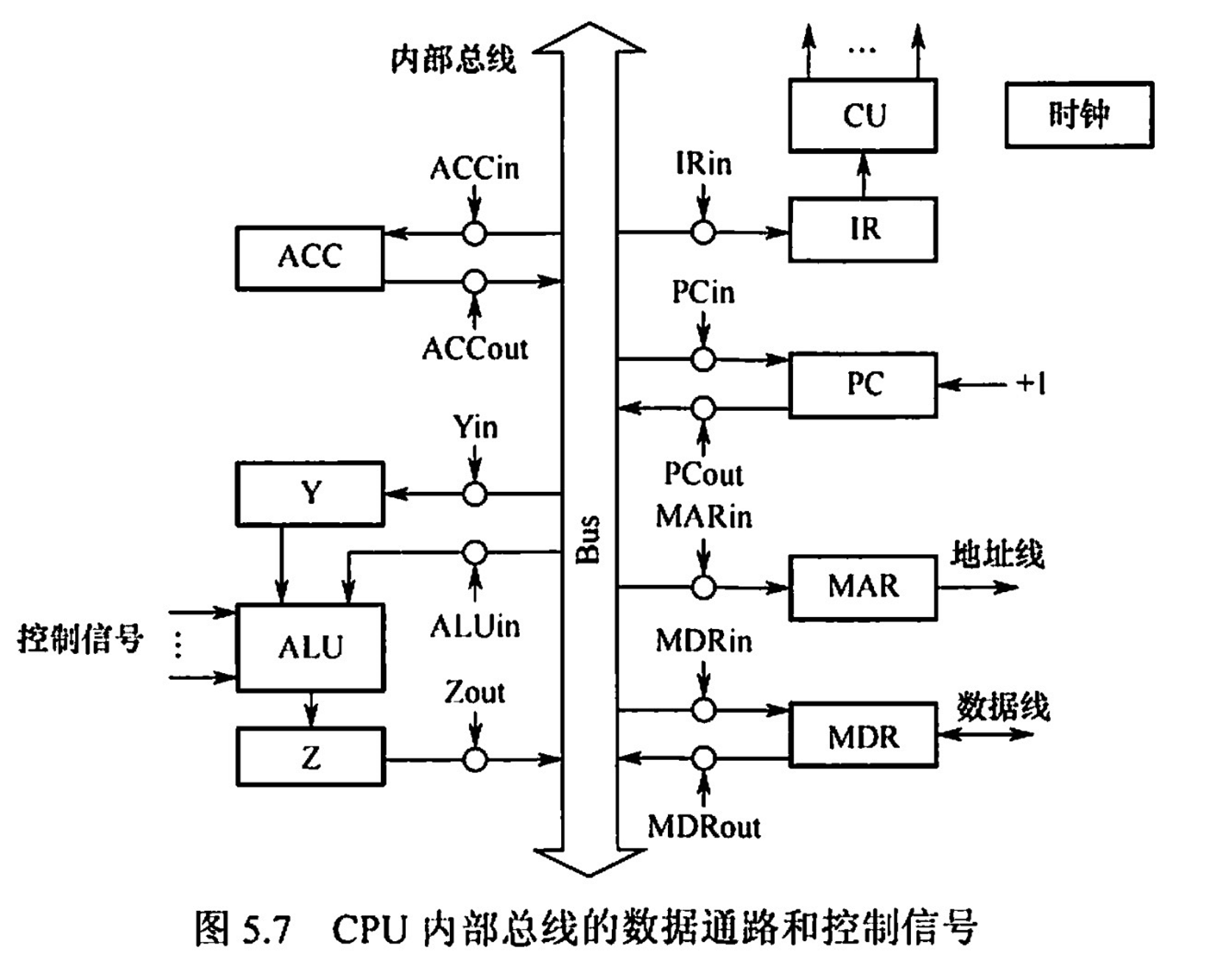
- in 表示該部件的允許輸入控制信號;out 表示該部件的允許輸出控制信號
- ALU 只能有一個輸入端與總線相連,另一個輸入端需要通過暫存器與總線相連
多總線結構
- CPU 內部多總線方式
將所用寄存器的輸入端與輸出端都連接到多條公共通路上
- 相較單總線結構,效率較高
專用數據通路
根據指令執行過程中的數據和地址的流動方向安排連接線路
- 避免使用共享的總線,性能較好,但硬件總量較大
5.3.2 單總線
以 CPU 內部單總線數據通路為例,注意每次總線傳送時哪些信號有效。
寄存器之間數據傳送
- e.g. 把 PC 內容送至 MAR,實現傳送操作的流程及控制信號為:
- (PC) -> Bus
- PCout 有效,PC 內容送至總線
- Bus -> MAR
- MARin 有效,總線內容送 MAR
- (PC) -> Bus
- e.g. 把 PC 內容送至 MAR,實現傳送操作的流程及控制信號為:
主存與 CPU 之間的數據傳送
- e.g. CPU 從主存讀取指令,實現傳送操作的流程及控制信號為:
- (PC) -> Bus -> MAR
- PCout 和 MARin 有效,現行指令地址 -> MAR
- 1 -> R
- CU 發讀命令
- “1”: 代表一個控制信號,高電平
- “R”: Read
- CU 發讀命令
- MEM (MAR) -> MDR
- MDRin 有效
- MDR -> Bus -> IR
- MDRout 和 IRin 有效,現行指令 -> IR
- (PC) -> Bus -> MAR
- e.g. CPU 從主存讀取指令,實現傳送操作的流程及控制信號為:

- 執行算術或邏輯運算
- 比如一條加法指令,微指令序列及控制信號為:
- Ad (IR) -> Bus -> MAR
- MDRout 和 Yin 有效
- 從 IR 和 MDR 都可以取到地址,因為指令是從 MDR 複製到 IR 的
- 1 -> R
- CU 發讀命令
- MEM (MAR) -> 數據線 -> MDR
- MDRin 有效
- MDR -> Bus -> Y
- MDRout 和 Yin 有效,操作數 -> Y
- (ACC) + (Y) -> Z
- ACCout 和 ALUin 有效,CU 向 ALU 發送加命令
- Z -> ACC
- Zout 和 ACCin 有效,結果 -> ACC
- Ad (IR) -> Bus -> MAR
- 比如一條加法指令,微指令序列及控制信號為:
單總線分析題
- 先分析指令功能和指令週期
- 寫各個週期的操作和信號
取指週期:

間址週期:

執行週期:

考試需要根據題目圖的實際情況來寫信號,圖上沒給的信號不要寫!
e.g. 2022真題

比如本題未給出系統總線的 MDRin,故READ時,答案沒有寫 MDRin 信號
5.3.3 專用數據通路


存:
(ACC) -> MDR
(MDR) -> M(MAR)

5.4 控制器
CU發出一個微命令,可完成對應微操作。
e.g.
- 微命令 a:使 PCout、MARin 有效
- 完成對應的微操作 a:(PC)to MAR

注意:
- 一個節拍內可以並行完成多個“相容的”微操作
- 同一個微操作可能在不同指令的不同階段被使用
- 不同指令的執行週期所需節拍數各不相同
- 為了簡化設計,選擇定長的機器週期,以可能出現的最大節拍數為準(通常以訪存所需節拍數作參考)
- 若實際所需節拍數較少,可將微操作安排在機器週期末尾幾個節拍上進行
- 見上圖的執行、中斷週期
5.4.1 硬佈線控制器
- 基本不考
根據 指令操作碼、目前的機器週期、節拍信號、機器狀態條件,即可確定現在這個節拍下應該發出哪些“微命令”。

比如,對於所有指令的取指週期,在 T0 節拍下一定要完成 (PC) to MAR。則可知邏輯表達式為 ,而 就是一組微命令的代表。
硬佈線控制器的特點:
- 由於純硬件實現、設計複雜,因此一般用於指令較少的 RISC(精簡指令集系統)
- 如果擴充一條新的指令,則控制器的設計就需要大改,因此擴充指令較困難
- 由於使用純硬件實現控制,因此執行速度很快。微操作控制信號由組合邏輯電路即時產生
5.4.2 微程序控制器
- 難點,但是非重點
- 引入了軟件的思想
概念辨析
程序:由指令(序列)組成
- 指令:對程序執行步驟的描述
同時,每一種(機器)指令對應一個微程序。
- 注意,這個說法是正確的,後文會有關於微程序段的概念,勿混淆
微程序:由微指令(序列)組成
- 微指令:對指令執行步驟的描述
- 微指令就是類比指令構建的

補充微程序段:
- 通常,一條機器指令對應一個微程序。
- 但是,由於任何機器指令的取指令操作都是相同的,因此可將取指週期的微命令統一編成一個微程序段,作為公用,這個微程序段只負責將指令從主存單元中取出並送至指令寄存器。
- 所以會有題目說:如果某指令系統中有 條機器指令,則 CM 有微程序段的個數至少是 個
- 此外,也可編出對應間址週期的微程序段和中斷週期的微程序段。
微指令、微命令、微操作
- 微命令:微程序控制器中控制部件發出的控制信號
- 微命令和微操作一一對應
- 一個微指令中可能包含多個微命令/微操作
微程序控制器的結構

- 控制存儲器由 ROM 組成
微程序控制單元設計
- 基本不考
- 比硬佈線設計方便

微程序 對比 硬佈線
- 重點
| 微程序控制器 | 硬佈線控制器 | |
|---|---|---|
| 工作原理 | 微操作控制信號以微程序的形式存放在控制存儲器中 | 微操作控制信號由組合邏輯電路根據當前的指令碼、狀態和時序即時產生 |
| 執行速度 | 慢 | 快 |
| 規整性 | 較規整 | 煩瑣、不規整 |
| 應用場合 | CISC CPU | RISC CPU |
| 易擴充性 | 易擴充修改 | 困難 |
5.4.3 微指令
5.4.3.1 格式
- 水平型(胖子)
- 微指令長
- 一條微指令能定義多個微命令
- 微程序短
- 編寫麻煩,執行速度快
- 控制信號經過編碼產生
- 充分利用並行
- 微指令長
- 垂直型(瘦子)
- 微指令短
- 一條微指令只定義一個微命令
- 微程序長
- 便於編寫,執行速度慢
- 設置了微操作碼
- 微指令短
- 混合型

