
- paper: 1707.06347
- Proximal Policy Optimization Algorithms 近端策略優化算法
“近端 proximal” 主要體現在對策略更新幅度的限制,保證新策略和舊策略之間較為 “接近”,這是算法的核心特性。
簡介
近端策略優化(PPO)算法旨在結合信任區域策略優化(TRPO)的數據效率和可靠性能,同時使用更簡單的一階優化方法。
其核心在於提出了一個帶有裁剪概率比(clipped probability ratios)的目標函數,以此對策略性能進行悲觀估計(pessimistic estimate i.e. lower bound)。
傳統策略優化
論文中提到了以下兩種傳統策略優化作為 background:
- 在標準策略梯度方法中,目標是最大化策略梯度估計器對應的目標函數
- 是隨機策略,是優勢函數在時刻的估計值。
- 在信任區域策略優化(TRPO)中,TRPO 會最大化一個替代目標函數 ,
- 表示概率比率
- 是優勢函數估計值
然而,如果沒有約束條件,對進行最大化會導致策略更新幅度過大,影響學習的穩定性。
原理
Clipped Surrogate Objective
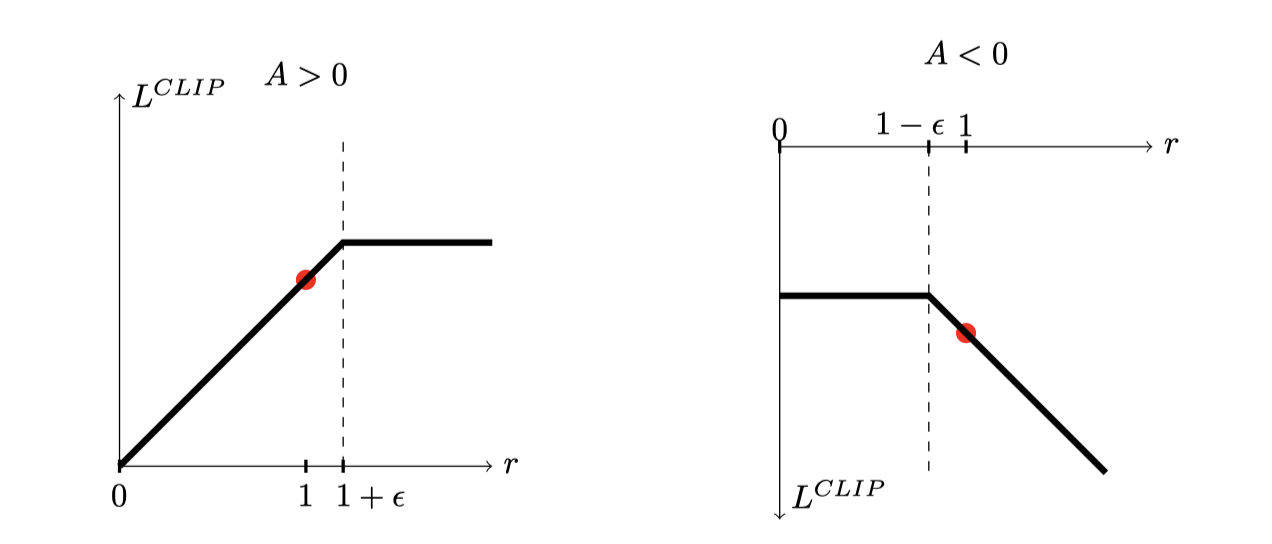
Clipped Surrogate Objective(裁剪替代目標函數)是 PPO 算法中的關鍵概念,旨在改進傳統策略優化中可能出現的策略更新幅度過大的問題,使策略學習更加穩定和有效。
PPO提出的裁剪替代目標函數為
- 是超參數,常取
重點在於裁剪函數 ,它將概率比率 限制在 區間內 - 如果 超出區間端點,則裁剪為duan端點;在區間內則保持不變
的 min 函數中:
- 參數一是 TRPO 中的目標函數
- 參數二是代入裁剪過的概率比率的目標函數
取兩者最小值,使得 成為未裁剪目標函數 的下限,即文中提到的 pessimistic 的界限。
Adaptive KL Penalty Coefficient
除了裁剪概率比率,PPO 還提出了另一種方法,自適應 KL 散度懲罰係數,其目標函數為:
- 是一個係數,需要動態調整
- 是新舊策略在狀態下的KL散度
通過在目標函數中加入KL散度懲罰項,限制策略更新的幅度。
實現
PPO算法的具體實現步驟如下:
- 數據採樣:使用當前策略與環境進行交互,收集一批軌跡數據,其中是狀態,是動作,是獎勵。
- 優勢估計:計算每個時間步的優勢函數估計值。常見的方法有廣義優勢估計(Generalized Advantage Estimation,GAE)等。
- 目標函數優化:根據選定的目標函數(如或),使用隨機梯度上升算法對策略參數進行多輪次(多個epoch)的小batch更新。例如,對於PPO中的CLIP方法,通過最大化來更新。
- 參數更新:在完成對採樣數據的多輪優化後,更新策略參數,並重覆上述步驟進行下一輪的採樣和優化。
優勢
PPO算法具有以下顯著優勢:
- 實現簡單:相較於TRPO,PPO無需複雜的二階優化方法(如共軛梯度算法),僅使用一階優化(如隨機梯度上升),降低了實現難度和計算複雜度。
- 數據效率高:通過 clipped 或 KL散度懲罰項 的方法,PPO能夠在有限的樣本數據上進行有效的策略更新,避免了策略更新幅度過大導致的性能波動,提高了數據的利用效率。
- 通用性強:PPO適用於各種不同的強化學習任務,包括連續控制任務和離散動作空間任務(如Atari遊戲)。在實驗中,它在多個基準任務上表現出色,能夠在不同的環境中取得較好的性能。
- 樣本複雜度低:與其他在線策略梯度方法相比,PPO在較少的樣本數量下就能達到較好的性能,減少了與環境交互的次數,從而節省了訓練時間和資源。

← Previous post國內訪問 Vercel 部署應用
Next post →Overleaf的引用及參考文獻