編碼方式
- 重點
- 直接編碼
- 一位對應一個微命令
- 字段直接編碼
- 分字段
- 一字段(譯碼之後)對應一組互斥的微命令
- 每個字段需要保留一個空狀態
- 字段間接編碼 1. 直接是一次譯碼,間接是二次譯碼 2. 削弱了並行控制能力


e.g. 例題

地址形成方式
- 重點
- 下地址字段
- 斷定法
- 直接由微指令的下地址(後繼地址)字段指出
- 操作碼
- 根據機器指令的操作碼形成
- 機器指令取至 IR 後,微指令的地址由操作碼由微地址形成部件產生
- 增量計數器法
- 微地址連續:(CMAR) + 1 -> CMAR
- 類似 PC + 1
- 分支轉移
- 根據各種標誌
- 測試網絡形成
- 由硬件直接產生微程序入口地址
- 第一條微指令地址由專門的硬件產生(用專門的硬件記錄取指週期微程序首地址)
- 中斷週期由硬件產生中斷週期微程序首地址(用專門的硬件記錄)
5.5 異常和中斷
5.5.1 概念
- 異常
- CPU 內部產生的意外事件
- 也稱內中斷
- 中斷
- 來自 CPU 外部的設備向 CPU 發出的中斷請求
- 也稱外中斷
- e.g. IO設備(鍵盤輸入)、定時器計數、DMA傳送結束
中斷和異常的處理過程基本相同:
- CPU 在執行用戶的第 條指令時,檢測到異常 / 發現中斷請求
- CPU 打斷當前程序,轉去執行異常 / 中斷處理程序
- 成功解決問題,CPU 執行返回指令,回到被打斷的用戶程序的第 或 條指令繼續執行
- 發現是不可恢復的致命錯誤,終止用戶程序
5.5.2 異常分類
異常按照軟硬可以分為:
- 硬故障中斷
- 硬連線異常引起
- e.g. 總線錯誤、存儲器校驗錯誤
- 硬連線異常引起
- 程序性異常
- 也稱軟件中斷
- CPU 內部執行指令異常
- e.g. 整除0、溢出、斷點、非法指令、棧溢出、地址越界、缺頁
異常按照原因可以分為:
- 故障 Fault
- 引起故障的指令執行中的異常
- 分為是否可恢復
- 可恢復,回到斷點(當前發生故障的指令)
- 取數時,缺頁
- 不可恢復,終止進程
- 譯碼時,非法操作碼
- 除法時,除數0
- 可恢復,回到斷點(當前發生故障的指令)
- 自陷 Trap
- 也稱陷阱 / 陷入
- 一種預先安排的異常,通常是在程序中預先寫入的特殊指令或者特殊標誌,形成一個人為的陷阱,使得 CPU 在執行到陷阱處時,根據不同的陷阱類型轉去內核進行相應處理,處理完之後返回到自陷命令的下一條。
- e.g. 斷點調試、單步跟蹤、系統調用指令、條件自陷指令
- 故障、自陷屬於程序性異常(軟件中斷)
- 終止 Abort
- 硬件錯誤
- 終止、外中斷屬於硬件中斷
- 不是特定指令產生的,是隨機發生的
每個細節、例子都要記清楚,就考概念細節。
5.5.3 中斷分類
中斷分為:
- 可屏蔽中斷
- 通過可屏蔽中斷請求線 INTR 向 CPU 發出的中斷請求
- CPU 通過在中斷控制器中設置相應的屏蔽字來選擇是否屏蔽(不送到 CPU)
- 不可屏蔽中斷
- 通過專門的不可屏蔽中斷請求線 NMI 向 CPU 發出的中斷請求
- e.g. 緊急的硬件故障(電源掉電)
- 通過專門的不可屏蔽中斷請求線 NMI 向 CPU 發出的中斷請求
中斷和異常在本質上相似,不同表現在:
- 異常(除了終止)與特定指令的執行有關;中斷和任何指令無關
- 異常的檢測由 CPU 自身完成;中斷則必須通過中斷請求線獲取信息
- 所有異常和中斷都是由硬件檢測發現的
另外,根據識別中斷服務程序地址的方式,可以分為向量中斷和非向量中斷;根據中斷處理過程是否允許被打斷,分為單重中斷和多重中斷。
5.5.4 響應過程
- 關中斷
- 保存斷點時,不能被新的中斷打斷,禁止響應新的中斷
- 可以通過設置“中斷允許”(IF)觸發器為1,實現開中斷,表示允許響應中斷
- 保存斷點時,不能被新的中斷打斷,禁止響應新的中斷
- 保存斷點和程序狀態
- 保存在棧中
- 支持嵌套
- PSW 也需要保存
- 保存在棧中
- 識別異常 / 中斷,並轉到處理程序
- 軟件識別
- CPU 設置一個異常狀態寄存器,用於記錄異常原因
- 操作系統使用一個統一的異常或中斷查詢程序,按優先級順序查詢異常狀態寄存器,然後轉到內核處理相應程序
- 異常大多采用軟件識別
- 硬件識別(向量中斷)
- 異常或中斷處理程序的首地址稱為中斷向量
- 所有中斷向量存放在中斷向量表
- 每個異常或中斷被指定一個中斷類型號,可據此快速找到對應的處理程序
- 中斷採用軟件 / 硬件識別
- 軟件識別
5.6 指令流水線
5.6.1 基本概念
指令流水線的定義
將指令執行過程的各階段視為相應的流水段,則指令的執行過程就構成了一條指令流水線.
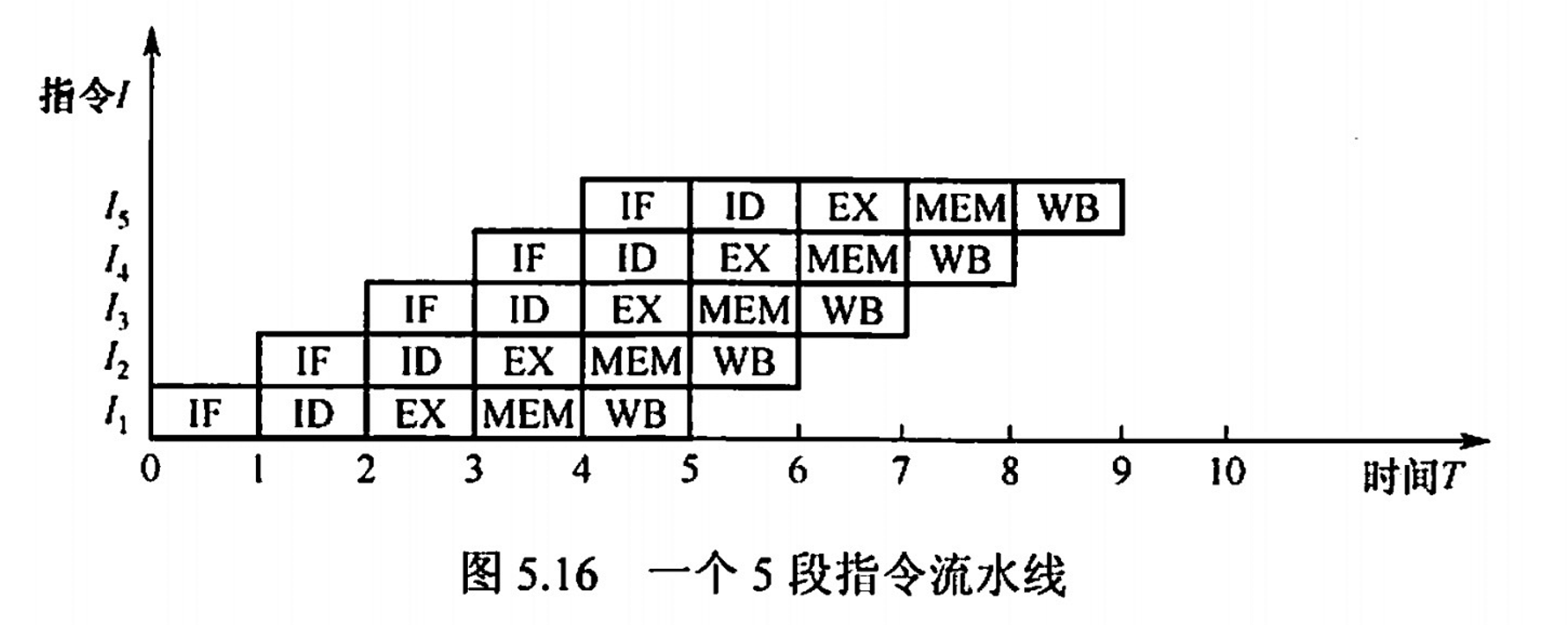
提高並行性
- 時間上的並行技術:
- 將一個任務拆分成幾個不同的子階段
- 每個階段在不同的功能部件上並行執行,即流水線技術
- 空間上的並行技術:
- 在一個處理機設置多個執行相同任務的功能部件
- 並讓這些功能部件並行工作,這樣的處理機稱為超標量處理機
指令集應具備的特點
- 指令長度儘量一致,有利於簡化取指和指令譯碼操作
- 指令格式儘量規整,儘量保證源寄存器的位置相同,有利於在指令未知時就可取存寄存器操作數
- 採用 Load/Store 指令,把 Load/Store 指令的地址計算和運算指令的執行步驟規整到同一個週期中,有利於減少操作步驟
- 數據和指令在存儲器中“對齊”存放,這樣有利於減少訪存次數使所需數據在一個流水段內就可以從存儲器中找到
三種基本方式

5.6.2 性能指標
5.6.2.1 吞吐率
單位時間內流水線所完成的任務數量,或是輸出結果的數量
- 設任務數 n,處理完成 n 個任務所用的時間為
吞吐率:
- 最大吞吐率:

- 前 為裝入時間;前 為排空時間
注意:
- m 段流水線的 CPU 吞吐能力 = m 個並行部件的 CPU 吞吐能力
- m 段流水線在第 m 個時鐘週期後,每個時鐘週期都可完成一條指令
- m 個並行部件在 m 個時鐘週期後能完成全部的 m 條指令,等價於平均每個時鐘週期完成一條指令
加速比
完成同樣一批任務,不使用流水線所用的時間與使用流水線所用的時間之比
- 設順序執行的時間為 ,使用流水線的執行時間
- 最大加速比:
效率
流水線的設備利用率,在時空圖上,表示為完成 n 個任務佔用的時空區有效面積與 n 個任務所用的時間與 k 個流水段所圍成的時空區總面積之比。(看圖理解)

5.6.3 五段式
為方便流水線的設計,將每個階段的耗時取成一樣,以最長耗時為準。
流水線每一個功能段部件後面都要有一個緩衝寄存器,或稱為鎖存器, 其作用是保存本流水段的執行結果,提供給下一流水段使用。
運算類指令的執行過程:

LOAD 指令:

STORE 指令:

通常, RISC處理器只有“取數LOAD”和“存數STORE”指令才需要訪問主存;其他指令都是用寄存器的數據或者立即數。
條件轉移指令:

- 條件轉移的寫回 PC 發生在 M 段,不是 WB 段
無條件轉移指令:

- 寫回 PC 越早越好,所以無條件轉移的寫回 PC 在 EX 段
例題

重點關注紅框:
- 前一條指令必須進入譯碼之後,後一條才能取指令
- 不然,在指令的鎖存器中,後一條指令會直接覆蓋前一條指令
5.6.4 冒險
- 結構冒險
- 資源衝突
- 由於多條指令在同一時刻爭用同一資源,而形成的衝突稱為結構相關。
- 解決辦法:
- 後一相關指令暫停一週期
- 資源重複配置
- 數據存儲器+指令存儲器,也叫指令 Cache 和 數據 Cache 分離
- 數據冒險
- 數據衝突
- 在一個程序中,存在必須等前一條指令執行完才能執行後一條指令的情況, 則這兩條指令即數據相關。
- 解決辦法:
- 把遇到數據相關的指令及其後續指令都暫停一至幾個時鐘週期,直到數據相關問題消失後再繼續執行。
- 主要有 硬件阻塞(stall)和 軟件插入空指令 NOP 兩種方法
- 數據旁路
- 編譯優化:調整指令順序
- 把遇到數據相關的指令及其後續指令都暫停一至幾個時鐘週期,直到數據相關問題消失後再繼續執行。
- 控制冒險
- 控制衝突
- 當流水線遇到轉移指令和其他改變PC值的指令而造成斷流時,會引起控制相關。
- 解決方法:
- 分支預測
- 靜態預測
- 每次預測結果是一致的
- 總是預測條件不滿足(not taken),可加啟發式規則:在特定情況下總是預測滿足(taken)
- 每次預測結果是一致的
- 動態預測
- 根據程序執行的歷史情況,進行動態預測調整,能達90%的預測準確率,成功率高
- 靜態預測
- 預取兩個方向的指令
- 加快和提前形成條件碼
- 提高轉移方向的猜準率
- 分支預測
5.6.5 分類
- 不考,動態流水線可以看一下


5.6.6 高級流水線
5.6.6.1 超標量
每個時鐘週期內可併發多條獨立指令,以並行操作方式將兩條或多條指令編譯並執行,也稱動態多發射技術(動態調度技術)。
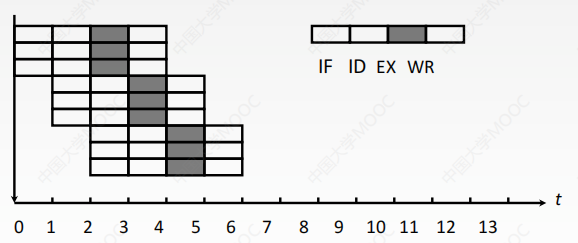
- 每個時鐘週期內可併發多條獨立指令
- 並不影響流水線功能段的處理時間
- 要配置多個功能部件,實際上是以空間換時間
- 亂序執行
- 不能調整指令順序,通過編譯優化技術,把可並行執行的指令搭配起來
之前介紹的普通流水線是常規標量的單流水線。
超長指令字
由編譯程序挖掘出指令潛在的並行性,將多條能並行操作的指令組合成一條具有多個操作碼的超長指令字(可達幾百位),也稱靜態多發射技術。
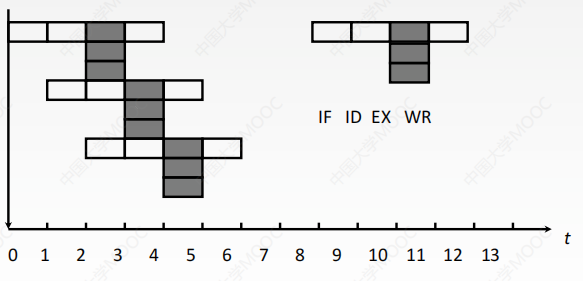
- 需要多個處理部件
超流水線
- 時分複用思路
在一個時鐘週期內再分段,在一個時鐘週期內一個功能部伴使用多次。
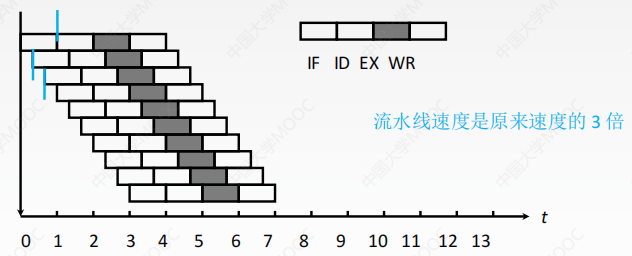
- 流水線功能段越多,時鐘週期越短,指令吞吐率越高
- 通過提高流水線主頻的方式來提升流水線性能的
- 流水線級數越多,用於流水線寄存器的開銷越大
- 不能調整指令順序,依靠編譯優化
5.7 多處理器
5.7.1 基本概念
- 基於指令流的數量和數據流的數量,將計算機體系結構分為 SISD,SIMD,MISD 和 MIMD
- 常規的單處理機屬於 SSID,常規的多處理機屬於 MIMD
5.7.2 SISD
- 單指令流單數據流結構
- 單指令流:指令序列只能併發,不能並行
- 單數據流:一個指令一次只處理一個數據流(一個 / 對數據)
- 408計組使用的就是 SISD
- 串行計算機結構
- 通常只包含一個處理器和一個存儲器
- 有些使用流水線的方式,所以有時會設置多個功能部件,並採用多模塊交叉方式組織存儲器
5.7.3 SIMD
- 單指令流多數據流結構
- 數據級並行技術
- 一個指令流同時對多個數據流進行處理
- 由一個指令控制部件、多個處理單元組成
- 每個處理單元雖然執行的都是同一條指令, 但每個單元都有自己的地址寄存器(局部存儲器),就有了不同的數據地址
- 一個順序應用程序被編譯之後, 可能按照 SISD 組織並運行於串行硬件上,也可能按 SIMD 組織並運行於並行硬件上
- for 循環效率高,但 switch 或 case 時效率低

向量處理器也是 SIMD 的變體,是一種實現了直接操作一維數組(向量)指令集的 CPU。

5.7.4 MISD
- 多指令流單數據流結構
- 多指令流:指令序列並行
- 同時執行多條指令,處理同一個數據
- 實際上不存在這樣的計算機
5.7.5 MIMD
- 多指令流多數據流結構
- 現代計算機就是 MIMD
- 線程級並行、甚至是線程級以上並行技術
- 同時執行多條指令,處理多個不同的數據
MIMD 分為多計算機系統和多處理器系統:
- 多計算機系統
- 分佈式計算機系統
- 每個計算機節點都具有各自的私有存儲器,並且具有獨立的主存地址空間
- 不能通過存取指令來訪問不同節點的私有存儲器
- 而要通過消息傳遞進行數據傳送,也稱為消息傳遞 MIMD

- 多處理器系統
- 共享存儲多處理器(SMP)系統的簡稱
- 它具有共享的單一地址空間,通過訪存指令來訪問系統中的所有存儲器,也稱共享存儲 MIMD
5.7.6 多核處理器
- 將多個處理單元集成到單個 CPU 中,每個處理單元稱為一個核(core)
- 每個核可以有自己的 Cache,也可以共享一個 Cache
- 所有核一般都是對稱的,並且共享主存,因此多核屬於共享存儲的對稱多處理器
- 2.4GHz 的雙核,兩個核都是 2.4GHz
- 在多核計算機系統中,若要充分發揮硬件的性能,必須採用多線程執行,使每個核在同一時刻都有線程在執行,這是真正的並行執行
5.8 硬件多線程
- 引入硬件多線程的目的:為了減少開銷
- 硬件多線程中必須為每個線程提供單獨的通用寄存器組、單獨的程序計數器等
- 線程的激活只需要激活選中的寄存器,從而省略了與存儲器數據交換的環節,節省了開銷
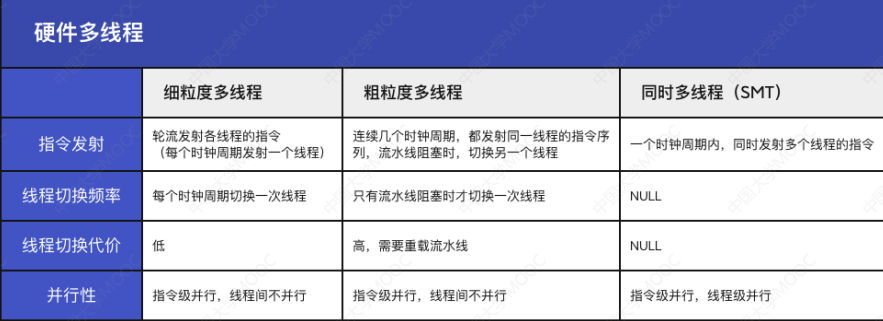
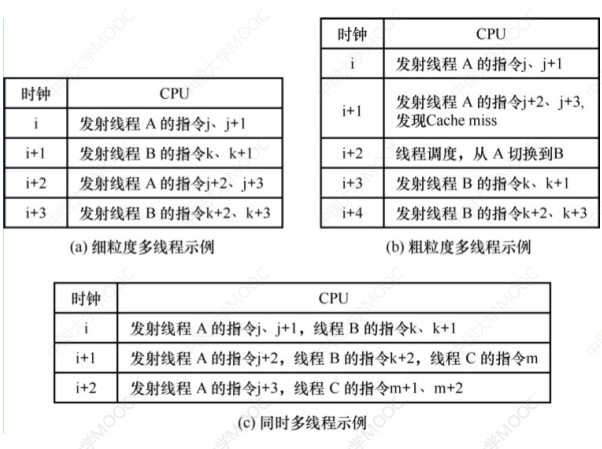
5.8.1 細粒度多線程
- 多個線程之間輪流交叉執行指令,多個線程之間的指令是互不相關的
- 可以亂序並行執行
- 該方式下,處理器能在每個時鐘週期切換線程
- 指令級並行,線程間不併行
5.8.2 粗粒度多線程
- 連續幾個時鐘週期都執行同一線程的指令序列
- 僅在一個線程出現較大開銷的阻塞(流水線阻塞)時,才切換線程
- 如 Cache 缺失
- 當發生流水線阻塞的時候,必須清除被阻塞的流水線
- 新線程的指令開始執行前需要重載流水線,開銷較上一種較大
- 指令級並行,線程間不併行
5.8.3 同時多線程(SMT)
- 又叫做超線程技術 HT
- 一個 CPU 提供兩套線程處理單元
- 性能不等於兩個 CPU,模擬實體雙核,雙核也不是獨立資源
- 一個時鐘週期內,同時發射多個線程的指令
- 指令級並行,線程級並行
6 總線
6.1 概述
總線的物理實現:

總線是一組能夠為多個部件分時和共享的公共信息傳送線路。
- I/O 設備的種類和數量越來越多,設計總線來解決 I/O 設備與主機之間連接的靈活性
- 優點:便於增減外設,減少信息傳輸線的條數
- 缺點:降低了信息傳輸的並行性和信息的傳輸速度
兩大特點:
- 分時性
- 同一時刻只允許有一個部件向總線發送消息,如果系統中有多個部件,則它們只能分時地向總線發送消息
- 共享性
- 總線上可以掛接多個部件,多個部件可同時從總線上接收相同的信息
按其對總線有無控制能力可分為主設備和從設備:
- 主設備:獲得總線控制權的設備
- 從設備:被主設備訪問的設備,它只能響應從主設備發來的各種總線命令
總線的其他特性:
- 機械特性:尺寸,形狀
- 電氣特性:傳輸方向和有效電平範圍
- 功能特性:每根傳輸線的功能
- 時間特性:信號和時序的關係
6.2 分類
6.2.1 按數據傳輸方式
- 串行傳輸
- 只有一條雙向傳輸 / 兩條單向傳輸的數據線,數據按比特串行傳輸
- 優點
- 成本低廉,廣泛應用於長距離傳輸
- 應用於計算機內部時,可以節省佈線空間
- 可通過不斷提高工作頻率來提高傳輸速度,使其速度最終超越並行總線
- 缺點
- 在數據發送和接收的時候要進行拆卸和裝配,要考慮串行-並行轉換的問題
- 並行傳輸
- 有多條雙向傳輸的數據線,可以實現多比特位的同時傳輸
- 優點
- 總線的邏輯時序比較簡單,電路實現起來比較容易
- 缺點
- 信號線數量多,佔用更多的佈線空間
- 數據線之間相互干擾會造成傳輸錯誤,因此適合近距離傳輸
- 總線複用方式:不同信號在同一條信號線上分時傳輸
6.2.2 按功能
- 片內總線
- CPU 芯片內部寄存器與寄存器之間、寄存器與 ALU 之間的總線
- 系統總線
- 各功能部件(CPU、主存、I/O 接口)之間相互連接的總線
- 按系統總線傳輸內容的不同又可分為 3 類
- 數據總線
- 傳輸各功能部件之間的數據信息
- 是雙向傳輸線
- 位數反映一次能傳送的數據的位數
- 與機器字長、存儲字長有關
- 區分:數據通路表示的是數據流經的路徑;數據總線是承載的媒介
- 地址總線
- 指出主存和 I/O 設備接口電路的地址
- 是單向傳輸線
- 位數反映最大的尋址空間
- 與主存地址空間大小及設備數量有關
- 控制總線
- 一根控制線傳輸一個信號
- 有出:CPU 送出的控制命令
- 有入:主存(或外設)返回 CPU 的控制信號
- 數據總線
- 通信總線
- 也稱外部總線
- 計算機系統之間或計算機系統與其他系統(如遠程通信服務、測試設備)之間傳送信息的總線
- I/O 總線
- 主要用於連接中低速的 I/O 設備
- 通過 I/O 接口與系統總線相連接
- 目的是將低速設備和高速總線分離,以提升總線的系統性能
- 常見的有 USB、PCI 總線
6.2.3 按時序控制
- 同步總線
- 總線上連接的部件或設備通過統一的時鐘進行同步
- 異步總線
- 以信號握手的方式來協調各部件或設備之間的信息傳輸,總線操作時序不固定
6.3 系統總線的結構
6.3.1.1 單總線結構
CPU、主存、I/O 設備(通過 I/O 接口)都連接在一組系統總線上,允許 I/O 設備之間、I/O 設備和 CPU 之間或 I/O 設備與主存之間直接交換信息。
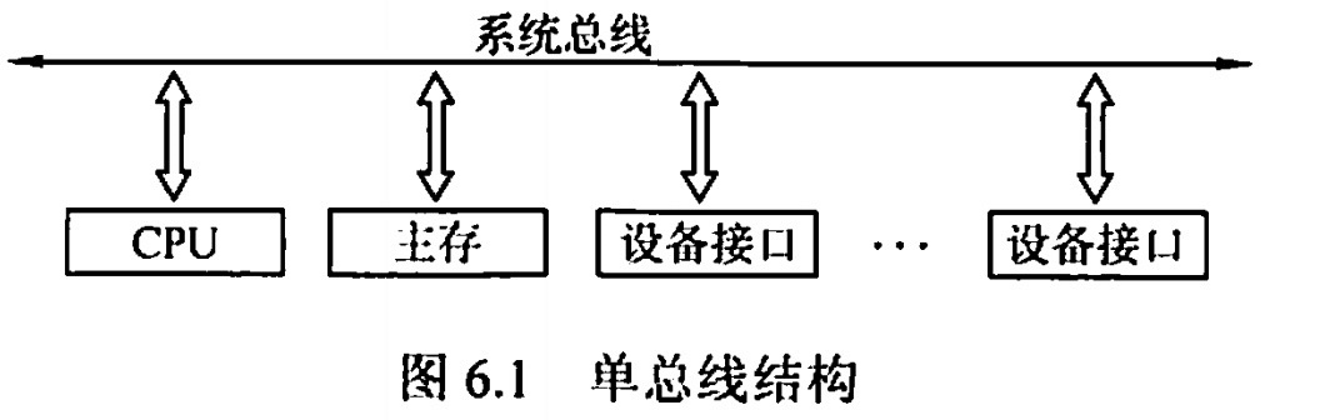
- 優點:結構簡單,成本低,易於接入新的設備
- 缺點:帶寬低,負載重,多個部件只能徵用唯一的總線,且不支持併發傳送操作
雙總線結構
雙總線結構有兩條總線:
- 主存總線
- 用於 CPU、主存和通道之間進行數據傳送
- I/O 總線
- 用於多個外部設備與通道之間進行數據傳送
- 主存總線和IO總線通過通道連接

- 通道
- 具有特殊功能的處理器, 能對IO設備進行統一管理
- 將較低速的 I/O 設備從單總線上分離出來,實現存儲器總線和 I/O 總線分離
- 突發(猝發)傳送
- 送出一個地址,收到多個地址連續的數據
- 一次總線事務中,主設備只需給出一個首地址,就可以從首地址開始的若干連續單元讀出或寫入多個數據
- 缺點:需要增加通道等硬件設備
三總線結構
三總線結構:
- 主存總線
- I/O 總線
- DMA 總線(直接內存訪問)

- 優點:提高了 I/O 設備的性能,使其更快地響應命令,提高系統吞吐量
- DMA 使得高速外設不用走速度慢的IO總線
- 缺點:系統工作效率較低
四總線結構
橋接器:用於連接不同的總線,具有數據緩衝、轉換和控制功能。

6.3.2 性能指標
- 總線傳輸週期
- 總線週期
- 一次總線操作所需的時間,由若干總線時鐘週期構成
- 包括申請階段、尋址階段、傳輸階段和結束階段
- 總線時鐘週期
- 機器的時鐘週期
- 計算機有一個統一的時鐘,以控制整個計算機的各個部件,總線也要受此時鐘的控制
- 現在的計算機中,總線時鐘週期也有可能由橋接器提供
- 總線週期和時鐘週期的關係是不確定的,按題目來
- 總線時鐘頻率
- 機器的時鐘頻率,為時鐘週期的倒數
- 總線工作頻率
- 總線上各種操作的頻率,為總線週期的倒數
- 若總線週期 = N 個時鐘週期,則總線的
- 實際上指一秒內傳送幾次數據
- e.g. 若一個時鐘週期傳兩次數據,則工作頻率是時鐘頻率的兩倍
- 總線寬度
- 總線位寬
- 總線上同時能傳輸的數據位數
- 通常指數據總線的根數,如 32 根稱為 32 位(bit)總線
- 總線帶寬
- 總線的最大數據傳輸率,即單位時間內總線上最多可傳輸數據的位數
- 在計算實際的有效數據傳輸率時,要用實際傳輸的數據量除以耗時
- 總線複用
- 一種信號線在不同的時間傳輸不同的信息
- 可以使用較少的線傳輸更多的信息,從而節約空間和成本
- 信號線數
- 地址總線、數據總線和控制總線3種總線數的總和稱為信號線數
6.3.3 常見的總線標準
- 不考
總線標準是國際上公佈的互連各個模塊的標準,是把各種不同的模塊組成計算機系統時必須遵守的規範。
- PCI,EISA,ISA是並行總線
- USB,PCI-Expressx16是串行總線
- 高速設備採用局部總線連接,可以節省系統的總帶寬
常見 12 種標準:
- ISA:
- 工業標準體系結構
- 非局部總線
- 最早出現的微型計算機的系統總線,應用在IBM的AT機上
- EISA:擴展的ISA
- VESA:視頻電子標準協會
- PCI:
- 外部設備互連
- 支持即插即用,局部總線
- AGP:加速圖形接口,一種視頻接口標準
- PCI-E:最新的總線接口標準,它將全面取代線性的PCI和AGP
- RS-232C:
- 由美國電子工業協會推薦的一種串行通信總線
- 適用於串行二進制交換的數據終端設備和數據通信設備之間的標準接口
- USB:
- 通用串行總線
- 即插即用,熱插拔,有很強的連接能力,有很好的可擴展性;高速傳輸
- PCMCIA:
- 廣泛應用於筆記本電腦的一種接口標準
- 是一個用於擴展功能的小型插槽。即插即用
- IDE:
- 集成設備電路
- 更準確地稱為ATA,硬盤和光驅通過IDE接口與主板連接
- SCSI:
- 小型計算機系統接口
- 是一種用於計算機和智能設備之間(硬盤、軟驅)系統級接口的獨立處理器標準
- SATA:
- 串行高級技術附件
- 是一種基於行業標準的串行硬件驅動器接口
6.4 事務和定時
6.4.1 總線事務
從請求總線到完成總線使用的操作序列,即在一個總線週期中發生的一系列活動。
總線週期的四個階段:
- 申請階段
- 傳輸請求
- 主設備(CPU 或 DMA)發出總線傳輸請求,並且獲得總線控制權
- 總線仲裁
- 總線仲裁機構決定將下一個傳輸週期的總線使用權授予某個申請者
- 傳輸請求
- 尋址階段
- 主設備通過總線給出要訪問的從設備地址及有關命令,啟動從模塊
- 傳輸階段
- 主模塊和從模塊進行數據交換,可單向或雙向進行數據傳送(一般只能傳輸一個字長的數據)
- 結束 / 釋放階段
- 主模塊的有關信息均從系統總線上撤除,讓出總線使用權
總線上的數據傳送方式:
- 非突發式
- 在每個傳送週期內都先傳送地址,再傳送數據
- 主、從設備之間通常每次只能傳輸一個字長的數據
- 突發(猝發)式
- 發送方在傳輸完成地址後,連續進行若干次數據的發送,即一次傳輸一個地址和一批連續的數據
- 能夠進行連續成組數據的傳送;其尋址階段發送的是連續數據單元的首地址
- 可以提高總線數據傳輸率
- 主設備只需給出一個首地址,從設備就能從首地址開始的若干連續單元讀出或寫入多個數據
6.4.2 總線定時
總線在雙方交換數據的過程中需要時間上配合關係的控制,實質是一種協議或者規則。
同步定時方式
- 由統一時序控制的通信方式
- 同步通信採用公共時鐘,有統一的時鐘週期,同步時鐘信號不由各設備提供
- 同步控制既可以用於 CPU 控制,又可用於高速的外部設備控制
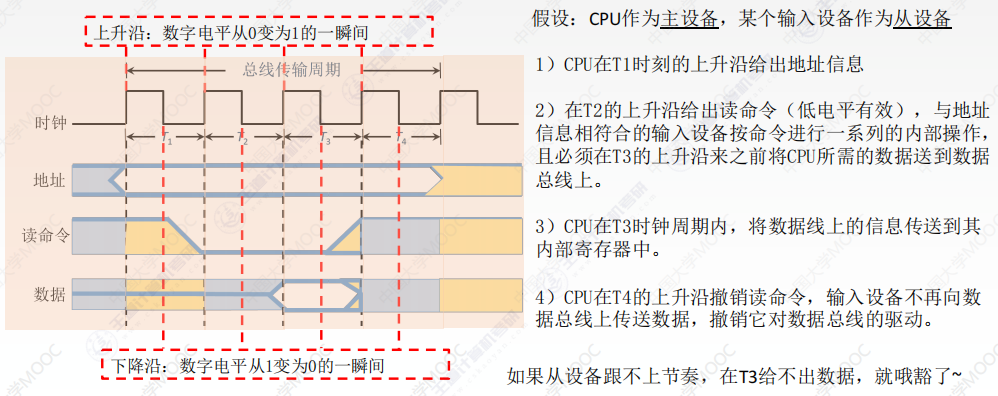
優點:
- 傳送速度快,具有較高的傳輸速率
- 總線控制邏輯簡單
- 同步通信不需要應答信息且總線長度短
- 同步通信用一個公共的時鐘信號進行同步
- 同步通信中,各部件的存取時間較接近
缺點:
- 主從設備屬於強制性同步
- 不能及時進行數據通信的有效性驗證
- 可靠性較差
適用場景
- 適用於總線長度較短及總線所接部件的存儲時間比較接近的系統
- 採用同步控制也可以進行數據的傳輸,但不能發揮快速設備的高速性能
異步定時方式
- 沒有統一的時鐘;沒有固定的時間間隔;不採用時鐘信號,只採用握手
- 完全依靠傳送雙方相互制約的“握手”信號來實現定時控制
- 傳送操作是由雙方按需求分配時間的
- 每次握手完成一次通信,但是一次通信往往交換多位數據
優點:
- 總線週期長度可變
- 能保證兩個工作速度相差很大的部件或設備之間可靠地進行信息交換
- 自動適應時間的配合
缺點:
- 比同步稍複雜一些,速度比同步方式慢
適用場景
- 主要用於在不同的設備間進行通信
分類
- 不互鎖方式
- 主設備發出“請求”信號後,不必等到接到從設備的“回答”信號,而是經過一段時間,便撤銷“請求”信號
- 從設備在接到“請求”信號後,發出“回答”信號,並經過一段時間,自動撤銷“回答”信號。雙方不存在互鎖關係
- 速度最快,可靠性最差
- 半互鎖方式
- 主設備發出“請求”信號後,必須待接到從設備的“回答”信號後,才撤銷“請求”信號,有互鎖的關係
- 從設備在接到“請求”信號後,發出“回答”信號,但不必等待獲知主設備的“請求”信號已經撤銷,而是隔一段時間後自動撤銷“回答”信號,不存在互鎖關係
- 全互鎖方式
- 主設備發出“請求”信號後,必須待從設備“回答”後,才撤銷“請求”信號
- 從設備發出“回答”信號,必須待獲知主設備“請求”信號已撤銷後,再撤銷其“回答”信號。雙方存在互鎖關係
- 最可靠,速度最慢
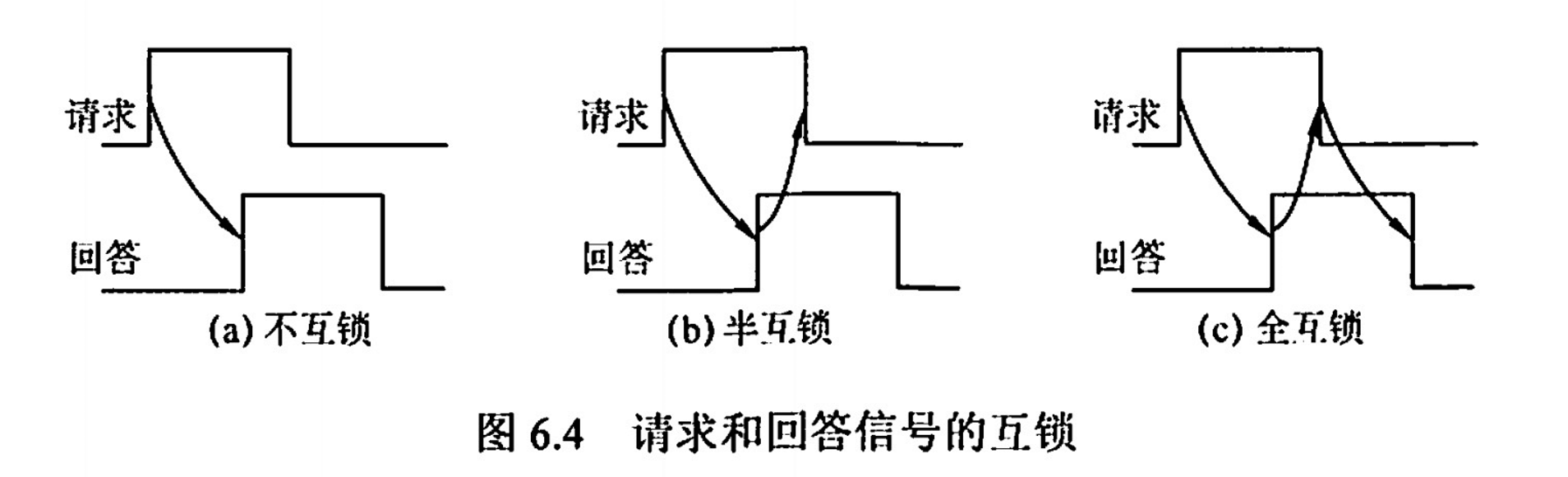
半同步定時方式
統一時鐘的基礎上,增加一個 “等待”響應信號 WAIT
- 同步:
- 發送方用系統時鐘前沿發信號
- 接收方用系統時鐘後沿判斷、識別
- 異步:允許不同速度的模塊和諧工作
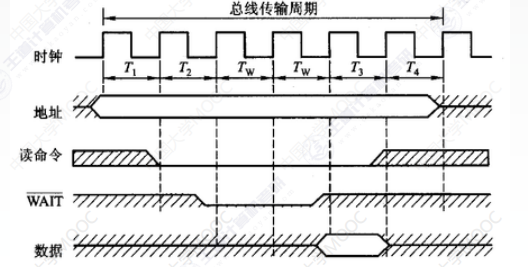
優點:
- 控制方式比異步定時簡單
- 各模塊在系統時鐘的控制下同步工作,可靠性較高
缺點:
- 系統的時鐘頻率不能要求太高
- 整體上看,系統工作的速度不是很高
分離式定時方式
之前三種通信方式的共同點:
- 主模塊發地址、命令(總線被使用)
- 從模塊準備數據(總線空閒)
- 從模塊向主模塊發數據(總線被使用)
簡單來說,分離式就是為了充分利用中間總線空閒的時間。
分離式將總線事務分解為請求和應答兩個子過程:
- 子週期 1:主模塊申請佔用總線,使用完後放棄總線的使用權
- 子週期 2:從模塊申請佔用總線,將各種信息送至總線上
各模塊均有權申請佔用總線
- 採用同步方式通信,不等對方回答
- 各模塊準備數據時,不佔用總線
- 總線利用率提高
優點:
- 在不傳送數據是釋放總線,使總線可接受其他設備的請求,不存在空閒等待時間
缺點:
- 控制複雜,開銷較大
7 IO系統
IO系統的基本組成:

7.1 IO接口
IO接口就是 IO控制器。
可分為:
- 並行接口、串行接口
- 程序查詢接口、中斷接口、DMA接口
- 可編程接口、不可編程接口
7.1.1 控制方式
- 大概率不考

程序查詢、程序中斷:

但是對於高速IO設備,比如磁盤,假如每準備好一個字就向 CPU 發出中斷請求,則 CPU 會浪費很多時間在處理中斷程序,利用率下降。
可以採用 DMA 的方式處理高速IO設備:

另外,對於有大量IO設備的場景,只依靠 CPU 處理IO是不夠的,需要引入通道控制方式,通道可以理解為是一個只有部分功能的弱 CPU。

7.1.2 功能
IO接口的功能:
- 進行地址譯碼和設備選擇
- 使主機和指定外設交換信息
- 實現主機和外設的通信聯絡控制
- 實現主機—I/O 接口—I/O 設備之間的通信
- 實現數據緩衝
- 通過數據緩衝寄存器(DBR)達到主機和外設工作速度的匹配
- 信號格式的轉換
- 串-並、並-串、電平、數-模、模-數等格式轉換
- 因為存在外部設備串行輸入,而IO接口需要向 CPU 並行發送數據的情況
- 傳送控制命令和狀態信息
- 接收從控制總線發來的控制信號、時鐘信號
- 通過狀態寄存器反饋設備的各種錯誤、狀態信息,供 CPU 查用

- 外部接口:通過接口電纜與外設連接,數據傳輸可能是串行方式,因此 I/O 接口需具有串/並轉換功能
- 內部接口與系統總線相連,實質上是與內存、CPU 相連
7.1.3 基本結構

主機與外設之間的連接通路:
- 主機/內存 --- 系統總線(IO總線) --- IO接口 --- 通信總線(接口電纜) --- 外設
接口內的寄存器:
- 數據緩衝寄存器
- 狀態寄存器
- 控制寄存器
主機側:
- 數據線
- 讀寫數據、狀態字、控制字、中斷類型號
- 2012真題
- 讀寫數據、狀態字、控制字、中斷類型號
- 地址線
- 端口地址
- 控制線
- 讀寫信號、中斷信號
如何確定要操作的設備:每個設備對應一組寄存器,操作不同的寄存器就是在操作不同的設備
補充:I/O 指令
- 對數據緩衝寄存器、狀態/控制寄存器的進行訪問操作的指令
- 只能在 OS 內核的底層 I/O 軟件中使用
- I/O 指令實現的數據傳送通常發生在通用寄存器和 IO 端口之間
- 2017真題
- 是一種特權指令,是機器指令的一類,是系統指令的一部分
- 與通用指令格式不同
7.1.4 IO端口及其編址
IO端口:IO控制器中的各種寄存器
- 接口 = 端口 + 相應的控制邏輯
- IO接口中,CPU 可訪問的寄存器稱為 IO端口
- 2014真題
主要的 I/O 端口有:
- 數據端口:CPU 對數據端口中的數據執行讀寫操作
- 狀態端口:對狀態端口中的外設狀態只能執行讀操作
- 控制端口:對控制端口中的各種控制命令只能執行寫操作
兩種編址方式:

統一編址
存儲器映射方式
把 I/O 端口當做存儲器的單元進行地址分配
CPU 不需要設置專門的 I/O 指令,用統一的訪存指令就可以訪問 I/O 端口
依靠地址碼的不同區分存儲單元和 I/O 設備
RISC 常用
優點:
- 不需要專門的 I/O 指令
- 可以使 CPU 訪問 I/O 的操作更靈活、更方便
- 可以使端口有較大的編址空間
缺點:
- 端口占用主存地址空間,使內存容量變小
- 外設尋址時間長(地址位數多,地址譯碼速度慢)
- 譯碼電路複雜,降低了譯碼速度
- 在識別 I/O 端口時全部地址線都需要參加譯碼
獨立編址
I/O 映射方式
I/O 端口的地址空間與主存地址空間是兩個獨立的地址空間
需要設置專門的 I/O 指令來訪存 I/O 端口
通過專門的 I/O 指令來區分存儲單元和 I/O 設備
I/O 指令的地址碼給出 I/O 端口號
INTEL 常用
優點:
- 使用專用 I/O 指令,比如 IN、OUT,程序編制清晰
- I/O 端口地址位數少,譯碼簡單,地址譯碼速度快
缺點:
- I/O 指令少,一般只能對端口進行傳送操作
- 需要 CPU 提供存儲器讀/寫、I/O 設備讀/寫兩組控制信號,增加了控制邏輯電路的複雜性
7.2 IO方式
7.2.1 程序查詢方式

- 主要特點
- CPU 有“踏步”等待現象
- CPU 與 I/O 串行工作
- 優點
- 接口設計簡單,設備量少
- 缺點
- CPU 在信息傳送過程中要花費很多時間來查詢和等待
- 在一段時間內只能和一臺外設交換信息,效率大大降低
- 獨佔查詢
- 一旦設備被啟動,CPU 就一直持續查詢接口狀態,CPU 花費 100% 的時間用於 I/O 操作,此時外設和 CPU 完全串行工作
- 定時查詢
- CPU 週期第查詢接口狀態,每次總是等到條件滿足才進行一個數據的傳送,傳送完成後返回到用戶程序
- 時間間隔與設備的數據傳輸速率有關
7.2.2 程序中斷方式
中斷技術簡介
在計算機執行現行程序的過程中,出現某些急需處理的異常情況或特殊情求 CPU 暫停中止現行程序而轉去對這些異常情況或特殊請求進行處理,處理完畢後再返回到現行程序的斷點處,繼續執行原程序。
- 早期的中斷技術就是為了處理數據傳送
- 中斷響應階段 CPU 進行的操作
- 關中斷
- 保護斷點和程序狀態
- 識別中斷源
- 多重中斷系統在保護被中斷進程現場時關中斷,執行中斷程序時開中斷
- CPU 一般在一條指令執行結束的階段採樣中斷請求信號,查看是否存在中斷請求,然後決定是否響應中斷
- 中斷隱指令的工作
- 關中斷
- 保存斷點
- 引出中斷服務程序
- 通用計算器的保護由中斷服務程序完成
- 中斷優先級由屏蔽字決定,而不是根據請求的先後次序
- 有中斷請求時,如果是關中斷的姿態,或新中斷請求的優先級較低,則不能響應新的中斷請求
主要功能:
- 實現 CPU 和 I/O 設備的並行工作
- 處理硬件故障和軟件錯誤
- 實現人機交互,用戶干預機器需要用到中斷系統
- 實現多道程序、分時操作,多道程序的切換需要藉助於中斷系統
- 實時處理需要藉助中斷系統來實現快速相應
- 實現應用程序和操作系統(管態程序)的切換,稱為軟中斷
- 多處理器系統中各處理器之間的信息交流和任務切換
主要思想:
- CPU 在程序中安排好在某個時機啟動某臺外設
- 然後 CPU 繼續執行當前的程序,不需要像查詢方式那樣等待外設準備就緒
- 一旦外設完成數據傳送的準備工作,就主動向 CPU 發出中斷請求,請求 CPU 為自己服務
- 在可以響應中斷的條件下,CPU 暫時中止正在執行的程序,轉去執行中斷服務程序為外設服務,在中斷服務程序中完成一次主機與外設之間的數據傳送,傳送完成後,CPU 回到原來的程序
中斷請求
CPU響應中斷必須滿足以下3個條件:
- 中斷源有中斷請求
- CPU允許中斷,即開中斷
- 一條指令執行完畢,且沒有更緊迫的任務
中斷源是請求 CPU 中斷的設備或事件,一臺計算機允許有多個。
為了記錄中斷時間並區分中斷源,中斷系統對每個中斷源設置中斷請求標記觸發器INTR。
- 1 表示有請求
這些觸發器組成中斷請求標記寄存器:

- 該寄存器可集中在 CPU 中,也可分散在各個中斷源中
另外,
- 可屏蔽中斷:INTR 線發出,關中斷模式下不被響應
- 在IO系統這一章,基本只討論可屏蔽中斷
- 不可屏蔽中斷:NMI 線發出,如時鐘中斷、電源掉電
中斷判優
中斷判優可以通過硬件 / 軟件實現:
- 軟件:通過查詢程序實現
- 比硬件慢,不常用

- 硬件:通過硬件排隊器實現

優先級設置:
- 不可屏蔽中斷 > 內部異常 > 可屏蔽中斷
- 硬件故障 > 軟件中斷
- DMA 中斷請求 > I/O 設備傳送的中斷請求
- 高速設備 > 低速設備
- 輸入設備 > 輸出設備
- 實時設備 > 普通設備
注意:
- 中斷優先級包括響應優先級和處理優先級
- 響應優先級由硬件線路或查詢程序的查詢順序決定,不可動態改變
- 處理優先級可有中斷屏蔽技術動態調整,以實現多重中斷
中斷響應
- 2016大題
中斷響應階段,CPU執行中斷隱指令。
中斷隱指令:硬件的一系列自動操作,用於執行中斷服務程序(並不是指令系統中的一條真正的指令)
- 關中斷
- 在保護程序的斷點和現場信息過程中,不能響應更高級中斷源的中斷請求
- 保存斷點
- 將原程序的斷點保存在棧或特定寄存器中
- 中斷的斷點是下一條指令的地址
- 引出中斷服務程序
- 識別中斷源,將對應的服務程序入口地址送入 PC
- 如何找到入口地址見下一節
中斷識別
中斷識別分為:
- 向量中斷 / 硬件向量法
- 非向量中斷 / 軟件查詢法
硬件向量法: CPU 響應中斷後,通過識別中斷源獲得中斷類型號(也叫向量地址),然後據此計算出對應中斷向量的地址;再根據該地址從中斷向量表中取出中斷服務程序的入口地址,並送入 PC,以轉而執行中斷服務程序。

每個中斷源有一個唯一的類型號
- 每個中斷類型號對應一箇中斷服務程序
- 類型號也叫向量地址,作用就是找到向量的地址
中斷向量
- 中斷服務程序的入口地址
中斷向量表
- 存儲系統中的全部中斷向量
注意:
- 中斷請求和響應信號是在 I/O 總線的控制線上傳送
- CPU 響應某一中斷後,就從數據線上獲取該中斷源的中斷類型號,並計算對應中斷向量在中斷向量表中的位置
中斷服務程序
中斷服務程序的主要任務:
- 保護現場
- 保存通用寄存器和狀態寄存器的內容,以便返回原程序後可以恢復CPU環境。可使用堆棧,也可以使用特定存儲單元。
- eg:保存ACC寄存器的值
- 保存通用寄存器和狀態寄存器的內容,以便返回原程序後可以恢復CPU環境。可使用堆棧,也可以使用特定存儲單元。
- 中斷服務(設備服務)
- 主體部分,如通過程序控制需打印的字符代碼送入打印機的緩衝存儲器中
- eg:中斷服務的過程中有可能修改ACC寄存器的值
- 主體部分,如通過程序控制需打印的字符代碼送入打印機的緩衝存儲器中
- 恢復現場
- 通過出棧指令或取數指令把之前保存的信息送回寄存器中
- eg:把原程序算到一般的ACC值恢復原樣
- 通過出棧指令或取數指令把之前保存的信息送回寄存器中
- 中斷返回
- 通過中斷返回指令回到原程序斷點處。
整個中斷處理過程
中斷處理過程分為:
- 執行中斷隱指令(中斷響應)
- 中斷服務程序

多重中斷
- 單重中斷:若CPU在執行中斷服務程序的過程中,又出現了新的更高優先級的中斷請求,而CPU對新的中斷請求不予響應
- 多重中斷(中斷嵌套):若 CPU 在執行中斷服務程序的過程中,又出現了新的、更高優先級的中斷請求,CPU 暫停現行的中斷服務程序,轉去處理新的中斷請求
CPU 支持多重中斷的條件:
- 在中斷服務程序中提前設置開中斷指令
- 優先級別高的中斷源 有權中斷 優先級別低的中斷源
多重中斷需要應用中斷屏蔽技術:
- 每個中斷源都有一個屏蔽觸發器(MASK)
- 1 表示屏蔽該中斷源的請求,0 表示可以正常請求
- 所用 MASK 組合在一起便構成一個屏蔽字寄存器,寄存器的內容稱為屏蔽字
- 屏蔽字中 1 越多,優先級越高
- 每個屏蔽字中至少有一個 1
- 至少能屏蔽自身的中斷
需要改造之前的硬件排隊器,加上 MASK:

e.g. 求屏蔽字

e.g. 求執行軌跡

程序中斷總結

7.2.3 DMA 方式
- Direct Memory Access 直接存儲器存取
- 一種完全由硬件進行成組信息傳送的控制方式
DMA 在數據準備階段,CPU與外設並行工作,在外設與內存之間開闢一條直接數據通路,信息傳送不再經過 CPU。
- 不需要保護、恢復CPU現場等操作,降低了CPU在傳送數據時的開銷
- 適用於磁盤、顯卡、聲卡、網卡等高速設備大批量數據的傳送
- 硬件開銷大
DMA 方式中,中斷的作用僅限於故障和正常傳送結束
DMA 控制器
- DMAC,又叫 DMA 控制器(DMA 接口),是對數據傳送過程進行控制的硬件

- 單總線結構
在 DMA 過程中,DMAC 將接管 CPU 的地址總線、數據總線和控制總線,CPU 的主存控制信號被禁用
DMAC 的組成:
- 主存地址計數器:存放要交換數據的主存地址
- 傳送長度計數器:記錄傳送數據的長度(總字數)。每傳送一個字,計數器就減 1,直至計數器為 0,表示該批數據傳送完畢
- 數據緩衝寄存器:暫存每次傳送的數據【DMA 接口與主存之間的傳送單位為字,DMA 與設備之間的傳送單位可能為字節或位】
- DMA 請求觸發器:每當 I/O 設備準備好數據後,給出一個控制信號,使 DMA 請求觸發器置位
- “控制/狀態”邏輯:由控制和時序電路及狀態標誌組成,用於指定傳送方向,修改傳送參數,並對 DMA 請求信號、CPU 響應信號進行協調和同步
- 中斷機構:當一個數據塊傳送完畢後觸發中斷機構,向 CPU 提出中斷請求
DMA 過程:
- 接收外設發出的 DMA 請求,並向 CPU 發出總線請求
- CPU 響應此總線請求,發出總線響應信號,接管總線控制權,進入 DMA 操作週期
- 確定傳送數據的主存單元地址及長度,並自動修改主存地址計數和傳送長度計數
- 規定數據在主存和外設間的傳送方向,發出讀寫等控制信號,執行數據傳送操作
- 向 CPU 報告 DMA 操作結束
7.2.4 DMA 方式
前文講 DMAC 時,使用的是單總線的圖,但是 DMA 方式一般是指三總線的結構。

在外設與主存之間開闢一條直接數據通路,DMA總線。
DMA 方式的特點:
- 主存既可以被 CPU 訪問,也可被外設訪問
- 在數據塊傳送時,主存地址的確定、傳送數據等都由硬件直接實現
- 主存中要開闢專用緩衝區,及時供給和接收外設的數據
- DMA 傳送速度快,CPU 和外設並行工作,提高了系統效率
- DMA 在傳送開始前要通過程序進行預處理,結束後要通過中斷方式進行後處理
在三總線結構中,IO設備和 CPU 同時訪問主存時,可能發生衝突。
故,DMAC 與 CPU 採用以下三種方式訪問主存:
- 停止 CPU 訪問
- 當 I/O 設備有 DMA 請求時,由 DMA 接口向 CPU 發送一個停止信號,使 CPU 放棄總線控制權,停止訪問主存,直到 DMA 傳送一塊數據結束
- 優點:控制簡單,適用於數據傳輸速率很高的 I/O 設備實現成組數據的傳送
- 缺點:DMA 訪問主存時,CPU 基本上處於不工作狀態
- DMA 與 CPU 交替訪問
- 將 CPU 的工作週期分成兩個時間片,一個給 CPU 訪存,另一個給 DMA 訪存,這樣在每個週期內,CPU 和 DMA 就都可以輪流訪存
- 總線使用權分時控制
- 優點:不需要申請、建立和歸還總線控制權,具有很高的傳送速率
- 缺點:相應的硬件邏輯變得更復雜
- 週期挪用(週期竊取)
- 規定 IO 訪存的優先級高於 CPU 訪存,IO設備需要訪存時,直接挪用一個存取週期,傳送完一個數據字後立即釋放總線(單字傳送方式)
- I/O 設備有 DMA 請求時,會遇到 3 種情況:
- 此時 CPU 不訪存
- CPU 正在訪存,待存取週期結束後,CPU 再將總線佔有權讓出
- I/O 和 CPU 同時請求訪存,CPU 要暫時放棄總線佔有權
- 優點:既實現了 I/O 傳送,又較好地發揮了主存與 CPU 的效率
- 缺點:每挪用一個主存週期,DMA 接口都要申請、建立和歸還總線控制權
DMA 與 中斷 對比

8 考綱
考察目標
- 理解單處理器計算機系統中主要部件的工作原理、組成結構以及相互連接方式。
- 掌握指令集體系結構的基本知識和基本實現方法,對計算機硬件相關問題進行分析,並能夠對相關部件進行設計。
- 理解計算機系統的整機概念,能夠綜合運用計算機組成的基本原理和基本方法,對高級編程語言(C語言)程序中的相關問題進行分析,具備軟硬件協同分析和設計能力。
考察內容
第一章 計算機系統概述
(一) 計算機系統層次結構
- 計算機系統的基本組成
- 計算機硬件的基本結構
- 計算機軟件和硬件的關係
- 計算機系統的工作原理
"存儲程序"工作方式
高級語言程序與機器語言程序之間的轉換
程序和指令的執行過程。
(二) 計算機性能指標
- 吞吐量、響應時間
- CPU時鐘週期、主頻、CPI、CPU執行時間
- MIPS、MFLOPS、GFLOPS、TFLOPS、PFLOPS、EFLOPS、ZFLOPS
第二章 數據的表示和運算
(一) 數制與編碼
- 進位計數制及其數據之間的相互轉換
- 定點數的編碼表示
(二) 運算方法和運算電路
基本運算部件:加法器,算術邏輯部件(ALU) 、加/減運算:補碼加/減運算器,標誌位的生成、乘/除運算:乘/除法運算的基本原理,乘法電路和除法電路的基本結構
(三) 整數的表示和運算
- 無符號整數的表示和運算
- 帶符號整數的表示和運算
(四) 浮點數的表示和運算
- 浮點數的表示:IEEE 754標準
- 浮點數的加/減運算
第三章 存儲器層次結構
(一) 存儲器的分類
(二) 層次化存儲器的基本結構
(三) 半導體隨機存取存儲器
(四) 主存儲器
- DRAM芯片和內存條
- 多模塊存儲器
- 主存和CPU之間的連接
(五) 外部存儲器
- 磁盤存儲器
- 固態硬盤(SSD)
(六) 高速緩衝存儲器(Cache)
- Cache的基本原理
- Cache和主存之間的映射方式
- Cache中主存塊的替換算法
- Cache寫策略
(七) 虛擬存儲器
第四章 指令系統
(一) 指令系統的基本概念
(二) 指令格式
(三) 尋址方式
(四) 數據的對齊和大/小端存放方式
(五) CISC和RISC的基本概念
(六) 高級語言程序與機器級代碼之間的對應
- 編譯器,彙編器和鏈路器的基本概念
- 選擇結構語句的機器級表示
- 循環結構語句的機器級表示
- 過程(函數) 調用對應的機器級表示
第五章 中央處理器
(一) CPU的功能和基本結構
(二) 指令執行過程
(三) 數據通路的功能和基本結構
(四) 控制器的功能和工作原理
(五) 異常和中斷機制
- 異常和中斷的基本概念
- 異常和中斷的分類
- 異常和中斷的檢測與響應
(六) 指令流水線
- 指令流水線的基本概念
- 指令流水線的基本實現
- 結構冒險、數據冒險和控制冒險的處理
- 超標量和動態流水線的基本概念
(七) 多處理器基本概念
- SISDLSIMD、MIMD、向量處理器的基本概念
- 硬件多線程的基本概念
- 多核處理器(multi-core) 的基本概念
- 共享內存多處理器(SMP) 的基本概念
第六章 總線
(一) 總線
- 總線的基本概念
- 總線的組成及性能指標
- 總線事務和定時
(二) I/O接口(I/O控制器)
(三) I/O方式
DMA控制器的組成
DMA傳送過程
9 REF
- 王道書、網課
- 計組很詳細,我結合網課ppt做了補充:GitHub - LYuYang61/408: 計算機考研408筆記
- Site Unreachable

On this page
- 1 計算機系統概述
- 1.1 計算機硬件
- 1.1.1 馮·諾伊曼機
- 1.1.2 現代計算機
- 1.2 硬件工作原理
- 1.2.1 主存儲器
- 1.2.2 運算器
- 1.2.3 控制器
- 1.2.4 硬件工作過程
- 1.3 計算機軟件
- 1.3.1 兩類軟件
- 1.3.2 三個級別的語言
- 1.3.3 軟件和硬件的邏輯功能等價性
- 1.3.4 指令集體系結構 (ISA)
- 1.3.5 計算機系統的層次結構
- 1.3.6 工作原理
- 1.4 性能指標
- 1.4.1 存儲器性能指標
- 字長概念辨析
- 1.4.2 CPU性能指標
- 1.4.3 系統整體性能指標
- 辨析
- 2 數據的表示和運算
- 2.1 數制與編碼
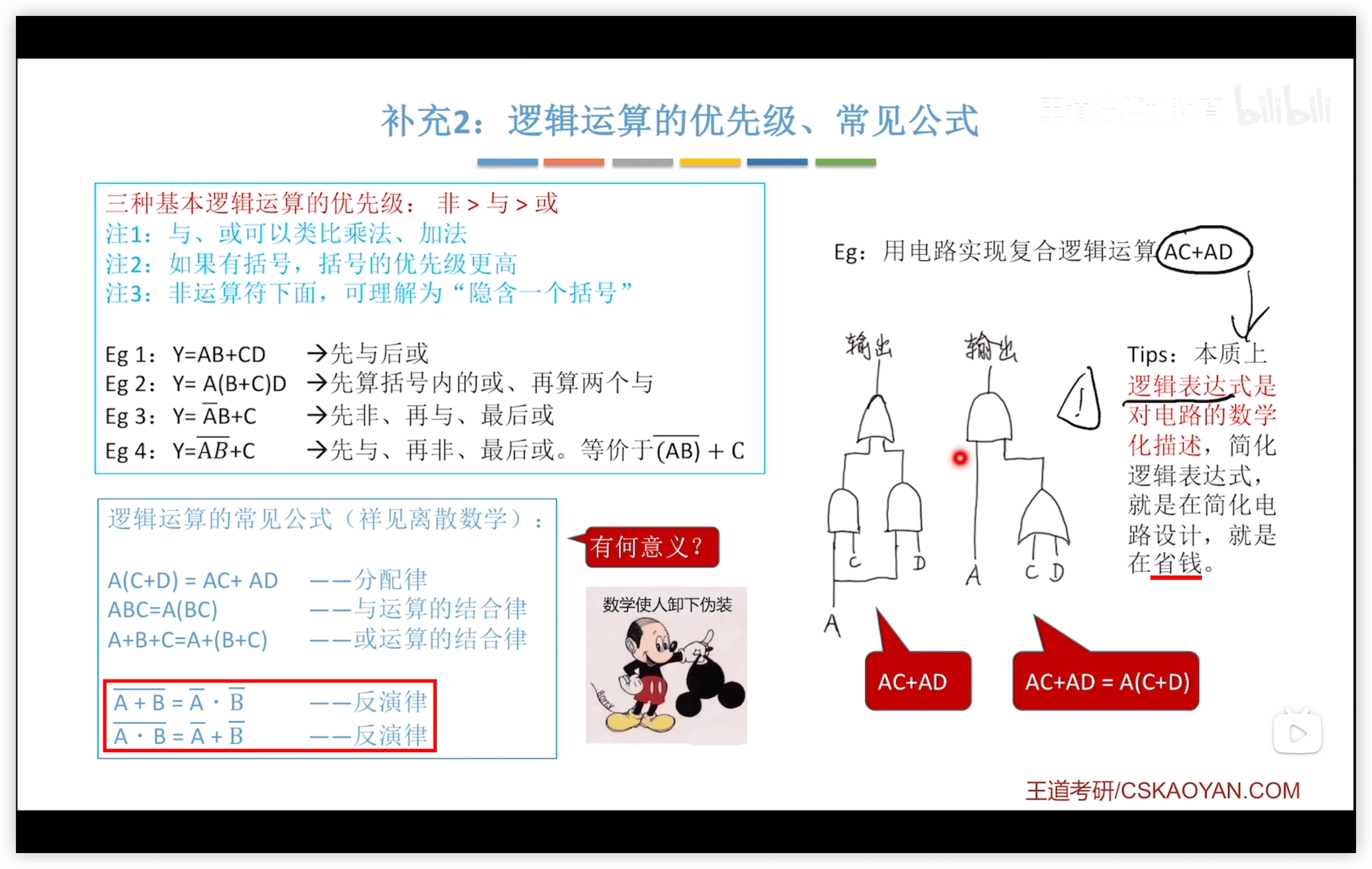
- 2.1.1 進位計數制
- 2.1.2 進制轉換
- 2.1.2.1 轉十進制
- 二八六轉換
- 十進制轉換
- 2.1.3 真值 機器數
- 2.1.4 定點數
- 有符號數的定點表示
- 原碼
- 反碼
- 補碼
- 移碼
- 2.1.5 語言強制轉換
- 零擴展 符號擴展
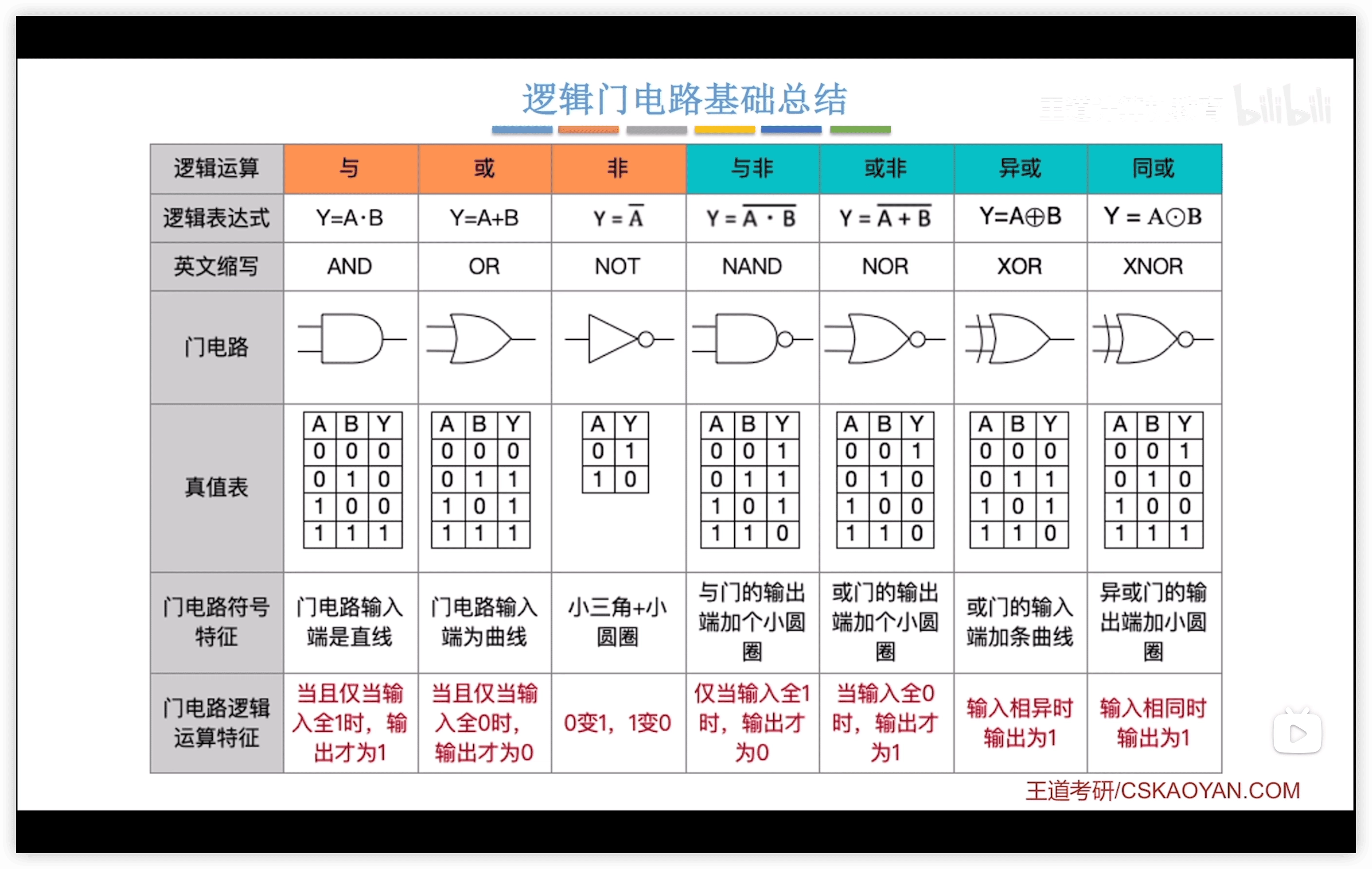
- 2.1.6 邏輯門電路基礎
- 2.1.6.1 邏輯門
- 公式
- 多路選擇器
- 三態門
- 2.2 運算方法和運算電路
- 2.2.1 加法器
- 串行進位加法器
- 術語辨析
- 並行進位加法器
- 帶標誌位的加法器
- 2.2.2 算數邏輯單元 ALU
- 功能
- 2.2.3 定點數的移位
- 邏輯移位
- 算數移位
- 2.2.4 定點數的加減
- 原碼加減
- 補碼加減
- 模4 和 模2 補碼
- 2.2.5 無符號數的加減
- 溢出判斷
- 2.2.6 補碼加減運算電路
- 2.2.7 無符號整數的乘法
- 電路
- 2.2.8 有符號整數的乘法
- 2.2.9 計算機實現乘法電路的三種方式
- 兩位乘法
- 陣列乘法器
- 邏輯運算等效
- 總結
- 2.2.10 無符號整數的除法運算
- 手算
- 除法電路
- 商溢出
- 2.3 浮點數
- 2.3.1 IEEE 754
- float 的存儲
- double 的存儲
- 例題
- 2.3.2 浮點數表示範圍
- 特殊狀態的浮點數
- 規格化浮點數
- 下溢處理
- 非規格化浮點數
- 2.3.3 浮點數加減運算
- 對階
- 規格化
- 舍入
- 溢出判斷
- 2.3.4 數據存儲和排列
- 2.4 補充:C語言
- 3 存儲系統
- 3.1 存儲器概述
- 3.1.1 存取方式
- 3.1.2 性能指標
- 3.2 主存儲器
- 3.2.1 半導體原理
- 3.2.2 存儲器芯片原理
- 3.2.3 尋址
- 3.2.4 DRAM 與 SRAM
- DRAM 芯片的行列計算
- DRAM 刷新
- SDRAM
- 行緩衝寄存器
- 3.2.5 ROM
- 3.2.6 雙端口 RAM
- 3.2.7 多模塊存儲器
- 多體並行存儲器
- 單體多字存儲器
- 3.3 主存儲器與CPU的連接
- 3.3.1 位擴展
- 3.3.2 字擴展
- 3.3.3 字位同時擴展
- 3.4 外部存儲器
- 3.4.1 磁盤的組成
- 3.4.2 磁盤的性能指標
- 3.4.2.1 磁盤的容量
- 記錄密度
- 平均存取時間
- 數據傳輸率
- 3.4.3 磁盤地址
- 3.4.4 磁盤工作過程
- 改進:磁盤陣列
- 3.4.5 固態硬盤
- 3.5 高速緩衝存儲器 Cache
- 3.5.1 Cache 基本原理
- 局部性原理
- 性能分析
- 按塊交換
- Cache 行
- 3.5.2 Cache 與主存的映射
- 全相聯映射
- 直接映射
- 組相聯映射
- 3.5.3 Cache 替換算法
- 3.5.4 Cache 寫策略
- 寫命中
- 寫未命中
- 3.5.5 其他
- 3.5.5.1 多級 Cache
- Cache 比較器
- 3.6 虛擬存儲器
- 3.6.1 頁式虛擬存儲器
- 快表 TLB
- 4 指令系統
- 4.1 指令基礎
- 4.1.1 ISA
- 4.1.2 指令基本格式
- 按地址碼分類
- 按指令長度分類
- 按操作碼長度分類
- 擴展操作碼指令格式
- 按操作類型分類
- 4.1.3 擴展操作碼
- 4.2 尋址方式
- 4.2.1 指令尋址
- 4.2.1.1 PC
- 順序 跳躍
- 4.2.2 數據尋址
- 地址碼的組成
- 直接尋址
- 間接尋址
- 寄存器尋址
- 寄存器間接尋址
- 隱含尋址
- 立即尋址
- 基址尋址
- 變址尋址
- 相對尋址
- 堆棧尋址
- 總結
- 4.2.3 補充:硬件的比較跳轉
- 4.3 機器代碼
- 4.3.1 數據傳送類
- 4.3.2 算術運算類
- 4.3.3 邏輯運算類
- 4.3.4 移位/循環移位類
- 4.3.5 轉移控制類
- 4.3.5.1 無條件轉移
- 條件轉移(重點)
- 4.3.6 子程序調用與返回
- 4.3.7 棧幀內部詳解
- 4.3.8 其他
- 4.3.9 補充 AT&T 格式
- 4.4 CISC 和 RISC
- 4.4.1 複雜指令系統計算機(CISC)
- 4.4.2 精簡指令系統計算機(RISC)
- 5 中央處理器 CPU
- 5.1 CPU概述
- 5.1.1 CPU 的功能
- 5.1.2 CPU 的基本結構
- 5.1.3 CPU 寄存器
- 5.1.4 運算器
- 運算器組成
- 5.1.5 控制器
- 控制器組成
- 5.1.6 數據通路概述
- 專用數據通路方式
- CPU 內部單總線方式
- 5.2 指令執行
- 5.2.1 指令週期
- 週期概念辨析
- 指令週期流程
- 5.2.2 指令週期的數據流
- 取指週期
- 間址週期
- 執行週期
- 中斷週期
- 5.2.3 指令的執行方案
- 5.2.3.1 單週期處理器
- 多週期處理器
- 流水線處理器
- 5.3 數據通路
- 5.3.1 數據通路的基本結構
- 5.3.1.1 單總線結構
- 多總線結構
- 專用數據通路
- 5.3.2 單總線
- 單總線分析題
- 5.3.3 專用數據通路
- 5.4 控制器
- 5.4.1 硬佈線控制器
- 5.4.2 微程序控制器
- 概念辨析
- 微程序控制器的結構
- 微程序控制單元設計
- 微程序 對比 硬佈線
- 5.4.3 微指令
- 5.4.3.1 格式
- 編碼方式
- 地址形成方式
- 5.5 異常和中斷
- 5.5.1 概念
- 5.5.2 異常分類
- 5.5.3 中斷分類
- 5.5.4 響應過程
- 5.6 指令流水線
- 5.6.1 基本概念
- 指令流水線的定義
- 提高並行性
- 指令集應具備的特點
- 三種基本方式
- 5.6.2 性能指標
- 5.6.2.1 吞吐率
- 加速比
- 效率
- 5.6.3 五段式
- 例題
- 5.6.4 冒險
- 5.6.5 分類
- 5.6.6 高級流水線
- 5.6.6.1 超標量
- 超長指令字
- 超流水線
- 5.7 多處理器
- 5.7.1 基本概念
- 5.7.2 SISD
- 5.7.3 SIMD
- 5.7.4 MISD
- 5.7.5 MIMD
- 5.7.6 多核處理器
- 5.8 硬件多線程
- 5.8.1 細粒度多線程
- 5.8.2 粗粒度多線程
- 5.8.3 同時多線程(SMT)
- 6 總線
- 6.1 概述
- 6.2 分類
- 6.2.1 按數據傳輸方式
- 6.2.2 按功能
- 6.2.3 按時序控制
- 6.3 系統總線的結構
- 6.3.1.1 單總線結構
- 雙總線結構
- 三總線結構
- 四總線結構
- 6.3.2 性能指標
- 6.3.3 常見的總線標準
- 6.4 事務和定時
- 6.4.1 總線事務
- 6.4.2 總線定時
- 同步定時方式
- 適用場景
- 異步定時方式
- 適用場景
- 分類
- 半同步定時方式
- 分離式定時方式
- 7 IO系統
- 7.1 IO接口
- 7.1.1 控制方式
- 7.1.2 功能
- 7.1.3 基本結構
- 7.1.4 IO端口及其編址
- 統一編址
- 獨立編址
- 7.2 IO方式
- 7.2.1 程序查詢方式
- 7.2.2 程序中斷方式
- 中斷技術簡介
- 中斷請求
- 中斷判優
- 中斷響應
- 中斷識別
- 中斷服務程序
- 整個中斷處理過程
- 多重中斷
- 程序中斷總結
- 7.2.3 DMA 方式
- DMA 控制器
- 7.2.4 DMA 方式
- DMA 與 中斷 對比
- 8 考綱
- 9 REF